Hadoop NameNode 이중화 시 fencing의 역할

Bigdata 시스템을 구축한 대부분의 회사나 조직에서는 Hadoop 중 파일 시스템에 해당하는 HDFS(Hadoop Distributed File System) 를 기본 데이터 저장소로 활용하고 있습니다. HDFS는 Bigdata 시스템의 가장 기초부분이라고 할 수 있습니다. 이런 시스템이 장애라도 발생하면 모든 분석 업무가 중단될 가능성이 많습니다. HDFS에 저장된 데이터의 규모도 엄청 크기 때문에 HDFS 클러스터 자체를 이중화 하는것도 쉽게 결정하기 어려울 것입니다. 따라서 HDFS 클러스터 자체의 안정성이 중요한데 HDFS에 저장된 파일의 안정성에 대해서는 두말할 필요 없이 안정적이라고 할 수 있습니다. 2006년 Hadoop이 출시된 이후부터 지금까지 가장 골치아픈 부분이 바로 NameNode에 대한 부분입니다.
두 가지 측면에서 NameNode의 안정성이 중요합니다. 첫번째는 Durability 입니다. NameNode에서 관리하는 정보는 파일 시스템 전체 정보라고 할 수 있는 inode 입니다. inode 에는 파일 시스템의 디렉토리 구조와 파일의 각 블럭에 대한 정보가 저장되어 있습니다. 이 inode 정보가 잘못되거나 유실되면 클러스터가 수천대로 구성되어 있다하더라도 수천대에 저장되어 있는 파일은 아무런 쓸모가 없이 공간만 차지하고 있는 파일이 됩니다. 두번째는 Availability 입니다. 수천대로 구성된 클러스터라 하더라도 NameNode 한대에 문제가 발생하면 클러스터 전체는 동작하지 않는 것과 동일하게 됩니다.
이 두가지 이슈에 대한 개선이 곧 NameNode의 변천사라고 할 수 있습니다. 그리고 두가지 이슈가 분리되어 있는 것 같지만 서로 밀접한 관계를 가지고 있습니다. 먼저 Durability 측면을 먼저 살펴 보겠습니다.
NameNode 관리 정보의 Durability
NameNode에는 크게 두가지 정보가 저장됩니다. 하나는 현재의 파일 구조 자체에 대한 정보인 fsimage 정보입니다. 나머지 하나는 특정 시점에 구성된 fsimage snapshot 이후로 발생된 변경 사항에 대한 edits log 입니다. 이 두가지 정보 중 fsimage는 현재 시점에서의 최신 정보는 NameNode의 메모리 로딩되어 있으며, 특정 시점의 snapshot는 NameNode에 mount 되는 디스크에 파일 형태로 저장되어 있습니다. Edits log도 fsimage snapshot과 같이 NameNode의 디스크에 파일 형태로 저장됩니다. 이 두 종류의 파일은 어떠한 경우에도 안정성을 보장 받아야 합니다. 하지만 x86 장비의 디스크는 고가용성 디스크보다는 주로 PC 급에서 사용되는 디스크를 많이 사용합니다. 이런 디스크에 이처럼 중요한 정보를 저장해야 하기 때문에 몇가지 부가적인 방안을 마련해야 합니다. 주로 다음과 같은 구성으로 이 파일들의 안정성을 확보합니다.
- NameNode의 fsimage, edits log를 저장하는 디스크는 Raid Mirroring 구성
- 보통 HDFS를 구성할 때 Raid 구성을 잘 하지 않습니다. 이유는 HDFS에 저장되닌 파일들이 네트워크로 Mirroring 된 구성이기 때문에 Raid 없이도 안정적으로 파일을 저장할 수 있습니다(성능에 대한 논의는 이 글의 주제가 아님).
- 하지만 NameNode의 경우 필자는 반드시 Raid 구성을 하라고 제안합니다. 이유는 이 두 파일을 안정적으로 저장해야 하기 때문입니다.
- fsimage, edits log는 한개 이상의 디렉토리에 저장
- NameNode 이 두 종류의 파일을 여러개의 디렉토리에 저장하는 기능을 가지고 있습니다. hdfs-site.xml의 "dfs.namenode.name.dir" 이 설정 값으로 저장 디렉토리를 지정할 수 있는데 이 proeprty의 설명은 다음과 같이 되어 있습니다.
- Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy.
- "," 로 구분되게 여러 디렉토리를 지정할 수 있습니다.
- NameNode는 파일에 레코드를 저장할 때 여기서 설정된 모든 디렉토리의 파일에 저장해야만 해당 작업을 완료시킵니다. 즉, synchronous 방식으로 처리합니다. 저장 도중 특정 디렉토리에 문제가 발생하면 해당 디렉토리는 제외하고 저장합니다. 2014년 버전에서는 문제가 발생한 디스크가 복구 되더라도 한번 문제가 발생하면 그 디렉토리는 사용하지 않습니다. 최근에는 어떻게 변경되었는지 확인을 하지 못했습니다.
- edits log 저장 디렉토리는 "dfs.namenode.edits.dir" 설정 값으로 따로 지정할 수 있지만 지정하지 않으면 "dfs.namenode.name.dir" 값을 사용합니다.
- 이 디렉토리에 대한 상태 정보는 HDFS Web 관리 UI(http://<namenode>:50070) 에서 다음 그림과 같이 확인 가능합니다.
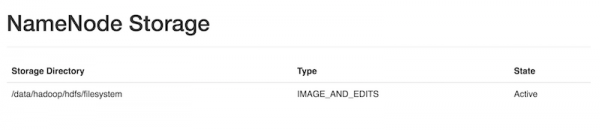
위 구성 중 일부는 Availability 를 보장하도록 클러스터를 구성하면 필요 없는 항목이 있습니다. 하지만 안정적으로 저장하기 위한 기본 전략은 수립해야 하기 때문에 위와 같은 구성을 하는 것을 추천합니다.
NameNode의 이중화 구성(Availability)
일반적으로 Master 성격의 서버의 이중화 구성은 두대의 서버로 구성을 하고 하나의 서버가 실제 기능을 수행하는 Active Server 역할을 수행하고, 나머지 서버는 기능을 수행하지 않지만 Active Server 장애 시 자동으로 Active Server의 역할을 수행하는 Standby Server 기능을 수행합니다. NameNode의 이중화 구성도 이와 동일한 방법으로 구성되어 있습니다. 하지만 NameNode의 이중화 구성은 다음과 같은 이유 때문에 쉽게 해결할 수 있는 문제는 아닙니다.
- Active Server 장애 시점에 Standby Server에 Active Server와 동일한 fsimage, edits logs 정보가 존재해야 한다. 일반적인 구성에서 이 정보는 Active Server에만 있기 때문에 서버 장애 시 어떻게 Standby Server가 이 정보를 가져올 것인가 하는 것이 주요 쟁점이 된다.
- Active Server 장애 발생 시 Standby Server는 장애를 어떻게 찾아내고 두개의 서버가 동시에 Active Server인 상태가 발생하는 것을 어떻게 방지할 것인가에 대한 사항이다.
이 두가지 이슈로 인해 많은 변화를 겪으면서 지금의 구성이 되었습니다. 따라서 각 문서별로 이중화에 대한 설명, 구성 등이 다른 이유도 여기에 있습니다. 현재 많이 정식 버전이 2.7.x 버전에서는 이 두가지 항목에 대해 몇가지 옵션을 이용하여 다른 구성을 할 수 있습니다.
- 스토리지 구성 방법
- NAS와 같은 Shared Storage를 이용하는 방법
- Journal Node를 이용하는 방법
- Failover 처리 방법
- 수동 장애 인지 방법
- ZooKeeper를 이용한 자동 장애 인지 방법
가장 막강한 구성은 Journal Node와 ZooKeeper를 이용한 자동 장애 인지 방법을 사용하는 것이며 가장 많이 사용하는 방법이기도 합니다. 이글은 fencing의 역할이 무엇인지를 알아보기 위한 글이기 때문에 각 구성에 대해 간단하게 살펴 보겠습니다.
Shared Storage를 사용하는 경우
Active Server와 Standby Server 사이에 fsimage와 edits logs 파일을 공유하는 가장 쉬운 방법은 NAS와 같은 Shared Storage를 이용하는 방법입니다. 앞에서 설명한 것처럼 NameNode는 이들 정보를 여러 디렉토리에 저장하는 기능을 제공하는데 이 기능을 이용해서 저장소 중 하나를 Shared Storage로 지정할 수 있습니다.
이렇게 하면 스토리지 문제는 간단하게 해결할 수 있지만 두 서버가 동시에 Active Server가 되어 Shared Storage의 데이터를 각각 수정하게 되면 NameNode의 중요 정보가 crash 되게 됩니다. 이런 상태를 분산환경에서는 Split Brain 이라고 말하는데 주로 서버 자체의 문제가 아닌 두 서버 사이의 네트워크 문제가 발생하거나 CPU 과부하 상황인 경우 많이 발생하게 됩니다.
수동으로 장애를 인지하여 Active Server, Standby Server의 역할을 바꾸는 방법은 주로 OS 보안 패치, 하드웨어 업그레이드 등과 같이 정기적인 점검인 경우만 가능하며, 예상하지 못한 장애 상황에서는 대응하기 어렵습니다. 따라서 대부분은 자동으로 장애를 인지하는 방법을 사용하고 있는데 다음과 같이 ZooKeeper를 이용합니다.

(이미지: https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability/)
이때 Standby Server가 Active Server가 되면서 기존의 Active Server가 계속해서 살아 있는 상태를 방지하기 위해(즉 Split Brain 상태를 방지하기 위해) 기존 Active Server를 kill 시키는 작업을 해야 하는데 dfs.ha.fencing.methods 설정이 기존 Active Server를 kill 시키는 방법을 지정하는 옵션입니다. Standby Server는 Active Server 로 전환되면서 이 옵션에 설정된 값을 이용하여 해당 명령을 실행 시켜 Active Server를 kill 시키거나 Shared Storage를 unmount 시킵니다. sshfence의 경우 다음 명령을 사용하여 NameNode를 kill 시킵니다.
- fuser -v -k -n tcp <namenode port>
이렇게 ZooKeeper를 이용하여 자동으로 장애 상황을 확인하여 fencing 처리할 경우에도 의문점이 있습니다. 기존 Active Server에 문제가 발생하여 fencing 처리를 해야 하는 경우 대략 다음과 같은 세가지 상황인 경우일 것입니다.
- 네트워크 장애
- 물리적 서버 자체 장애
- NameNode 부하 상황이나 예상하지 못한 오류
2번의 경우 물리적 서버 자체 장애이기 때문에 NameNode도 자동으로 shutdown 되었다고 볼 수 있습니다. 3번의 경우 fencing 작업에 의해 NameNode를 kill 할 수 있어 원래 fencing에서 의도 했던 대로 처리가 가능합니다. 문제는 1번 상황입니다. 네트워크 장애 상황은 다양한 패턴을으로 나타납니다. 기존 Active NameNode 가 ZooKeeper와 Standby NameNode로만 통신이 되지 않고, ShardStorage와 통신이 되는 상황이 있을 수 있습니다. 이런 경우 Standby NameNode에서 fencing 처리는 네트워크 단절로 인해 수행할 수 없습니다. 하지만 기존 Active NameNode 는 여전히 Live한 상태가 됩니다.
따라서, Share Storage를 이용하여 fsimage, edits 파일을 공유하는 방식으로 NameNode를 이중화 구성하는 것은 안정적으로 failover 처리를 하기 위해서는 한계가 있기 때문에 잘 사용하지 않는 방법입니다. 이런 문제점을 해결하기 위해 Hadoop 에서는 JournalNode를 제공하고 있습니다.
JournalNode를 이용하는 경우
최근 Hadoop을 설치하고 이중화 구성을 하면 대부분은 JournalNode를 이용한 이중화 구성을 합니다.
JournalNode는 edits 정보(즉, 파일 시스템의 journaling 정보)를 저장하고 공유하는 기능을 수행하는 서버입니다. JournalNode에 저장되는 데이터는 아주 중요한 데이터이기 때문에 하나의 서버로 구성되지 않고 3대의 서버로 구성됩니다. 이렇게 분산 구성을 할 경우 JournalNode 자체도 SplitBrain 상황이 발생할 수 있는데 이 문제는 JournalNode 자체에서 해결하고 있습니다. 이런 SplitBrain 상황을 회피하는 용도로 주로 ZooKeeper를 많이 사용합니다. JournalNode는 자체적으로 SplitBrain 상황 등에 대처 가능하도록 되어 있는데 ZooKeeper 에서 사용하는 방식과 유사한 방식을 사용하고 있다고 합니다.

(이미지: https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability/)
이렇게 안정적으로 edits 정보를 저장할 수 있는 JournalNode를 구성하면 다음과 같은 절차로 failover 처리를 수행합니다.
- Active NameNode는 edit log 처리용 epoch number를 할당 받는다. 이 번호는 uniq하게 증가하는 번호로 새로 할당 받은 번호는 이전 번호보다 항상 크다.
- Active NameNode는 파일 시스템 변경 시 JournalNode로 변경 사항을 전송한다. 전송 시 epoch number를 같이 전송한다.
- JournalNode는 자신이 가지고 있는 epoch number 보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리한다.
- JournalNode는 자신이 가지고 있는 번호보다 작은 epoch number를 받으면 해당 요청은 처리하지 않는다.
- 이런 요청은 주로 SplitBrain 상황에서 발생하게 된다.
- 기존 NameNode가 정상적으로 Standby로 변하지 않았고, 이 NameNode가 정상적으로 fencing 되지 않은 상태이다.
- Standby NameNode는 주기적(1분)으로 JournalNode로 부터 이전에 받은 edit log의 txid 이후의 정보를 받아 메모리의 파일 시스템 구조에 반영
- Active NameNode 장애 발생 시 Standby NameNode는 마지막 받은 txid 이후의 모든 정보를 받아 메모리 구성에 반영 후 Active NameNode로 상태 변환
- 새로 Active NameNode가 되면 1번 항목을 처리한다.
위와 같은 방식으로 failover를 처리하기 때문에 갑작스런 장애에도 Standby NameNode가 자연스럽게 Active NameNode로 전환되고 edits log에 in-consistency 한 상황도 발생하지 않게 됩니다. 즉 fencing에 대한 처리 없이도 문제가 되지 않는 체계가 되어 있습니다.
이런 상황이라면 HDFS의 환경설정 파일인 hdfs-site.xml에 "dfs.ha.fencing.methods" 값을 설정하지 않아도 될 것 같은데 실제로 설정하지 않으면 다음과 같은 FATAL 에러 메시지가 나타납니다.
- "Fencing is not configured for..."
그리고 ZKFailoverController 데몬이 실행이 안됩니다.ZKFailoverController 데몬이 실행되지 않으면 NameNode 가 정상 동작하지 않기 때문에 반드시 기본 설정은 해야 정상동작하게 됩니다.
결론
최근에 많이 사용하는 HA 구조인 ZooKeeper와 JournalNode를 이용하는 방식에서는 fencing은 중요하지 않은 옵션이지만, 설정하지 않으면 NameNode가 스타트업 시 정상동작 하지 않기 때문에 반드시 설정을 해야 합니다.
저도 아시는 분이 "fencing" 설정이 뭐고, 그거 설정한다고 해도 ssh 접속이 안되면 문제가 있지 않냐고 깐깐하게 물어보시는 바람에 여기까지 확인하게 되었습니다.
References
이글은 다음 글을 참고하였으며, 중간에 있는 이미지도 모두 아래 글에서 가져온 이미지입니다.
https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability/