개발자가 배우는 R : 2강, 객체 다루기

개요
이번 포스팅에는 R의 객체를 다루는 것을 집중적으로 알아본다. 기본적으로 코드예제가 많다. 이유는 코드를 이해 혹은 실습해보는 것이 R을 익히는데 가장 빠른 길이라 생각하기 때문이다. 또한 지금 배우지 않더라도 필요할 때 찾아서 쓰는 것도 코드가 가장 빠를 것이다. 코드중심의 설명이기 때문에 본문 보다는 코드의 주석이 집중적으로 추가되어 있으니 참고 바란다.
R 자료구조(객체 종류)
R 자료구조는 아래와 같이 벡터, 행렬, 배열, 데이터 프레임, 리스트가 있다. 벡터, 행렬, 배열은 하나의 데이터 타입으로 통일하여야 한다. 데이터 타입을 복합적으로 사용하여야 한다면 데이터 프레임을 사용하면 된다. 이중에서 집중적으로 공부하고 사용할 부분은 당연하지만 벡터와 행렬이다.
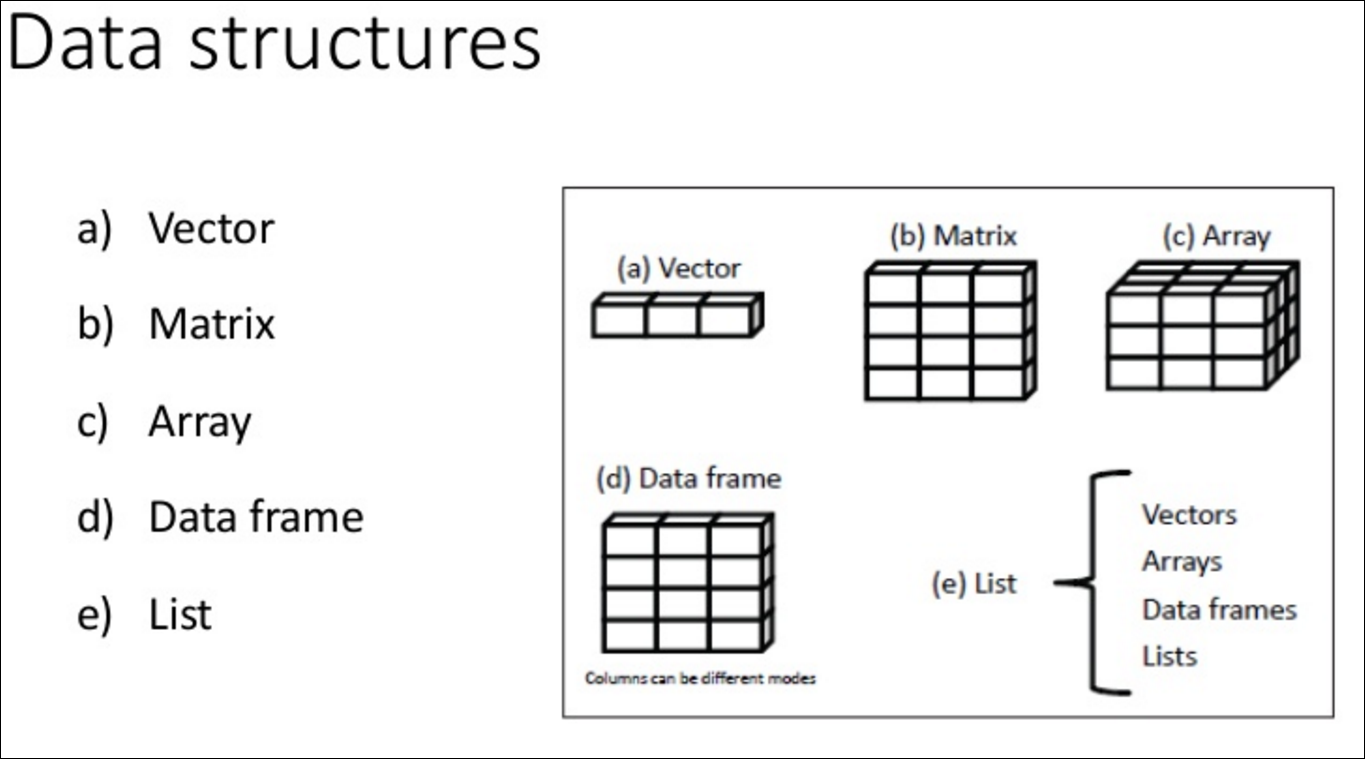
벡터
벡터 생성
1 2 3 4 5 6> c(1, 2, 3) # 숫자타입 벡터 [1] 1 2 3 > c("a", "b", "c") # 문자타입 벡터 [1] "a" "b" "c" > c(TRUE, TRUE, FALSE) # boolean 타입 벡터 [1] TRUE TRUE FALSE
벡터 길이 측정
벡터의 길이를 Length()로 획득 할 수 있다.
1 2 3 4 5 6> x <- c(1, 2, 4) > length(x) [1] 3 > y <- seq(from=1, to=7, by=2) # c(1, 3, 5, 7)과 같은 의미 > length(y) [1] 4
벡터의 Element 선택
아래와 같은 방식으로 벡터의 Element들을 선택할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17> a <- c(1, 2, 5, 3, 6, -2, 4) > a[3] # 3번째 위치의 값을 선택 [1] 5 > a[c(1, 3, 5)] [1] 1 5 6 > a[2:6] # 2번째 ~ 6번째까지 Element 선택 [1] 2 5 3 6 -2 > a[-1] # 1번째 Element를 제외함 [1] 2 5 3 6 -2 4 > a[-(1:3)] # 1번째 ~ 3번째 값을 제외한 Element들을 선택 [1] 3 6 -2 4 > a < 5 # a의 element들이 5보다 작은지 여부를 판단함 [1] TRUE TRUE FALSE TRUE FALSE TRUE TRUE > a[a < 5] # element 값이 5보다 작은 element만 선택 [1] 1 2 3 -2 4 > a[a < 3] [1] 1 2 -2
NA와 NULL의 차이
NA는 값은 존재하는데 무슨값인지 모를때 사용하고 NULL은 값이 없다는 의미이다.
1 2 3 4 5 6 7 8 9> x <- c(88, NA, 12, 168, 13) > mean(x) # 모르는 값이 속해있어 전체평균을 알수 없어 평균을 알 수 없다는 의미이다. [1] NA > mean(x, na.rm=TRUE) # NA값을 제외하여 평균을 계산하는 방법이다. [1] 70.25 > > x <- c(88, NULL, 12, 168, 13) > mean(x) [1] 70.25
유용한 벡터관련 함수 subset과 which
벡터를 다루는데 있어 유용한 함수 2가지를 소개한다. subset()은 벡터에서 조건을 만족하는 벡터를 추출하는데 사용한다. which()는 벡터에서 조건을 만족하는 element의 index를 리턴한다.
1 2 3 4 5 6 7 8 9 10 11> x <- c(6, 1:3, NA, 12) > x[ x > 5] [1] 6 NA 12 > subset(x, x > 5) # 5보다 큰 값을 골라내 부분 벡터로 추려냄 [1] 6 12 > > z <- c(5, 2, -3, 8) > z > 3 [1] TRUE FALSE FALSE TRUE > which(z > 3) # z에서 3보다 큰 element를 가진 index를 리턴 [1] 1 4
행렬
행렬 생성
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15> y <- matrix(1:6, nrow=2, ncol=3) # 값을 1~6까지 할당, nrow로 행을 지정, ncol을 3으로 지정 > y [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > y <- matrix(1:6, nrow=2) # 실제로는 nrow나 ncol중 하나만 쓰면 된다. 왜냐하면 element갯수 + nrow수를 안다면 ncol을 추론할 수 있기 때문 > y [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > m <- matrix(1:6, nrow=2, byrow=TRUE) # R은 기본적으로 열기준으로 값을 채우는데 행 기준으로 채우려면 byrow옵션을 주면 된다. > m [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6
벡터기반 행렬 생성
1 2 3 4 5 6 7 8> cbind(c(1,2), c(3,4)) # column bind의 약자로 열 기준으로 벡터를 합쳐 행렬을 생성 [,1] [,2] [1,] 1 3 [2,] 2 4 > rbind(c(1,2),c(3,4)) # row bind의 약자로 행 기준으로 벡터를 합쳐 행렬을 생성 [,1] [,2] [1,] 1 2 [2,] 3 4
행렬 길이 획득
1 2 3 4 5 6 7> z <- matrix(1:6, nrow=3) > dim(z) # dimension의 약자로 행렬 개수를 리턴한다. [1] 3 2 > nrow(z) # 행 개수를 리턴한다. [1] 3 > ncol(z) # 열 개수를 리턴한다. [1] 2
행렬 Element 선택
1 2 3 4 5 6 7 8 9 10 11 12> y <- matrix(1:6, nrow=3) # 1 ~ 6까지의 값으로 3행의 행렬을 생성 > y[2:3,] # 2행 ~ 3행의 모든 열의 값을 리턴 [,1] [,2] [1,] 2 5 [2,] 3 6 > y[2:3,2] # 2행 ~ 3행의 2열의 모든값을 리턴 [1] 5 6 > y[-2,] # 2행을 제외한 모든 열의 값을 리턴 [,1] [,2] [1,] 1 4 [2,] 3 6 > x <- matrix(c(1,2,3,2,3,4), nrow=3) # c라는 벡터를 이용하여 3행의 행렬을 만듦, 값은 기본적으로 열기준으로 값을 채워넣음
아래 부분은 헷갈릴수 있어 부연 설명을 한다. 우선 x[,2] >= 3를 먼저 생각해보면 모든 행의 2열의 값이 3보단 큰지 확인하는 것이다. 이를 개념적으로 이해하면 x[모든 행의 2열의 값이 3보단 큰 element를 포함한 행, 모든열]을 리턴한다고 이해하면 된다.
1 2 3 4> x[x[,2] >= 3,] # 모든행의 2번째 열의 값이 3보다 크거나 같으면 Element를 포함한 행의 모든열을 리턴함 [,1] [,2] [1,] 2 3 [2,] 3 4
행렬의 row, col에 이름 붙이기
아래와 같은 방법으로 행렬의 row, col에 이름을 붙여 줄 수 있다. 가독성 증가에 의미가 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13> z <- matrix(1:4, nrow=2) > rownames(z) <- c("a", "b") # z 행렬의 row이름으로 "a", "b"를 할당하라는 의미 > colnames(z) <- c("c", "d") # z 행렬의 col이름으로 "c", "d"를 할당하라는 의미 > z c d a 1 3 b 2 4 > rownames(z) # row 이름 확인 [1] "a" "b" > colnames(z) # col 이름 확인 [1] "c" "d" > z["a", "d"] [1] 3
유용한 행렬 관련 함수
앞으로 매우 자주 사용할 apply()함수를 소개한다.
사용법은 아래와 같다.
1apply(X, MARGIN, FUN, ...) # 적용 대상, 행인지 열인지, 적용할 함수를 의미한다.
실제 사용 코드를 보자.
1 2 3 4 5 6 7 8 9 10> z <- matrix(1:6, nrow=3) > z [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 > apply(z, 1, mean) # 1은 행별로 연산하라는 의미 [1] 2.5 3.5 4.5 > apply(z, 2, mean) # 2는 열별로 연산하라는 의미 [1] 2 5
부록 Tip : 파일에서 내용 불러와서 실행
아래와 같은 방법으로 스크립트 편집기로 multi line 입력을 편리하게 이용할 수도 있고 스크립트를 저장/로드 할 수 있다.
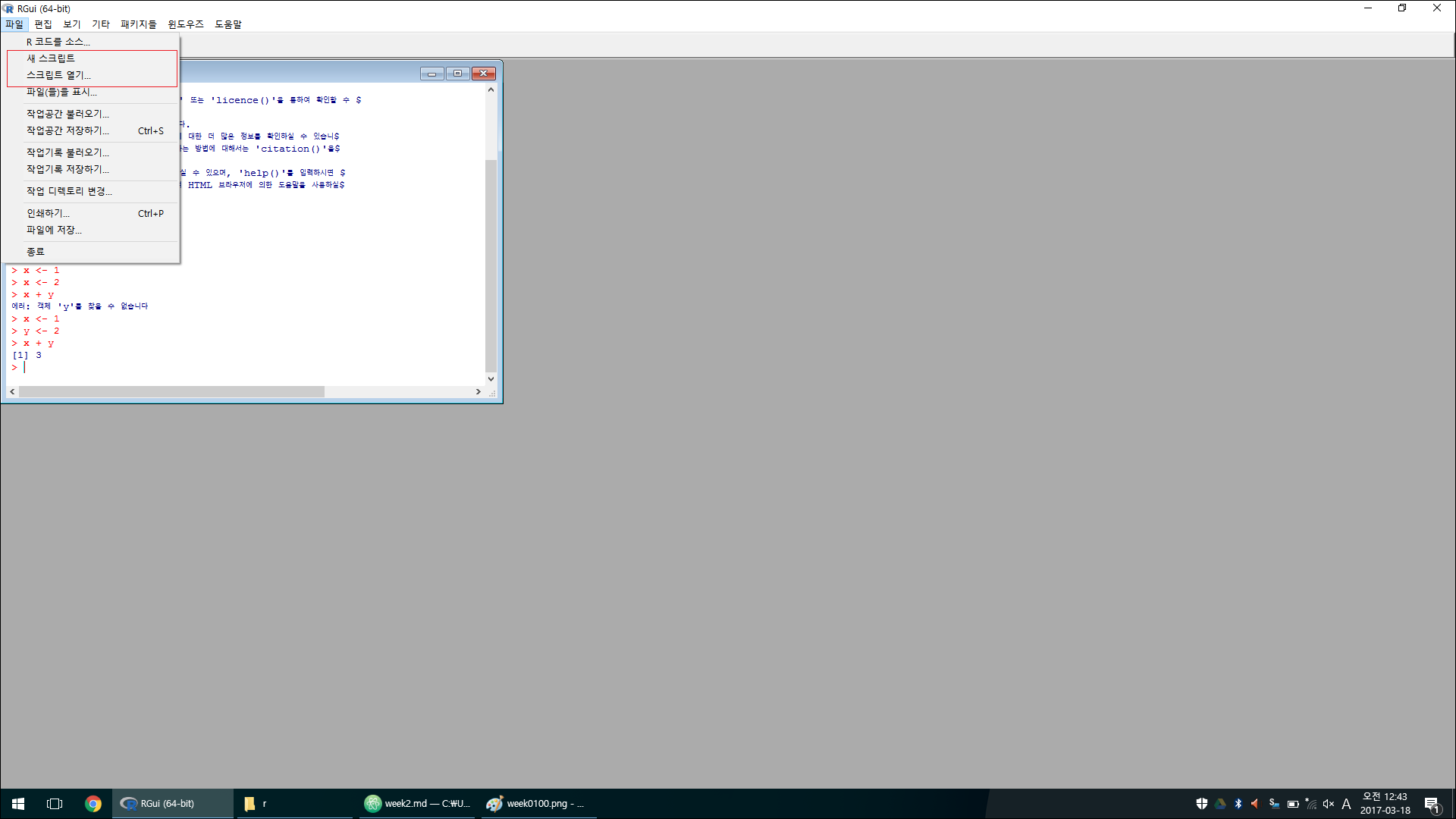
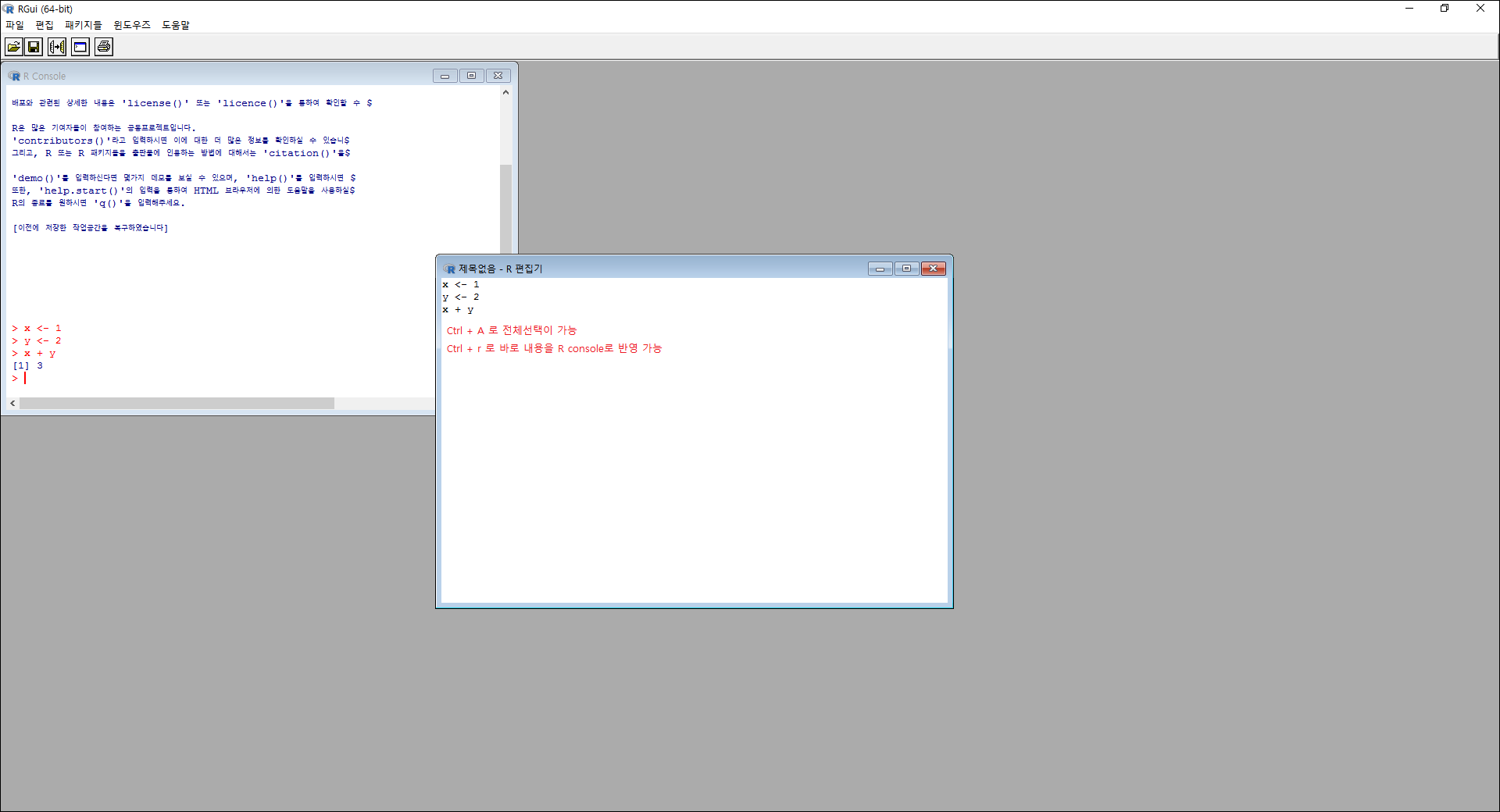
커맨드라인 방식으로는 아래와 같이 이용 가능하다. 필자와 같은 리눅스 사용자는 아래의 방식을 선호할듯 하다.
1 2 3 4 5> source("C:\\Users\\user\\Desktop\\script.r") > x [1] 1 > y [1] 2
