Time series OLAP - Druid 입문(1)

Druid - 전쟁의 서막
때는 찬바람 불어 호빵을 호호 불며 우물거리던 작년 겨울
Business Problems
쉴틈도 없이 마구마구 뿜어내는 time series 데이터를 어떻게 효율적으로 처리할까라는 고민에서 시작되었다. 빅데이터에는 수많은 오픈소스 기술셋이 존재한다. 적합한 오픈소스는?
[참고 : http://xyz.insightdataengineering.com/blog/pipeline_map.html ]
Solution
비지니스 요건중에 time series 데이터에 대한 통계를 탄력적으로 처리(시간 단위 aggregation)할 수 있냐는 요건이 있었고 당시 가장 부합하는 기술요건은 Druid로 보였다. Druid는 실시간과 배치를 모두 지원하는 time series OLAP engine이다.
Open Source Druid
Druid는 Apache open source license 이며 현재 Apache Project는 아니다. Imply와 Metamarket이라는 기업이 주도하여 개발되고 있다.
[참고 : https://github.com/druid-io ]
Druid = OLAP ? OLAP이 뭔지 알아보자
구글링 결과
OLAP is an acronym for Online Analytical Processing.
OLAP performs multidimensional analysis of business data and provides the capability for complex calculations, trend analysis, and sophisticated data modeling.
깔끔하게 번역할 자신이 없어서 ㅠㅠ
공신력 있는 두산백과에 따르면
OLAP(On-Line Analytical Processing) 즉 온라인 분석 처리는 다차원 데이터 구조를 이용하여 다차원의 복잡한 질의를 고속으로 처리하는 데이터 분석 기술이다. 기업의 분석가, 관리자 및 임원들은 OLAP 기술을 통해 필요한 정보에 대해 대화형으로 빠르게 접근 가능하다.
[네이버 지식백과]OLAP [On-Line Analytical Processing] (두산백과)
"Druid is NOT time series DB"
즉, Druid는 원본을 저장하지 않으며 기존 데이터에서 OLAP질의가 가능하도록 indexing하는 구조를 가지고 있다.
모든 데이터는 시간단위로 분할되어 필요시 summary형태로 요약될 수 있다.
Real World로 예를 들면, 어떤 웹사이트에서 전일자 사용자 수를 계산해야 한다. 기존 처리 방식에서는 SQL on Hadoop기술 혹은 MR을 이용하여 HDFS에 적재된 데이터를 읽고 aggregation 연산(일자별 사용자수 count)을 수행하여 계산하였을것이다. Data Warehouse(이하 DW)환경에서는 이러한 요약작업을 Data Mart생성이라고 한다.
이때, 만약 사용자가 일자별이 아니라 월별/분기별/년도별로 데이터를 보고 싶다면 어떻게 해야할까? 기존 DW환경에서는 필요시 summary를 생성하는 작업을 수행할것이다. Druid는 시간별로 사용자를 count하는 연산을 post aggregation을 통해 탄력적으로 질의하는 것이 가능하다. 즉, 데이터는 한번에 ingestion하고 이후에 질의는 시간 단위로 자유롭게 aggregation할 수 있는것이다. 관련된 자세한 내용은 Segment deep dive(4) 시리즈에서 질의와 함께 설명할 것이다.
아키텍처의 이해
[참고 :http://static.druid.io/docs/druid.pdf]
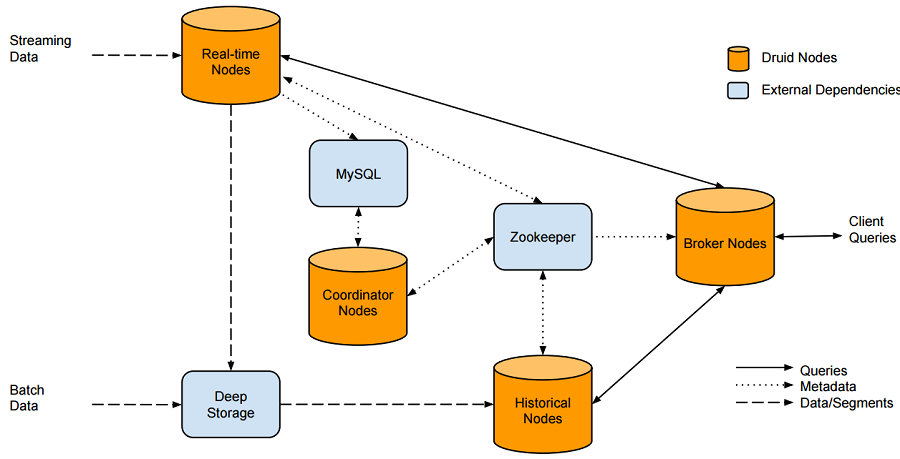
위에서 언급한것처럼 Druid 는 실시간 아키텍처와 배치 아키텍처를 모두 수용한다. 원본 데이터가 실시간인 경우 Real-time node에서 색인되며 segment(time 설정 기준)으로 Deep Storage로 내리게 된다. 배치 데이터는 Deep Storage에 저장되며 Deep Storage는 HDFS, S3등으로 구성될 수 있다.
사용자 쿼리는 Broker node가 담당한다. segment정보를 생성하지 않은 fresh한 데이터는 Real-time node에서 그리고 배치로 색인된 데이터는 Historical Node에서 가져오게 된다. Druid 내부 컴포넌트간 통신은 zookeeper로 되어있다.
Druid관련 메타정보는 mysql등 RDBMS 저장할 수있다.
Coordinator는 메타정보를 통해 segment life cycle(복제 계수 조정 및 Load/Drop)을 관리한다.
Segment
druid는 segment file(time 설정 기준)에 index를 저장한다. segment 파일의 데이터 구조는 다음과 같다.
[참고 : http://druid.io/docs/latest/design/segments.html ]
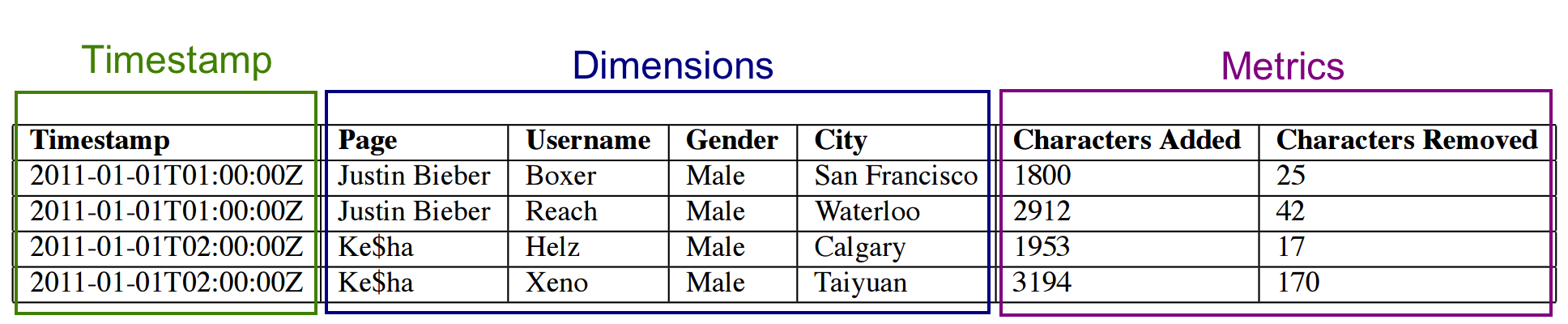
segment는 columnar로 구성되며 컬럼 타입은 위와 같다. time series 기반이기에 timestamp가 아주아주 중요하다. (데이터에 time이 없다면 그건 앙꼬없는 찐빵-_-;;) metric는 수치데이터 이며 timestamp 기준에 따라 pre-aggregation/post-aggregation이 가능하다. Dimensions은 filter/group by가능한 필드이며 현재는 String type (delimiter를 주어 multi value도 가능) 만 지원하고 있다.
좋은 건 알겠는데~~Druid로 할 수 있는일
계속 반복되는 말 ...Druid는 실시간/배치로 데이터를 수집하여 OLAP질의를 처리할 수 있다. 다음 글에서 하나씩 알아보도록 하고 이만 마~무~의~리
연재 순서는 : Druid 입문(1) -> 실시간 Ingestion(2) -> Batch Ingestion(3) -> Segment deep dive(4) -> Glue Architecture(5) -> Trouble Shooting(6)
TO BE CONTINUED