Kafka 운영자가 말하는 Producer ACKS

지금까지 컨슈머 관련 설명과 컨슈머가 메시지를 가져오는 내용에 대한 설명을 이어왔습니다. 이번에는 메시지를 보내는 프로듀서에 대해 설명하도록 하겠습니다. 프로듀서가 메시지를 보낼때, 몇가지의 옵션들을 선택하여 보낼 수 있습니다. 프로듀서의 여러가지 옵션들중에서, 저는 가장 중요하고 꼭 이해를 해야 하는 옵션이 acks라고 생각합니다. 그래서, 이번 글에서는 acks에 대해 몇가지 예제와 같이 상세히 살펴보도록 하겠습니다.
ACKS란?
acks는 acknowledgments의 약자로 사전에서 찾아 보면 "승인"이라는 뜻을 가지고 있는데, 여기에서 개념을 이해하기 위해 "확인"이라는 뜻으로 이해하면 좋을 것 같습니다. 프로듀서가 사용하는 acks 옵션은 간단하게 말해 프로듀서가 메시지를 보내고 그 메시지를 카프카가 잘 받았는지 확인을 할 것인지 또는 확인을 하지 않을 것인지를 결정하는 옵션입니다. acks에 대해 자세히 살펴보아야 하는 이유는 브로커의 config에 따라 생각하는 결과가 달라지는 경우도 있기 때문에 확실하게 개념을 이해하는 것이 중요합니다. 아래에서 그림과 같이 이해하기 쉽게 상세히 설명하도록 하겠습니다.
Producer Acks의 종류
카프카 Document에서 Producer Configs를 보면 acks옵션은 총 3가지로 구분되고 있으며, 옵션에 대해서 설명하면 아래와 같습니다.
| OPTION | Message LOSS | SPEED | DESCRIPTION |
| acks = 0 | 상 | 상 | 프로듀서는 자신이 보낸 메시지에 대해 카프카로부터 확인을 기다리지 않습니다. |
| acks = 1 | 중 | 중 | 프로듀서는 자신이 보낸 메시지에 대해 카프카의 leader가 메시지를 받았는지 기다립니다. follower들은 확인하지 않습니다. leader가 확인응답을 보내고, follower에게 복제가 되기 전에 leader가 fail되면, 해당 메시지는 손실될 수 있습니다. |
| acks = all(-1) | 하 | 하 | 프로듀서는 자신이 보낸 메시지에 대해 카프카의 leader와 follower까지 받았는지 기다립니다. 최소 하나의 복제본까지 처리된 것을 확인하므로 메시지가 손실될 확률은 거의 없습니다. |
글로 적었는데, 잘 이해가 되시나요? 여기에서는 acks 옵션에 따라 프로듀서가 메시지를 보내는 속도와 메시지 손실률이 다르다는 부분정도만 이해하시면 되고, 아래에서 옵션별로 다시 살펴보겠습니다.
acks=0
이 옵션의 경우 프로듀서가 메시지를 보내는 속도와 메시지 손실률이 가장 높은 등급인 "상" 입니다. 왜 "상"인지 아래 그림을 보겠습니다.
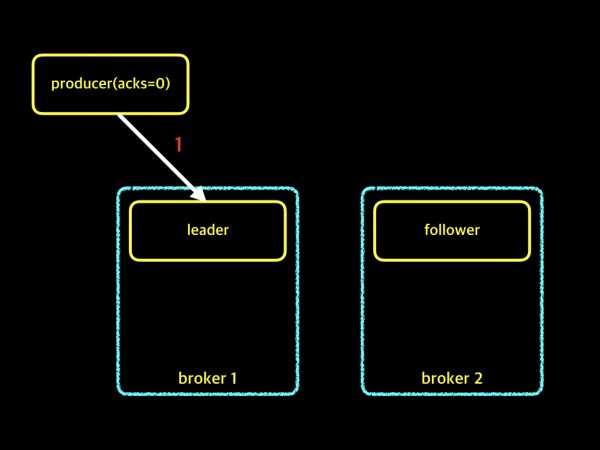
producer에서 acks=0 이라고 설정하면, 프로듀서는 메시지를 보내고 leader로부터 보낸 메시지에 대해 잘 받았는지 확인을 기다리지 않습니다. 프로듀서는 응답을 기다리는 시간 없이 계속 보내기만 합니다. 만약 프로듀서가 메시지를 보내는 중간에 파티션의 leader가 다운되거나 서버가 다운되거나 할 경우에 메시지 일부가 손실될 수 있습니다. 이러한 이유 때문에 메시지 손실 가능성이 가장 높고, 보내는 속도 역시 가장 빠릅니다. 메시지의 손실을 감안하더라도 빠르게 메시지를 보내야 할 경우에 사용하시면 좋습니다. 이어서 다음 옵션도 살펴보겠습니다.
acks=1
이 옵션의 경우 프로듀서가 메시지를 보내는 속도와 메시지 손실률 모두 "중"입니다. acks=0옵션과 다른점이 무엇인지 아래 그림을 보겠습니다.
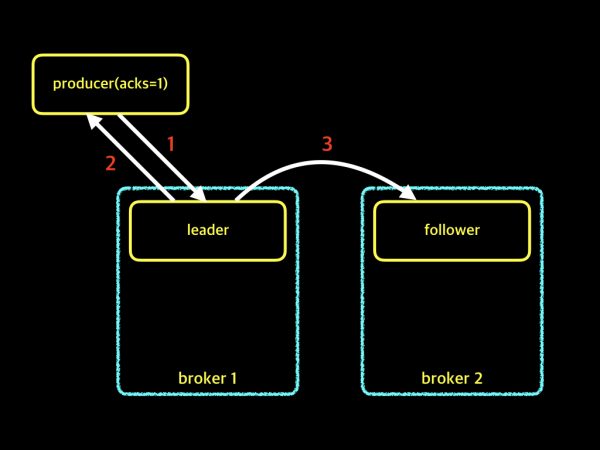
producer에서 acks=1 이라고 설정하면, 프로듀서는 메시지를 보내고 파티션의 leader로부터 메시지를 잘 받았는지 확인을 위해 기다립니다. 프로듀서가 메시지를 보내고 난 후, 대기 시간없이 바로 다음 메시지를 보내던 acks=0의 방식과 달리 보낸 메시지를 잘 받았는지 응답을 기다리기 때문에, acks=0보다 메시지를 보내는 속도가 느립니다. 하지만 메시지를 보내는 속도가 느린 단점과 달리, 파티션의 leader가 메시지를 받았는지 확인하기 때문에 메시지의 손실 가능성은 낮습니다. 그렇다고 해서 메시지가 손실될 가능성이 전혀 없는 것은 아닙니다. 그럼 어떤 경우에 메시지 손실이 발생하는지 예제로 아래 그림을 보겠습니다.
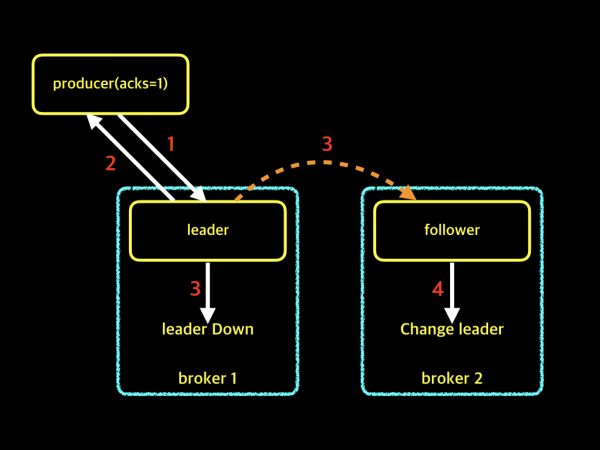
위 그림을 보면서, 순서대로 설명드리겠습니다.
- 프로듀서가 acks=1로 메시지를 보냅니다.
- 파티션의 leader가 메시지를 받고 프로듀서에게 acks에 대한 응답을 합니다.
- follower가 leader의 업데이트된 메시지를 복제하려고 하는 시점에, leader가 down이 되어 메시지를 복제하지 못하였습니다.
- 파티션에서 leader의 존재가 사라졌기 때문에, follower는 파티션의 leader로 변하게 되며, 결국 조금 전 프로듀서가 보낸 메시지는 손실되게 됩니다.
이렇게 acks=1이라고 해서 메시지 손실률이 전혀 없는 것은 아닙니다. 하지만 방금 설명드린 현상이 빈번하게 일어나는 일은 아니고, 메시지를 보내는 속도 역시 고려사항중 하나이기 때문에 실제 운영환경에서는 acks=1로 가장 많이 사용하고 있습니다. 제가 운영하는 카프카에서도 프로듀서 옵션은 acks=1을 가장 많이 사용하고 있습니다. 이어서 마지막 옵션에 대해 살펴보겠습니다.
acks=all(-1)
이 옵션의 경우 프로듀서가 메시지를 보내는 속도와 메시지 손실률 모두 "하" 입니다. 위에 설명드린 옵션들과는 어떤 차이점이 있는지 그림으로 살펴보겠습니다.
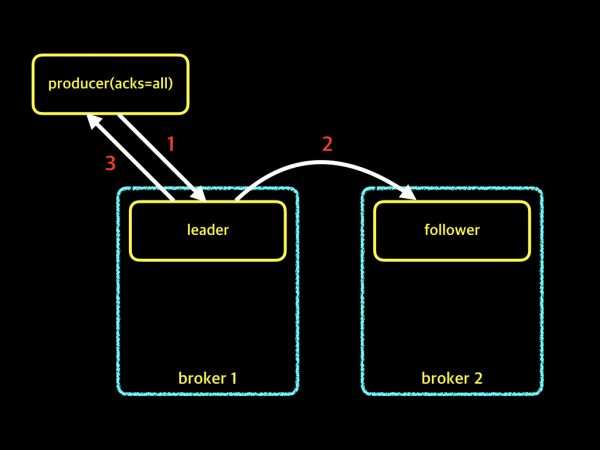
producer에서 acks=all 이라고 설정하면, 프로듀서는 메시지를 보내고 acks=1과 마찬가지로 파티션의 leader로부터 메시지를 잘 받았는지에 대해 확인을 합니다. 하지만 acks=1과 차이점은 leader뿐만 아니라 follower까지 복제가 완료 되었는지 확인을 합니다. leader와 follower 모두가 메시지를 정상적으로 받았는지를 확인하기 때문에 메시지 손실률은 제로에 가깝습니다. 하지만 확인을 위해서 기다리는 시간이 길어지기 때문에 프로듀서가 메시지를 보내는 속도 부분에서는 가장 느립니다. 메시지의 손실률이 매우 중요한 경우에 적합한 옵션입니다. 그런데, 여기서 한가지 궁금한점이 있습니다. 만약 파티션의 leader는 메시지를 잘 받았는데, follower가 복제를 하지 못했다면? 또는 복제하는 job이 실패했다면 어떻게 될까요? 아래 그림을 살펴보겠습니다.
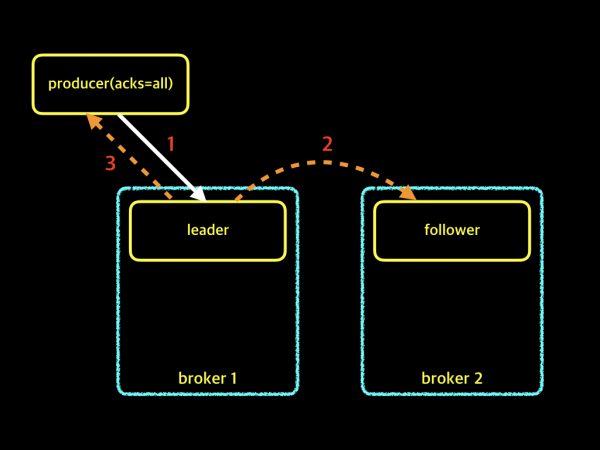
위 그림에서 보는것처럼 2번 작업인 복제 작업이 실패하면서, leader는 프로듀서에게 메시지를 잘 받았다는 확인 응답을 할 수 없게됩니다. 결국 프로듀서가 보낸 메시지는 실패 처리가 됩니다. 방금 설명 드린 그림의 예제는 Replication Factor가 2인 경우입니다. 그럼 이번에는 Replication Factor가 3인 경우라고 가정해 보겠습니다. Replication Factor가 3이면, 1개의 leader와 2개의 follower가 존재합니다. follower가 2개가 되니 혼란스럽습니다. 아래 예제 그림을 살펴보겠습니다.
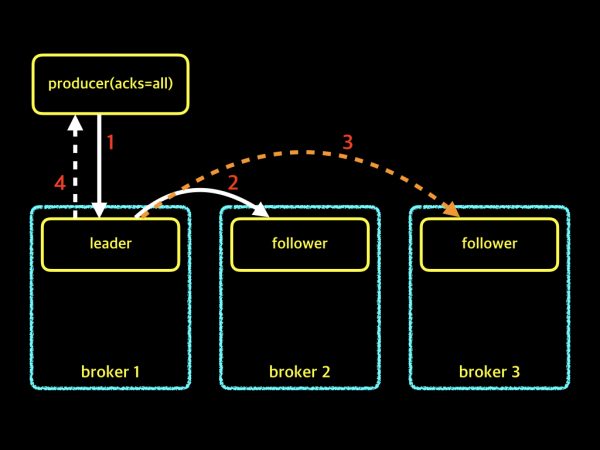
위 그림에서 follower가 2이기 때문에 각 follower들은 2번과 3번의 복제 작업이 이루어져야 하는데, broker 2의 follower는 복제가 성공하고 broker 3의 follower는 복제를 실패했습니다. 이런 경우에 파티션의 leader가 프로듀서에게 성공적으로 메시지를 기록했다는 확인 응답을 보낼 수 있을까요? 정답은 확인 응답을 보낼 수도 있고, 보내지 못할 수도 있습니다. 방금 설명드린 예제와 같은 상황에 필요한 옵션이 바로 min.insync.replicas입니다. 이제 min.insync.replicas 옵션에 대해서도 한번 살펴보겠습니다.
min.insync.replicas
이 옵션에 대해서 간략하게 설명드리겠습니다. min.insync.replicas 옵션은 프로듀서가 acks=all로 설정하여 메시지를 보낼 때, write를 성공하기 위한 최소 복제본의 수를 의미합니다. 이 옵션은 프로듀서의 옵션이 아니고, 브로커의 옵션입니다. 브로커의 config/server.properties 파일에서 설정을 변경할 수 있으며, 기본값은 1입니다. 방금 전 위에서 예제로 말씀드린 Replication Factor가 3인 경우처럼 min.insync.replicas의 config 값과 Replication Factor 수에 따라 프로듀서의 메시지가 성공 또는 실패가 결정되므로, 정확하게 이해하고 설정하여 사용하는 것이 중요하다고 생각합니다. 제가 몇가지 경우의 수에 대해 직접 테스트를 하였고, 그 내용을 설명드리도록 하겠습니다. 먼저 제가 설정한 옵션에 대해서 살펴보겠습니다.
Topic name : peter-topic-rf2 Replication Factor : 2 Partition Number : 1 min.insync.replicas : 1 or 2 Test : 복제가 안되는 상황을 재현하기 위해서, broker node를 down시켜 상황을 재현
RF=2, min.insync.replicas=1
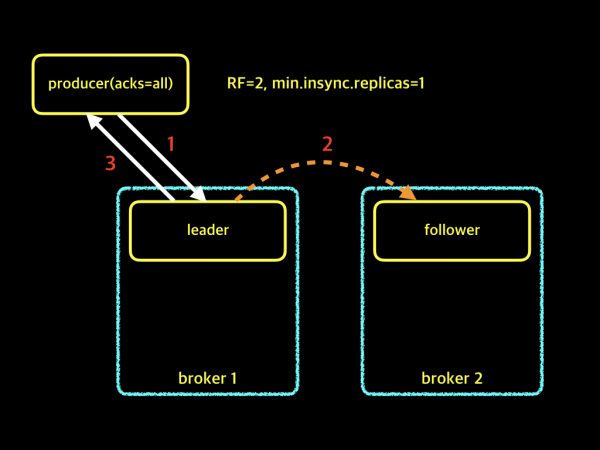
위의 그림은 Replication Factor가 2이고, min.insync.replicas가 1인 경우입니다. Replication Factor가 2이므로, 파티션에는 leader 1개와 follower 1개가 존재합니다. 프로듀서에서 acks=all로 설정하고, 메시지를 보내게 되면 파티션의 leader와 follower까지 복제가 되기를 기다려야 합니다. 하지만, 브로커에서 min.insync.replicas의 config를 1로 설정하였기 때문에 follower에게 복제가 이루어지지 않더라도, 파티션의 leader는 프로듀서에게 확인 응답을 보내게 됩니다. 결과적으로 위와 같은 설정은 브로커 노드 하나가 다운되더라도 실패하지 않고 메시지를 보낼 수 있습니다. 이어서 다음 예제 보겠습니다.
RF=2, min.insync.replicas=2
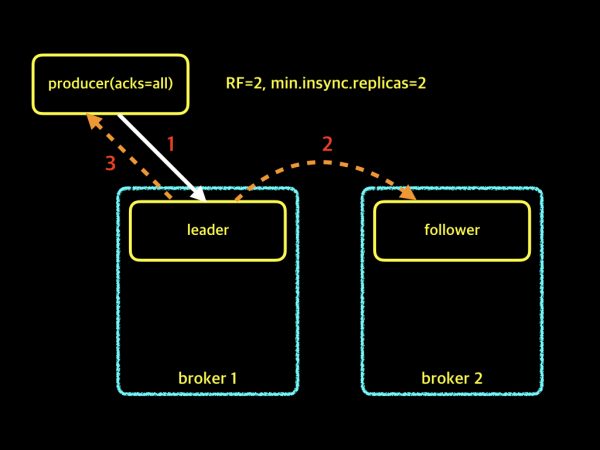
위의 그림은 Replication Factor가 2이고, min.insync.replicas가 2인 경우입니다. Replication Factor가 2이므로, 파티션에는 leader 1개와 follower 1개가 존재합니다. 프로듀서에서 acks=all로 설정하고, 메시지를 보내게 됩니다. 브로커의 min.insync.replicas는 2로 설정되어 있기 때문에 파티션의 leader를 포함한 follower까지 복제가 이루어져야 메시지가 성공적으로 write됩니다. 하지만 broker 2의 follower가 복제를 실패하였고, 최소 복제 수를 충족하지 못하였기 때문에 leader는 프로듀서에게 확인 응답을 보낼 수 없게 되었고, 결국 write는 실패하였습니다. 말씀드린 현상을 broker 1에서 로그를 살펴보면 아래와 같은 에러 로그가 발생하였습니다.
[2017-01-03 19:54:44,004] ERROR [Replica Manager on Broker 4]: Error processing append operation on partition peter-topic-rf2-0 (kafka.server.ReplicaManager) org.apache.kafka.common.errors.NotEnoughReplicasException: Number of insync replicas for partition [peter-topic-rf2,0] is [1], below required minimum [2][2017-01-03 19:55:08,807] ERROR [Replica Manager on Broker 4]: Error processing append operation on partition peter-topic-rf2-0 (kafka.server.ReplicaManager) org.apache.kafka.common.errors.NotEnoughReplicasException: Number of insync replicas for partition [peter-topic-rf2,0] is [1], below required minimum [2]
위 에러 메시지는 peter-topic-rf2라는 토픽에 메시지를 보내는데, 최소 복제 요구 값인 2보다 적은 수로 되어 있기 때문에 에러가 발생한다는 내용입니다. Replication Factor가 2이고, min.insync.replicas를 2로 설정하게 되었을때, 브로커 노드 한대만 다운되더라도 프로듀서가 메시지를 보낼 수 없게 됩니다. 그래서 저는 RF를 2로 운영 할 경우 min.insync.replicas를 2로 설정하기 보다는 1로 설정하는 것이 최적의 값이라고 생각합니다. 지금까지 Replication Factor가 2의 경우에 대해 설명드렸고, 이어서 Replication Factor가 3인 경우를 살펴보겠습니다. 먼저 제가 설정한 옵션은 아래와 같습니다.
Topic name : peter-topic-rf3 Replication Factor : 3 Partition Number : 2 min.insync.replicas : 1 or 2 Test : 복제가 안되는 상황을 재현하기 위해서, broker node를 down시켜 상황을 재현
RF=3, min.insync.replicas=1
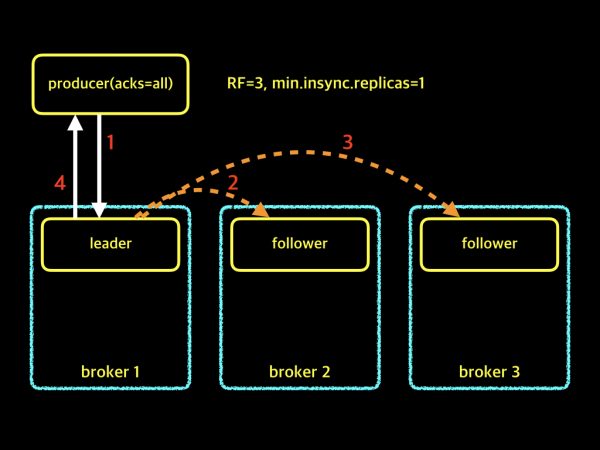
위의 그림은 Replication Factor가 2이고, min.insync.replicas가 1인 경우입니다. Replication Factor가 3이므로, 파티션에는 leader 1개와 follower 2개가 존재합니다. 프로듀서에서 acks=all로 설정되어 있고, min.insync.replicas의 config는 1로 설정되어 있어, 모든 follower들이 복제가 실패하더라도 파티션의 leader는 프로듀서에게 확인 응답을 보낼 수 있습니다. 다시 말씀드리자면, 운영중에 브로커 노드 2개가 다운되더라도 프로듀서가 정상적으로 메시지를 보낼 수 있는 상황입니다. 다음 예제 살펴보겠습니다.
RF=3, min.insync.replicas=2
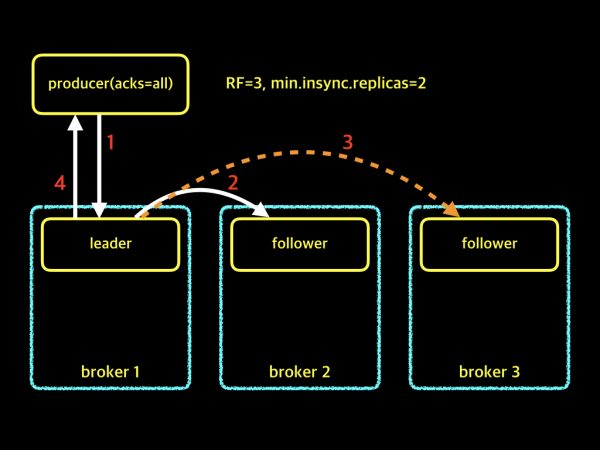
위의 그림은 Replication Factor가 2이고, min.insync.replicas가 2인 경우입니다. Replication Factor가 3이므로, 파티션에는 leader 1개와 follower 2개가 존재합니다. 프로듀서에서 acks=all로 설정되어 있고, min.insync.replicas의 config는 2로 설정되어 있습니다. 두개의 follower중 최소 하나의 follower만 복제에 성공하게 되더라도, 최소 요구 수 2를 유지할 수 있게 되어 파티션의 leader는 프로듀서에게 확인 응답을 보낼 수 있습니다. 다시 말해, 브로커 노드 한대가 다운되더라도 프로듀서가 정상적으로 메시지를 보낼 수 있는 상황입니다. 설명드린 예제 중에서 가장 안정적인 예제입니다.
RF=3, min.insync.replicas=2

위의 그림은 방금 위에서 설명드린 내용과 같이 Replication Factor가 3이고, min.insync.replicas가 2인 동일한 경우입니다. 차이점은 2개의 follower 모두가 복제를 실패했을 경우입니다. 최소 복제 수가 2인데, 모든 follower들이 복제를 모두 실패하였기 때문에, 파티션의 leader는 프로듀서에게 확인 응답을 보낼 수 없습니다. broker 1에서 앞서 설명드렸던 에러 로그와 동일한 로그가 발생하였고, 아래에서 로그 내용을 살펴 보도록 하겠습니다.
[2017-01-03 19:57:44,403] ERROR [Replica Manager on Broker 3]: Error processing append operation on partition peter-topic-rf3-1 (kafka.server.ReplicaManager)org.apache.kafka.common.errors.NotEnoughReplicasException: Number of insync replicas for partition [peter-topic-rf3,1] is [1], below required minimum [2]
[2017-01-03 19:57:54,589] ERROR [Replica Manager on Broker 3]: Error processing append operation on partition peter-topic-rf3-1 (kafka.server.ReplicaManager)
org.apache.kafka.common.errors.NotEnoughReplicasException: Number of insync replicas for partition [peter-topic-rf3,1] is [1], below required minimum [2]
위 에러 메시지는 peter-topic-rf3에 메시지를 보내는데, 최소 복제 요구 값인 2 보다 적기 때문에 에러가 발생한다는 내용입니다. 위 예제는 단지 설명을 드리기 위하여 상황을 재현한 예제이고, 실제 운영환경에서 브로커 노드 2개가 동시에 다운되는 일은 거의 발생하지 않습니다. 그래서 Replication Factor를 3으로 운영하시고, 안정적인 구현을 위해서는 min.insync.replicas는 2로 설정하는 것이 가장 바람직하다고 생각됩니다.
지금까지 프로듀서의 acks옵션과 브로커의 min.insync.replicas옵션에 대해 설명했습니다. 제가 설명드린 여러 예제중 가장 안정적인 예제로 acks=all, Replication Factor=3과 min.insync.replicas=2로 설명드렸지만, 실제 운영환경에서 가장 많이 쓰이는 옵션은 아닙니다. 운영환경에서 가장 많이 쓰이는 옵션은 프로듀서의 acks=all보다는 acks=1를 가장 많이 사용하고 있습니다. 그래서 저는 운영하면서 브로커의 min.insync.replicas옵션에 대해 크게 신경쓰지 않았습니다. 하지만 앞으로 추가되는 메시지의 중요도에 따라 해당 옵션들을 변경하여 사용할 수 있기 때문에 해당 옵션들에 대해 완벽하게 이해하시고 본인의 운영환경을 파악한 후 그에 알맞은 설정을 하는 것이 가장 중요하다고 생각합니다. 위에서 말씀드린 옵션들에 대해 이해하시는데 조금이나마 도움이 되었길 바라고, 다음 내용은 실제 운영환경에서 acks 옵션으로 인해 발생한 이슈 내용을 설명드리도록 하겠습니다. 긴 글 읽어주셔서 감사합니다.