timelion 필드 집계 오류

ELK 스택 삼대장 중 키바나를 개발한 '라쉬드 칸(Rashid Khan)'이 비행기 타고 가다 뚝딱 만들었다는 timelion. 이름에서 알 수 있듯이 timelion은 시계열 데이터 분석에 특화되어 있으며, 함수 형식의 표현식을 사용한다. 자동완성을 지원하기 때문에, 학습도 그리 어렵지 않은 편.
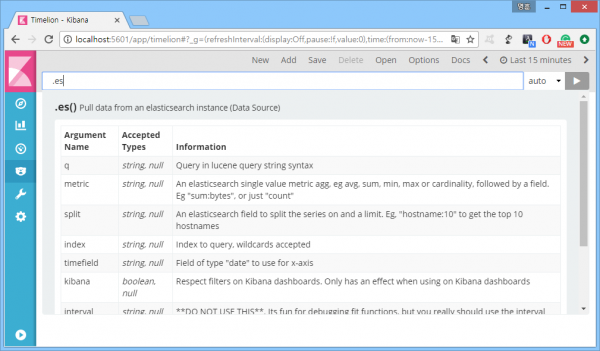
웹서버 접속자의 국가별 발생 추이를 그려보자. 다음은 상위 5개의 접속국가 추이를 그려주는 표현식 '.es(split=geoip.country_name:5)'의 사용 결과. 아무 것도 안 그려진다.
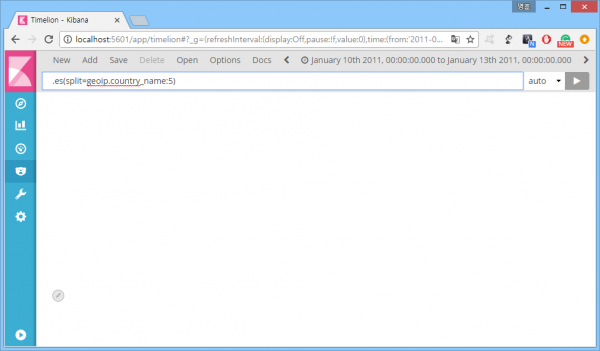
뭐지? 접속 기록이 없다는 건가? 그건 아닌 것 같고, timelion이 아예 동작을 안 한 것 같다. 표현식은 맞는데(..) 인덱스명을 추가해봤다.
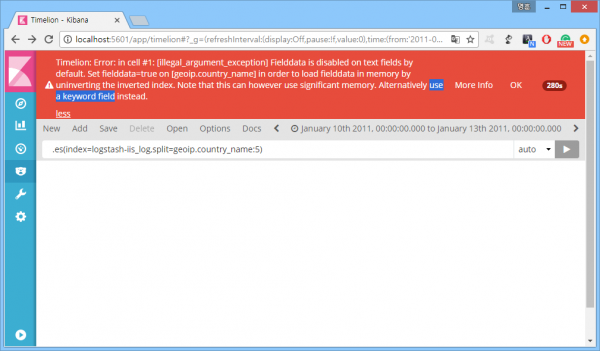
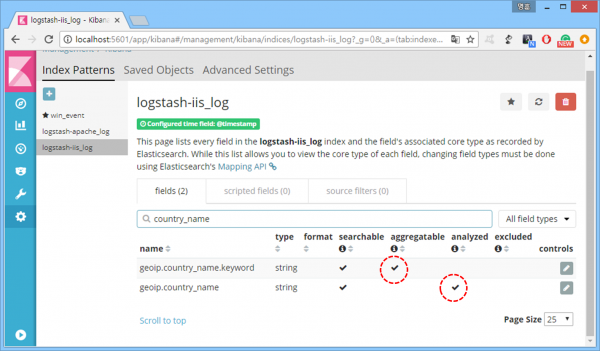
뭔가 더 큰 일 난 듯. 에러 메시지를 대충 읽어보니 뭔 소린지 모르겠다매핑에서 뭘 바꾸란다. 아니면 keyword 필드를 사용하든지. 그게 뭐지 싶어 해당 인덱스 필드를 뒤져보니 '.keyword'로 끝나는 이름을 가진 필드가 하나 더 있다.
엘라스틱서치는 분석기(analyzed)를 통해 단어 단위 검색(Full Text Search)이 가능한 풀 텍스트 인덱스를 생성하는데, 이렇게 분석기를 거친 필드는 집계 연산 과정에서 성능상 불리함을 갖는 듯하다. 그래서 집계나 정렬 등 작업 시 성능 향상을 위해 분석기를 거치지 않는 keyword 필드를 따로 두는 듯. 밑천이 딸려서 송 준이님 글로 보충 설명.
text & keyword 필드 타입 기존에 string 타입에 대해 분석(analyze)이 필요한 경우는 2가지 유형이었다. - analyzed: 전문 검색(full-text)이 필요한 경우 - not_analyzed: 키워드 검색, 정렬, 집계(aggregation)이 필요한 경우 5.0.0 버전부터는 각 유형을 목적에 맞게 text 타입, keyword 타입으로 분리했다.
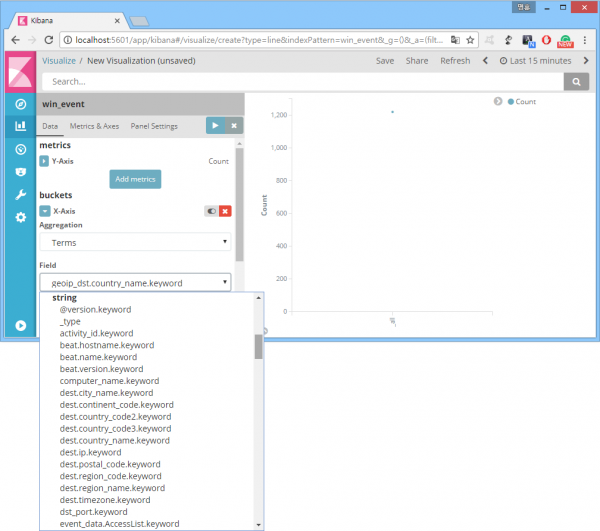
정말인가 싶어 'Visualize' 메뉴에서 통계 그래프 생성에 사용되는 필드를 살펴보니 실제로 문자열 필드는 전부 keyword 필드. (메타 필드 '_type' 빼고)
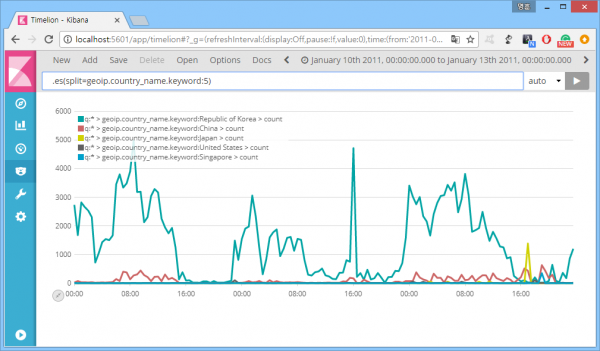
다음은 해당 필드명을 이용한 표현식 '.es(split=geoip.country_name.keyword:5)'의 사용 결과. 이제 발생 추이가 그려진다.
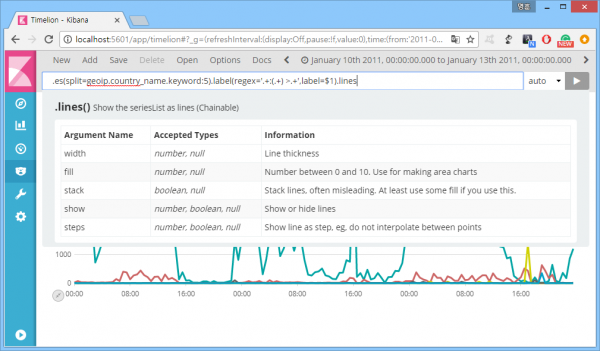
이제 그래프는 그려졌으니, 좀더 예쁘게 꾸며보자. 어쩌면 제일 중요할 수도 있는 과정. 조상님이 얘기하셨다. 보기 좋은 떡이 먹기도 좋고, 이왕이면 다홍치마라고. 'lines' 옵션을 이용하면 기본 선그래프에 변화를 줄 수 있다.
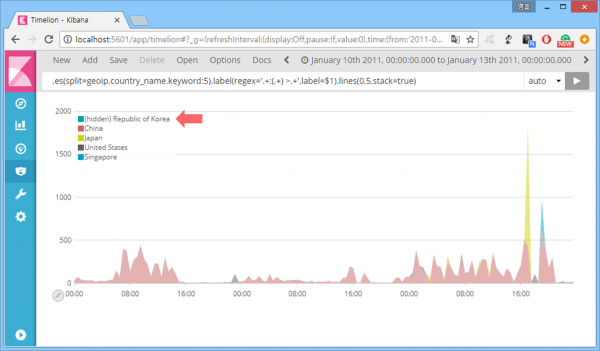
다음은 표현식 '.es(split=geoip.country_name.keyword:5).label(regex='.+:(.+) >.+',label=$1).lines(0,5,stack=true)'의 사용 결과. 그래프의 윤곽선을 없애고(width=0), 색을 채운 후(fill=5), 누적 그래프(stack=true)로 바꿨다. 왠지 있어 보이는 효과 발생.
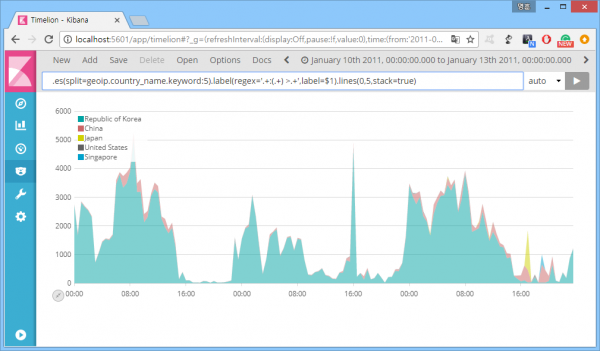
참고로 범례 표시에서 원하는 범례를 클릭하면 해당 그래프를 숨길 수 있다.
엘라스틱서치 전반적으로 그렇지만, timelion도 세부 기능 하나하나까지 참 신경 많이 썼다는 느낌을 받는다. 개발자가 분석 업무를 직접 해보면서 빡치는사용자 경험을 충분히 쌓았거나, 분석가와 긍정적 피드백을 활발하게 주고 받는다는 얘기.
개발자는 종종 NSM(Network Security Monitor)에 있어 기술적으로 가장 뛰어나지만 분석가의 요구를 분석하기 위한 최적의 위치에 있는 것은 아니다. 분석가는 반드시 자신의 의견을 개발자에게 효과적으로 전달하는 통로를 가지고 있어야 한다. - 네트워크 보안 실무 (418 페이지)