마이크로 서비스 공부하게 책 하나 추천해주세요

한 친구가 이렇게 요청했다. 아래와 같이 바꿔보면 개발자들 사이에서 흔히 들을 수 있는 패턴이다.
OOO 공부하게 책 하나 추천해주세요.
내 동료 장재휴는 이렇게 말했다.
진짜 공부하고 싶으세요? 그러면 팝잇에 있는 글이 제일 좋아요. (돈 들일 필요도 없는데...)
공교롭게 질문을 받기 직전에장재휴가 나에게 말했다. 사람들이 팝잇에 올라온 마이크로 서비스 글이 정말 좋은데, 이는 보지 않고 자꾸 책을 찾는다고...
왜 그럴까? 알 수 없다. :)
마이크로 서비스를 쉽게 익히는 법
없다. 간단히 말해두고 싶다. 굳이 비슷한 대답을 찾는다면, 단지 어떻게 시작할지 알려주는 정도가 있을 뿐이다. 유행처럼 마이크로 서비스를 쫓는 개발자들에게 안타까운 사실은 마이크로 서비스는 모바일앱 개발처럼 눈으로 나타나는 결과를 보고 성취감을 느끼는 성질이 아니란 점이다.
그럼, 어렵게라도 익히는 법
스스로 방법을 찾지 못한 개발자에게 그 길을 알려줄 수 있을까? 장담할 수는 없지만, 이 글의 주제는 그들을 위한 무모한 도전이다. 자 이제 시작해보자. 어떻게 마이크로 서비스를 공부할 것인가?
뚜렷한 목적없이 시작했다가는 지치기 십상이다. 그래서, 먼저 왜 공부하려고 하는지 생각해보자. 뚜렷하지 않으니 스스로 방법을 못찾았을테니 피하고 싶은 질문일 것이다. 하지만, 여기서 인내를 조금 발휘해보자. 안 그러면 학습이라는 미명하에 맹목적으로 아까운 시간을 소비할 수도 있다. 희미한 이유라도 어딘가에 직접 써보자. 쓸 게 없으면 마이크로 서비스 공부를 단념하자. 필요도 없는 것을 막무가내로 배우려는 내 안의 불안감을 이겨내보자.
뭔가 있다면? 그럼, 간단히라도 쓰고 시작하자.
여러분의 목적을 모르니, 글을 쓰기 위해 하나 가정해 본다. 기존에 만들어진 시스템에 마이크로 서비스 도입하면 득이 될까 궁금해서 배운다고 가정하자. 다시 말해, '우버가 했던 일을 우리 서비스에도 적용할 가치가 있을까?' 하는 식이다. 근거도 뚜렷하지 않는데 공부하면서 이미 돌아가는 코드를 수정해서 배포할 수는 없으니 우리 서비스(바꿀 대상)를 흉내낸 모형을 하나 만들기로 한다. 모형을 어렵게 생각할 것 없다. 기존 코드를 복사한 후에 실행과 배포가 쉽도록 불필요한 부분을 제거하면 된다. 그리고, 동작을 확인하면 준비 끝이다.[1]
과학적 아키텍처 검증 방법
다소 거창한 수식이지만, 여러분에게 선명한 기억을 선사하기 위해 다소 거북하게 이름 붙였다. 인터넷 서비스 회사에서 흔히 하는 방법 중에 A/B 테스트라는 것이 있다. 실험 효과를 분명히 하기 위해 실험군과 대조군을 설정하는 것이다. 아마도 중학교때(혹은 더 어려서) 배웠을 법한 내용인데, 우리도 이 방법을 채용하기 때문에 '과학적'이란 수사를 붙였다. 그리고, 여러분이 만든 모형 즉, 기존에 동작하던 코드가 마이크로 서비스를 적용했을 때 좋아지는 특징이 있는지 보려고 한다. 소프트웨어 전문가들 관점으로 말을 바꿔보, 실험군과 대조군을 사용하는 과학적인 방법으로 마이크로 서비스 도입이 아키텍처 측면에 어떤 이점을 주는지 이해하기 위해 마이크로 서비스를 공부하자는 것이 학습 목표로 바뀐다. 참고로 단순히 기능을 바꾸는 것이 아니라 시스템 수준의 특징을 다루는 일은 아키텍처 관련 영역이다.
그래서 과학적으로 하기 위해실험군과 대조군을 만든다. 모형은 그대로 두고, 또 하나 복사한다.
자, 이제 마이크로 서비스 적용 코드를 만들어보자
어떻게 시작할까? 적절한 실험이 되기 위해 새로 짜기보다는 리팩토링이 좋다. 물론, 여러분이 모형의 기능을 충분히 알고 있다면, 새로 짜도 무방하다. 그런데 리팩토링은 생각처럼 쉽지 않다. 새로 짜는 일도 마찬가지다. 지금까지도 어려움을 겪었을지 모르지만, 진짜 어려움은 여기서부터다.
여러움을 극복하는 일이 공부工夫[2]이기 때문에 필자가 대신해줄 수는 없다. 처음에 했던 말이지만 반복하면, 이 글을 쓰는 이유는 마이크로 서비스를 쉽게 배우는 방법은 없고 어렵게라도 배울 수 있는 방법에 대해 안내하려는 목적의 글이다.
시작은 크게 두 가지 길이 있다. 첫번째는 내 동료 장재휴처럼 대강의 개념을 익힌 후에 충분히 이해하지 못해도 아는 범위내에서 용감하게 짜는 방법이다. 꼼꼼한 성격이 아니고 빨리 코딩하기를 좋아하면 추천한다. 두번째는 전형적인 모형을 그대로 따라 하는 방법이다. 천천히 음미하면서 하는 식이 어울리는 사람들에게 추천한다. 참고로 필자는 후자에 가까운 타입이다.
전형은 뭐가 있을까? 필자는 2014년 겨울 QCon SF에서 크리스 리차드슨이 발표한 내용에서 전형을 처음 배웠다. 인터넷 어딘가에 그의 자료가 있고, 얼마전 책도 출간했다. 여기서 그 내용을 설명할 수는 없고, 신기술로 도배(?)한 탓에 따라하기가 만만치 않은데 마침 DZone에Puneet Jindal이 올린 기사가 있어 이를 활용해 간단한 지침 정도만 남겨본다.
마이크로 서비스의 핵심 특성을 다뤄보려면
일단, 여러분의 모형이 하나의 데이터베이스로 이뤄지 있다면 데이터베이스부터 나눠보자. 하나의 맥락Context를 공유하는bounded 프로그램 객체를 Bounded Context라고 부르는데, 구현관점에서는 간단히 정의할 수 있다. 데이터베이스를 물리적으로 나누고, 하나의 모듈(앞서 말한 Bounded Context 단위를 모듈이라고 부르겠다)에서 하나의 데이터베이스만 쓰면 된다. 전에도 인용했던 아래 그림에서 Customer, Catalog, Inventory, Store, Order 등이다. 예제는 유통Retails 사례이기 때문에 여러분 모형과는 차이가 있을 수 있다.[3] 잘 자르려고 필요이상으로 노력할 필요는 없다. 잘못 자르면 일단 프로그램을 수정하다가 알게 된다. 자른 후에도 서로 연동해야 하기 때문에 하다보면 알게 되니까 직관적으로 나누자. 중요한 것은 갈길이 먼데 쓸데 없이 초반에 힘빼지 않는 것이다.[4]
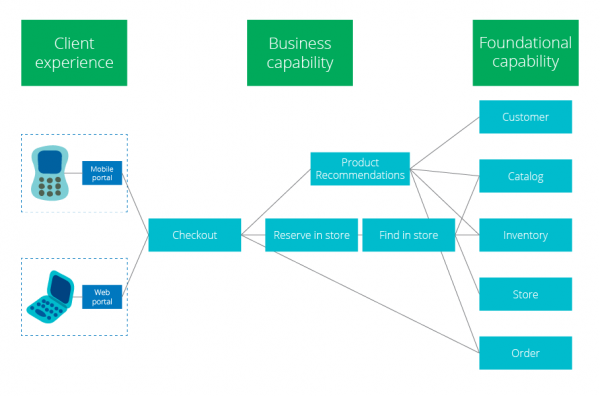
난관에 부딪힐 때 핵심만 살리기
대부분 난관에 봉착하지 않을까 싶다. 동작하는 코드를 만들면서 아래 특징을 살리기 위해서 적절한 수준에서 타협하라.
- How to write code in a single bounded context.
- 프로그램을 층layer으로 나누는 것이 아니라 분산 환경 즉, 네트워크로 연동하는 상황에서 독립적으로 돌아가는 모듈로 만든다는 것이 어떤 의미인가 직접 느껴본다. 모듈내에서 함께 공유하는 맥락bounded context을 굳이 밖으로 노출하지 않는 캡슐화라는 객체지향 설계의 기본을 적용하는 것이다.
- How to break up the entities.
- 모듈 안에서 엔티티Entity 설계하기. 엔티티란 말이 생소하면 테이블 설계라고 봐도 무방하다. 조인해야 하는 테이블이 같은 데이터베이스에 없어질 경우 어떻게 할 것인가를 고민하게 될 것이다. 마이크로 서비스를 채택하면 필연적으로 모듈 밖에 있는 데이터와 모듈 안의 데이터 혼용에 대한 방법을 익혀야 한다. 조인 대신에 API를 통해서 다른 모듈에서 데이터를 받아온 후에 필요에 따라 별도 테이블을 만들어서 저장해야 한다.[6]
- How to become eventually consistent.
- 오호... 지옥(?)에 오신 것을 환영한다. 내 모듈에 처리된 내용이 다른 모듈과 일관성을 유지하려면 어떻게 해야 하나? 알려진 방법으로 TCCTry-Confirm/Cancel 같은 것이 있고, 크리스 리차드슨처럼 상태를 데이터로 저장하지 않고, 이벤트를 저장하는 방법이 있다. 방법은 설명할 수 없으니 왜 이렇게 하는지만 간단히 설명해본다. 여러분이 여행자를 위한 앱을 만든다 생각해보자. 항공권과 렌트카 혹은 호텔까지 묶어서 예약을 해주고 싶다. 항공사와 연결하고, 렌트카 시스템과 연결하고, 호텔 시스템과 연결해야 한다. 이들을 모두 데이터베이스 트랜잭션Transcation으로 처리할 수는 없다.[6]
- Understanding and defining aggregates.
- 앞서 극복한 지옥이 바로 연관관계를 갖는 레코드의 일관성을 보장해주는 방법이다. DDD 에서는 연관관계를 갖는 레코드를 책임지는 객체를 Aggregates라고 부른다.
- Event Sourcing and CQRS.
- 이제 튜닝의 시간이다. 여러분이 여기까지 도착했다면, 존경을 표한다. 남은 문제는 수정과 조회 로직을 분리Command query responsibility segregation하여 캐시 로직 만들기 수월하게 하는 일이다. 조회쪽은 DB 대신 Redis를 쓴다거나 하는 식 말이다. 그리고, 적절한 캐시 갱신 시점을 알 수 있게 해보자. 어떻게 할 수 있나? 어떤 데이터가 수정되었다는 사건을 알리는 객체를 정의해보자. 사건을 표현하는 객체가 바로 이벤트다. 그리고, 한 곳에서 이벤트를 발행Event Sourcing시키고, 캐시 갱신이외에도 Aggregates가 다른 모듈과의 일관성 유지를 위해 필요한 데이터 갱신을 할 수 있게 하자. 그래야 지옥을 통과하며 만든 일관성consistency을 유지시키는 일은 어쩌면 여러분이 고가의 DBMS에 의존[7]했던 과거를 벗어나 새로운 프로그래밍 패러다임에 익숙해지는 활동으로 볼 수도 있다. 이벤트에 의해 일관성이 유지되기 때문에 이런 방식을 Eventual Consistency라고 부르기도 한다. 메시지 구독 형태로 구현하는 방법이 보편적이라 흔히 Kafka 같은 솔루션을 써야 한다.
주석
[1] 직접 해보면 준비가 그렇게 간단하지 않는 경우가 많을 것이고, 이러한 고행 자체가 어쩌면 마이크로 서비스를 배우는 생각지 못한 이득이 될 수도 있다.
[2] 공부 뜻이 그러함을 알려주신 북경잠자리님께 감사를 드린다.
[3] 어떻게 나눠야 할지 감이 없다면 아래 이메일로 데이터모델을 설명해주시면 나눠드릴 수 있다.

소통은 언제나 환영하니 메일 주세요
[4] 필자도 생각이 많은 타입이라 30대에는 불필요한 초반 기획과 설계에 많은 시간을 날렸던 일이 있어 강조한다.
[5] 당연하게도 조인이 사라진다는 말이 아니다. 하나의 모듈 안에서만 조인을 할 수 있다.
[6] 언젠가 페북에서 마이크로 서비스에 대한 이야기를 하는데, 분산 트랜젝션 기술을 언급하는 사람이 있었다. 기술이 더 발전해 IaaS 수준에서 처리해주는 날이 올지 몰라도 현재 수준에서는 분산 트랜젝션을 사용하는 방식은 마이크로 서비스로 보기는 어렵다. 전형적인 통짜monolithic 아키텍처로 분산 시스템을 구축하는 고전적인 방식과 마이크로 서비스는 전혀 다른 것이다.
[7] 여기서는 DBMS의 트랜젝션 관리 기능에 국한해서 의존을 말한 것이다.