Time series OLAP – Druid Batch Ingestion(3)

Druid - 보이지 않는 위험
위험을 피하려면 최악의 사태를 항상 대비해 두어야 한다.
- 그라시안

출처 : http://sites.psu.edu/siowfa15/wp-content/uploads/sites/29639/2015/09/2457004-crying2.jpg
필자의 경우 Batch Ingestion에서 많은 고통을 느꼈다 ㅠㅠ
Druid를 적용하는 케이스가 실시간쪽보다는 배치쪽인 경우가 다수였으며 Batch 의 경우, Druid와의 싸움(?)보다는 MR job에 의존도가 크기에 문제 해결에 상당히 많은 시간이 소요되었다. 혹시나 같은 고통을 겪으실 누군가에게 이 글을 바친다.
Druid는 실시간 처리 외에도 정적 파일(HDFS/S3)에 대한 ingestion도 지원한다.
HDFS에서 ingestion을 하는 경우 hadoop MR job으로 수행되며 앞서 언급한 overlord node에 ingestion job을 submit하면 된다.
다음은 hadoop ingestion을 하기 위한 json spec 예제이다.
[참고 : http://druid.io/docs/latest/ingestion/batch-ingestion.html]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61{ "type" : "index_hadoop", "spec" : { "dataSchema" : { "dataSource" : "wikipedia", "parser" : { "type" : "hadoopyString", "parseSpec" : { "format" : "json", "timestampSpec" : { "column" : "timestamp", "format" : "auto" }, "dimensionsSpec" : { "dimensions": ["page","language","user","unpatrolled","newPage","robot","anonymous","namespace","continent","country","region","city"], "dimensionExclusions" : [], "spatialDimensions" : [] } } }, "metricsSpec" : [ { "type" : "count", "name" : "count" }, { "type" : "doubleSum", "name" : "added", "fieldName" : "added" }, { "type" : "doubleSum", "name" : "deleted", "fieldName" : "deleted" }, { "type" : "doubleSum", "name" : "delta", "fieldName" : "delta" } ], "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "DAY", "queryGranularity" : "NONE", "intervals" : [ "2013-08-31/2013-09-01" ] } }, "ioConfig" : { "type" : "hadoop", "inputSpec" : { "type" : "static", "paths" : "/MyDirectory/example/wikipedia_data.json" } }, "tuningConfig" : { "type": "hadoop" } }, "hadoopDependencyCoordinates": <my_hadoop_version> }
batch ingestion의 경우 type은 index-hadoop이다. 실시간과 다른점은 당연한 이야기지만 batch의 경우 intervals를 꼭 지정해주어야 한다. batch로 ingestion을 한다는것은 기존 데이터를 실시간이 아닌 이미 해당 데이터가 적재된 이후에 별도로 Druid에 적재 하는 것이기 때문이다.
위의 예제에는 interval이 8/31~9/1로 명시되어 있는데 이는 8/31 00:00:00~9/1 00:00:00초까지의 데이터를 ingestion하겠다는 것이다. 즉 8/31일자만 적재된다. 데이터 필드에 다른 날짜가 있더라도 이는 수집 데이터에서 제외된다. 위의 설정에서 paths 에는 hadoop/s3의 여러 데이터 패스를 ,(comma separator)로 정의할 수 있다.
위의 작업을 overlord node 로 submit하고 나면 다음과 같은 MR job이 2번 수행된다.
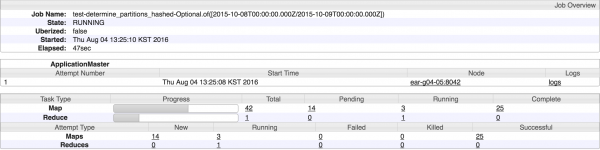
첫번째 MR - determine_partitions
수집 대상 hadoop data의 cardinality를 구하여 설정 정보에 따라 segment의 shard개수를 결정하는 작업이다.
이때 targetPartitionSize(row수)를 주게되면 cardinality/targetPartitionSize로 shard개수가 나누어진다.
대략적으로 데이터 양을 이미 알고 있으면 numShards(target partition size대신에 직접적으로 파티션 수를 결정)값을 부여하면 된다.
권장되는 segment size는 500~1G 내이므로 ingestion시 연산된 cardinality에 따라 targetPartitionSize를 적절히 조절하여 segment 를 유지해야 한다.

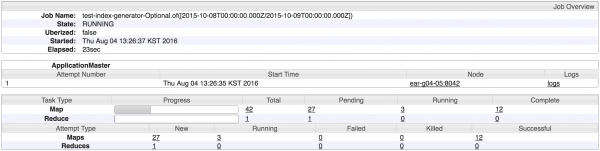
두번째 MR - IndexGeneration
druid index segment를 수행하는 작업이다. 이 과정이 끝나면 broker node로 해당 데이터소스에 대한 질의가 가능하다.

Batch Ingestion시 고려사항
Druid에 적재하고자 하는 대상 데이터가 큰 경우, 혹은 배치 적재시 시간을 단축해야 하는 경우 고려사항은 다음과 같다.
1. 대상 데이터의 cardinality를 고려하여 targetPartitionSize를 정한다.
첫번째 MR에서 다음과 같은 로그를 발견할 수 있다.
12016-08-04T08:32:36,979 INFO [task-runner-0-priority-0] io.druid.indexer.DetermineHashedPartitionsJob - Found approximately [55,929] rows in data
해당 데이터의 cardinality를 추정한것으로 위의 데이터의 경우 Segment Granularity에 해당하는 (여기서는 DAY기준) row수는 55,929건에 해당한다.
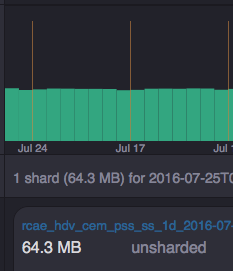
targetPartitionSize를 지정하지 않는 경우 -1로 세팅된다. 위에서 언급한것처럼 segment size를 고려하여 shard 될 수 있도록 해당 값을 변경하여야 한다. indexing 이후의 shard정보는 coordinator node 의 웹페이지에서 아래와 확인 할 수 있다. 해당 데이터소스의 시간 기준은 일자별이며 해당 일자의 segment는 shard개수가 1개 이다.
2. MR Performance tuning
필자의 경우 YARN기반에서 ingestion을 수행하였으며 tuningConfig부분에 jobProperties에 MR관련 옵션들을 다음과 같이 설정할 수 있다. ingestion대상 데이터가 많은 경우 MR의 값들을 조정하여 처리 시간을 단축(자원 점유에 반비례)할 수 있다.
1 2 3 4 5 6 7 8"jobProperties" : { "mapreduce.task.files.preserve.filepattern" : ".*", "keep.task.files.pattern" : ".*", "mapreduce.map.memory.mb" : "5120", "mapreduce.reduce.memory.mb" : "5120", "mapreduce.map.java.opts" : "-server -Xmx4096m -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps", "mapreduce.reduce.java.opts" : "-server -Xmx4096m -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps" },
다음 글에서는 이전 글에서 잠깐 언급했던 Segment와 Druid query type에 대해서 자세히 다룰것이다.
연재 순서는 : Druid 입문(1) -> 실시간 Ingestion(2) -> Batch Ingestion(3) -> Segment deep dive(4) -> Glue Architecture(5) -> Trouble Shooting(6)
TO BE CONTINUED