Hadoop Resource Localization 파헤치기

하둡 클러스터를 온프레미스에서 운영하면서 발생했던 ResourceLocalizationService 관련 장애 하나를 소개해 드리려고 합니다.
장애 상황을 설명해 드리기 전에, YARN 의 ResourceLocalizationService 가 어떤 역할을 하는 서비스인지 살펴보겠습니다.
YARN 애플리케이션 동작방식
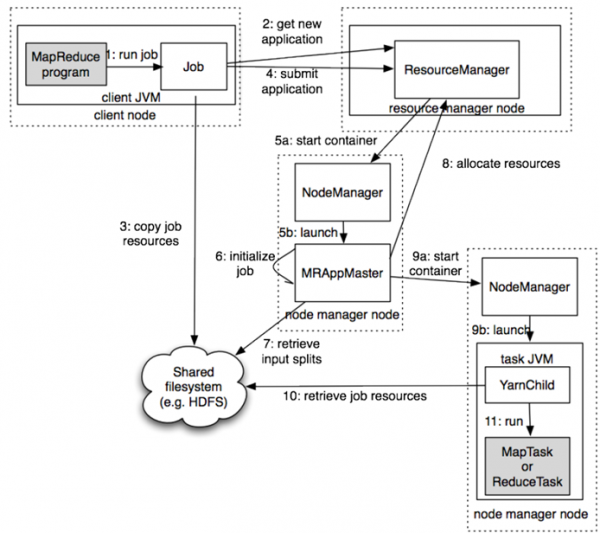
위 그림은 YARN 에서 MapReduce 애플리케이션이 동작하는 순서를 도식화 해놓은 그림입니다.
왼쪽 상단의 MapReduce program 이 하나의 Job 으로 실행되면, 전체 클러스터의 리소스를 관리하는 ResourceManager 가 전체 클러스터 노드 중에서, 제출된 Job 의 Master 역할을 하게될 ApplicationMaster 를 선정하여 구동하게 되고, 실제 데이터를 처리할 노드의 NodeManager 와 통신하여 Container 를 실행하게 됩니다.
실제 분산된 환경의 여러 노드에서 제출된 Job 을 실행하기 위해서는, 제출된 애플리케이션을 실행하기 위해 필요한 jar 파일 등을 배포하는 과정이 필요합니다.
그림에서, 3번 copy job resources 와 10번 retrieve job resource 에 해당하는 부분이며, 하둡에서는 리소스를 공유하기 위해 Hadoop Distributed File System 을 활용합니다.
Resource Localization 관련 용어정의
위 과정과 관련된 몇가지 용어들을 정의하면 아래와 같습니다.
- Localization: 원격에 있는 리소스를 실제 Task 를 수행할 노드로 복사한 후, 직접 로컬 디스크로 접속할 수 있도록 하는 것을 말합니다.
- LocalResource: LocalResource 컨테이너를 실행하는데 필요한 File / Library 를 나타냅니다. NodeManager 가 Container 를 시작하기 전에 리소스를 Localization 시킵니다. 각 LocalResource 에 대해, 애플리케이션은 다음을 구체화 할 수 있습니다.
- URL: LocalResource 를 다운로드 해야하는 원격위치
- Size: LocalResource 의 크기(bytes)
- 원격 파일시스템의 리소스에 대한 생성 timestamp 시간
- LocalResourceType: NodeManager에 의해 Localization 된 리소스 유형 (FILE, ARCHIVE 및 PATTERN)을 지정
- Pattern: 아카이브 항목을 추출하는데 사용해야하는 패턴 (PATTERN 유형인 경우만 사용).
- LocalResourceVisibility: NodeManager 에 의해 Localization 된 리소스의 가시성을 지정 (PUBLIC, PRIVATE, APPLICATION 중 하나)
- ResourceLocalizationService: 이 서비스가 Localization 을 담당하는 NodeManager 의 내부 서비스
- DeletionService: NodeManager 에서 실행되고, 지시에 따라 로컬 경로를 삭제하는 서비스
- Localizer: Localization 을 실행하는 실제 스레드 혹은 프로세스로, PUBLIC 리소스 용 PublicLocalizer 와 PRIVATE/APPLICATION 리소스 용 ContainerLocalizer 의 두가지 유형이 있음
- LocalCache: NodeManager 는 다운로드 된 모든 파일의 서버 로컬 캐시를 유지하고 관리함, 리소스는 해당 파일을 복사하는 동안 원래 사용된 원격 url 을 기반으로 고유 식별을 함
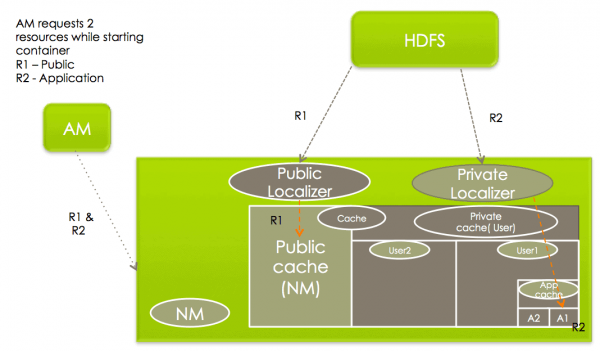
Localization of PUBLIC resources
PUBLIC 리소스의 Localization 은 NodeManager 의 PublicLocalizer 라고 불리는 스레드풀에서 처리됩니다. 또한, yarn.nodemanager.localizer.fetch.thread-count 속성에 설정된 설정값 만큼 병렬로 Localization 을 실행 할 수 있습니다. 이 설정은 Queue 로 관리되며 기본값이 4 입니다.
PUBLIC 리소스를 지역화하는 동안 localizer는 원격 파일 시스템에 대한 권한을 확인하여 요청 된 모든 리소스가 실제로 PUBLIC인지 확인하며, 해당 조건에 맞지 않는 LocalResource는 현지화가 거부됩니다.
각 PublicLocalizer는 ContainerLaunchContext의 일부로 전달 된 자격 증명을 사용하여 원격 파일 시스템에서 리소스를 안전하게 복사하게 됩니다.
PRIVATE / APPLICATION resources 의 다운로드 상세 내용은 트러블 슈팅과정의 설명에 있어 필요하지 않은 내용들이 많아 자세한 설명은 생략하도록 하겠습니다.
LocalResource 의 Target Locations
각 NodeManager 서버에서, LocalResources 는 최종적으로 아래 디렉토리에 저장됩니다.
- PUBLIC:
<local-dir>/filecache - PRIVATE:
<local-dir>/usercache//filecache - APPLICATION:
<local-dir>/usercache//appcache/<app-id>/
Resource Localization 을 위한 주요 Configuration
아래는 Resource Localization 과 관련된 주요 설정들이며, yarn-site.xml 의 설정을 통해 변경/관리 할 수 있습니다.
- yarn.nodemanager.local-dirs: 지역화하는 동안 파일 복사에 사용하도록 구성 할 수있는 쉼표로 구분 된 로컬 디렉토리 목록입니다.
- yarn.nodemanager.local-cache.max-files-per-directory: 각 지역화 디렉토리에서 지역화 될 최대 파일 수를 제한합니다 (PUBLIC / PRIVATE / APPLICATION 리소스에 대해 별도로). 기본값은 8192이며 일반적으로 큰 값을 할당해서는 안됩니다 (예 : ext3와 같은 기본 파일 시스템의 디렉토리 당 최대 파일 제한보다 충분히 작은 값을 구성).
- yarn.nodemanager.localizer.address: ResourceLocalizationService가 다양한 로컬 라이저를 수신하는 네트워크 주소입니다.
- yarn.nodemanager.localizer.client.thread-count: Localizer의 지역화 요청을 처리하는 데 사용되는 ResourceLocalizationService의 RPC 스레드 수를 제한합니다. 기본값은 5입니다. 즉, 기본적으로 언제든지 5 개의 Localizer 만 처리되고 나머지는 RPC 대기열에서 대기합니다.
- yarn.nodemanager.localizer.fetch.thread-count: PUBLIC 리소스를 지역화하는 데 사용되는 스레드 수 입니다. PUBLIC 리소스의 현지화는 NodeManager 주소 공간 내에서 발생하므로이 속성은 PUBLIC 리소스의 현지화를 위해 NodeManager 내에서 생성되는 스레드 수를 제한합니다. 기본값은 4입니다.
- yarn.nodemanager.delete.thread-count: DeletionService에서 파일을 삭제하는 데 사용하는 스레드 수를 제어합니다. 이 DeletionUser는 로그 파일과 로컬 캐시 파일을 삭제하기 위해 NodeManager 전체에서 사용됩니다. 기본값은 4입니다.
- yarn.nodemanager.localizer.cache.target-size-mb: 리소스 지역화에 사용할 최대 디스크 공간을 결정합니다.
- yarn.nodemanager.localizer.cache.cleanup.interval-ms: 여기에 설정된 간격 이후 리소스 현지화 서비스는 총 캐시 크기가 구성된 최대 크기를 초과하는 경우 사용하지 않는 리소스를 삭제하려고합니다. 사용하지 않는 리소스는 실행중인 컨테이너에서 참조하지 않는 리소스입니다. 컨테이너가 리소스를 요청할 때마다 컨테이너가 리소스의 참조 목록에 추가됩니다. 컨테이너가이 리소스를 실수로 삭제하는 것을 방지 할 때까지 그대로 유지됩니다. 컨테이너 리소스 정리 (컨테이너가 완료되면)의 일부로 컨테이너가 리소스의 참조 목록에서 제거됩니다. 그렇기 때문에 참조 횟수가 0으로 떨어지면 삭제하기에 이상적인 후보가됩니다. 리소스는 현재 캐시 크기가 대상 크기 아래로 떨어질 때까지 LRU 기준으로 삭제됩니다.
ResourceLocalizationService 관련 장애상황 발생
하둡클러스터 운영 중 평소에 잘 수행되던 애플리케이션들이 아래와 같은 에러로그와 함께 실패하는 일들이 발생하기 시작했습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 252020-01-28 15:17:59,323 INFO localizer.ResourceLocalizationService (ResourceLocalizationService.java:addResource(864)) - Downloading public resource: { hdfs://xxx/xxx/xxx/xxx/tmp/mapreduce.tango_dw_batch.005_IQA_CALL_STAT_MAPPING_DONG_v5.phase-1.1f0957e1-4195-11ea-843a-b4969155b951/logback.xml.jar, 1580192112955, FILE, null } 2020-01-28 15:17:59,324 ERROR localizer.ResourceLocalizationService (ResourceLocalizationService.java:addResource(920)) - Failed to submit rsrc { { hdfs://xxx/xxx/xxx/xxx/tmp/mapreduce.tango_dw_batch.005_IQA_CALL_STAT_MAPPING_DONG_v5.phase-1.1f0957e1-4195-11ea-843a-b4969155b951/logback.xml.jar, 1580192112955, FILE, null },pending,[(container_e38_1577112872651_1209214_02_000004)],8810698728131019,FAILED} for download. Either queue is full or threadpool is shutdown. java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.ExecutorCompletionService$QueueingFuture@295d48be rejected from org.apache.hadoop.util.concurrent.HadoopThreadPoolExecutor@494e172a[Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 1300] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at java.util.concurrent.ExecutorCompletionService.submit(ExecutorCompletionService.java:181) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$PublicLocalizer.addResource(ResourceLocalizationService.java:899) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$LocalizerTracker.handle(ResourceLocalizationService.java:777) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$LocalizerTracker.handle(ResourceLocalizationService.java:719) at org.apache.hadoop.yarn.event.AsyncDispatcher.dispatch(AsyncDispatcher.java:197) at org.apache.hadoop.yarn.event.AsyncDispatcher$1.run(AsyncDispatcher.java:126) at java.lang.Thread.run(Thread.java:748)2020-01-28 15:17:59,323 INFO localizer.ResourceLocalizationService (ResourceLocalizationService.java:addResource(864)) - Downloading public resource: { hdfs://xxx/xxx/xxx/xxx/tmp/mapreduce.tango_dw_batch.005_IQA_CALL_STAT_MAPPING_DONG_v5.phase-1.1f0957e1-4195-11ea-843a-b4969155b951/logback.xml.jar, 1580192112955, FILE, null } 2020-01-28 15:17:59,324 ERROR localizer.ResourceLocalizationService (ResourceLocalizationService.java:addResource(920)) - Failed to submit rsrc { { hdfs://xxx/xxx/xxx/xxx/tmp/mapreduce.tango_dw_batch.005_IQA_CALL_STAT_MAPPING_DONG_v5.phase-1.1f0957e1-4195-11ea-843a-b4969155b951/logback.xml.jar, 1580192112955, FILE, null },pending,[(container_e38_1577112872651_1209214_02_000004)],8810698728131019,FAILED} for download. Either queue is full or threadpool is shutdown. java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.ExecutorCompletionService$QueueingFuture@295d48be rejected from org.apache.hadoop.util.concurrent.HadoopThreadPoolExecutor@494e172a[Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 1300] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at java.util.concurrent.ExecutorCompletionService.submit(ExecutorCompletionService.java:181) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$PublicLocalizer.addResource(ResourceLocalizationService.java:899) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$LocalizerTracker.handle(ResourceLocalizationService.java:777) at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService$LocalizerTracker.handle(ResourceLocalizationService.java:719) at org.apache.hadoop.yarn.event.AsyncDispatcher.dispatch(AsyncDispatcher.java:197) at org.apache.hadoop.yarn.event.AsyncDispatcher$1.run(AsyncDispatcher.java:126) at java.lang.Thread.run(Thread.java:748)
에러메시지의 내용은, PUBLIC 리소스를 다운로드 받는 동안 Queue 가 Full 이 되었거나 ThreadPool 이 다운되어서 localization 에 실패 했다는 내용이었습니다.
글 본문에서 설명했던 것처럼, 동시에 PUBLIC 리소스를 다운받는 설정은, yarn.nodemanager.localizer.fetch.thread-count 이며 기본값이 4 입니다. 이 설정의 기본값이 그렇게 크지 않은 이유는 정상적인 하둡 클러스터에서는 Localization 이 동시에 일어나는 경우가 그렇게 크지 않을 것으로 가정하기 때문입니다.
보통의 경우에는 실행을 하게될 애플리케이션 배포는 짧은 시간내에 이루어지고, 실제 Job 을 수행하는 과정에서 Data 를 처리하는 부분에 시간이 더 많이 걸리는 것이 일반적이기 때문으로 생각할 수 있습니다.
트러블슈팅
Localizer 의 스레드 카운트 4 값이 Full 차는 경우가 자주 발생할 수 있는 케이스는 아래 두가지 경우가 될 수 있습니다.
- 여러가지 이유로 인해 네트워크 전송 속도가 매우 느린 경우
- 전송해야되는 리소스의 크기가 매우 큰 경우
첫번째 사유가 될 수 있는 네트워크 전송 속도는 큰 문제가 없었기 때문에, 두번째 이유인 리소스의 크기를 파악해 보았습니다.
발생하는 에러가 특정 애플리케이션에서만 발생하지는 않지만, 주로 많이 발생하는 특정 Job 이 존재하여 해당 애플리케이션의 jar 파일 크기를 확인해 보니, Dependancy 가 있는 lib 의 jar 파일들을 다 포함하여 약 500MB 정도 되는 매우 큰 크기의 애플리케이션 이었습니다.
때문에, 해당 Job 이 실행되면 데이터가 분포되어 있는 Slave 노드들로 500MB 가량의 애플리케이션 실행을 위한 리소스 복사를 시작하게 됩니다. 복사해야하는 양이 매우크고, 동시에 여러노드로 복사를 하는 과정에 네트워크 대역폭도 많이 점유하게되어 전송속도도 떨어지게 되었습니다.
이 경우 가장 좋은 해결책은 문제가 되는 큰 크기의 애플리케이션에서 활용하는 lib jar 파일들을 전체 노드에 미리 복사해두고, 로컬 디렉토리의 lib 를 참조하도록 분리하는 방법입니다. 하지만, 해당 애플리케이션이 내부 개발자가 자체 개발한 애플리케이션이 아니고, Third Party Application 이었기 때문에 리소스를 분리하거나 최적화 하기에 어려움이 있었습니다.
때문에, 기본 설정값이 4 인 yarn.nodemanager.localizer.fetch.thread-count 를 더 큰 숫자로 설정해 주는 방법으로 일단 임시조치하여 해결하였습니다.
결론
설정값을 조정하여 문제해결은 되었으나, 궁극적으로 바람직하지 않은 임시 조치 방법입니다.
최근 온프레미스에서 운영중인 하둡클러스터를 클라우드 서비스로 마이그레이션 하는 것에 대한 검토를 진행하고 있는데, 문제가 되었던 Third Party App. 의 핵심 기능을 클라우드 서비스 내에서 대체할 수 있을 지 주로 살펴보고 있습니다.
주요 기능은 하둡 내에서 공간연산을 하는 기능 들인데, Hive Spatial Function 과 AWS Redshift 등을 통해 대체가 가능할지 검토 중이며, 이 내용은 정리가 되는대로 포스팅 해볼 예정입니다.