머신러닝의 한계?

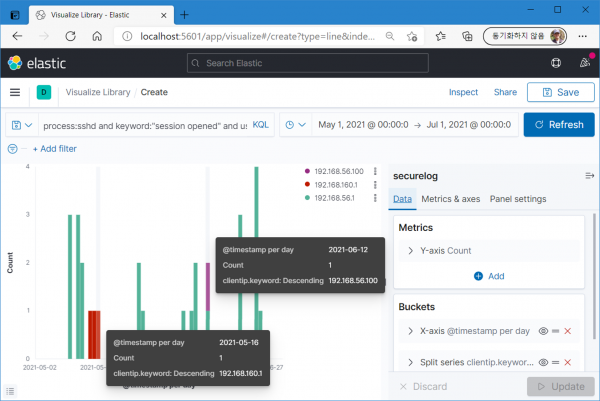
다음은 root 사용자의 IP별 접속 현황. 5월 14~16일 및 6월 12일의 IP 변화가 눈에 띈다.
그런데 사용자가 많다면 사용자별 접속 IP의 변화 확인이 꽤 까다로울 것이다. 더 직관적인, 한 눈에 IP 변화를 알아차릴 수 있는 차트를 그릴 수는 없을까? 다음은 root 사용자의 IP 고유 개수 변화.
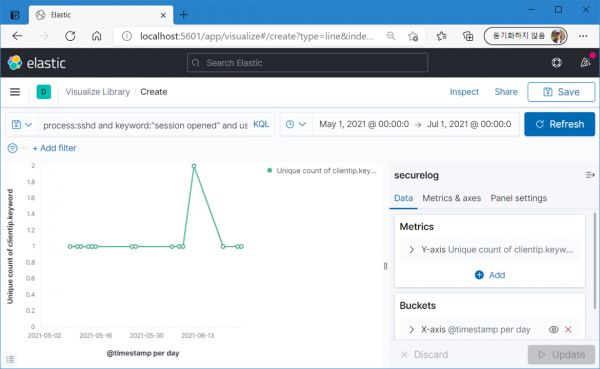
6월 12일의 변화는 뚜렷한데, 5월 14~16일의 변화는 보이지 않는다. 해당 시점의 접속 IP가 평소와 다른 건 맞지만 유형은 하나뿐이니 당연한 결과.
IP 변화를 숫자 변화로
이상징후 분석은 통계 분석의 다른 말이고, 결국 특정 상태의 숫자 변화를 추적하는 과정. 마침 IP는 숫자로도 표현할 수 있다. 8bit 단위로 나눈 IP를 순서대로 2563, 2562, 2561, 2560과 곱한 후, 그 결과를 모두 더해주면 됨. 다음은 ruby 필터를 이용한 계산식.
1 2 3 4 5 6 7 8 9 10 11ruby { code => ' result = 0 squ = 3 for i in event.get("clientip").split(".") result += i.to_i * (256 ** squ) squ -= 1 end event.set("ip_squ", result) ' }
root 사용자의 접속 IP를 숫자로 바꾼 결과는 다음과 같다. 그런데 모두 똑같아 보인다. 그럴리가 없는데?
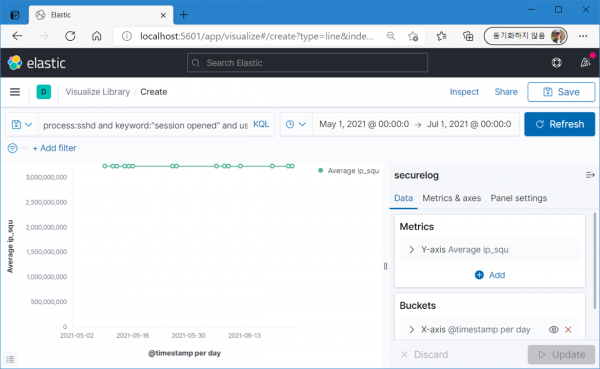
무슨 일인가 싶어 자세히 들여다보니 숫자의 크기 변화는 분명 발생하고 있다. 다만 십억 단위의 크기에서 몇 만 단위의 차이는 너무 작은 차이일뿐(..)
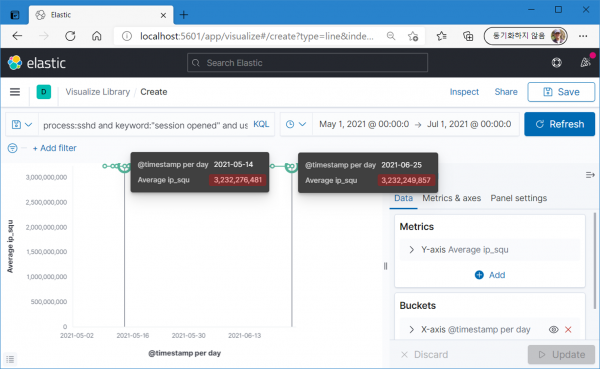
IPv4 환경에서 사용 가능한 약 40억 개의 IP에 순서대로 숫자를 부여하면 특히 같은 대역에 분포하는 IP들의 숫자는 차이가 작을 수밖에 없다.
기계는 이 작은 차이를 알아차릴 수 있을까?
원격 접속에 성공한 root 사용자 조건으로 숫자 변화를 추적하는 single metric job을 만들어봤다.
결과는 기계도 실패(..)
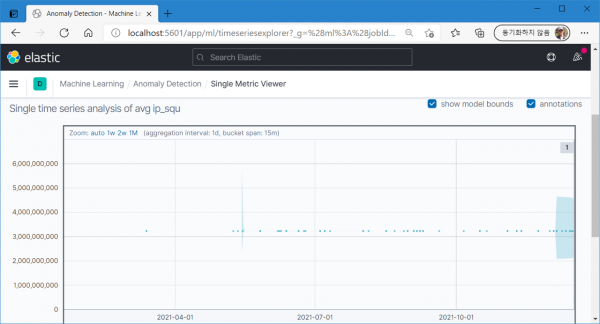
이상징후같은 건 없다 휴먼
Outlier detection은 어떨까?
Anomaly detection과는 달리 5월 14~16일의 변화를 정확하게 잡아낸다. 하지만 6월 12일의 변화는 알아차리지 못함.
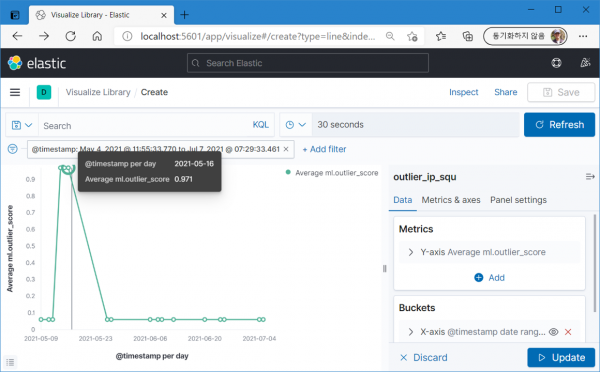
5월 14~16일의 outlier 점수.
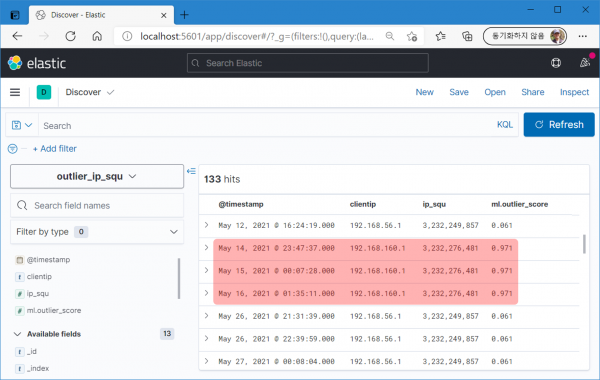
6월 12일의 outlier 점수.
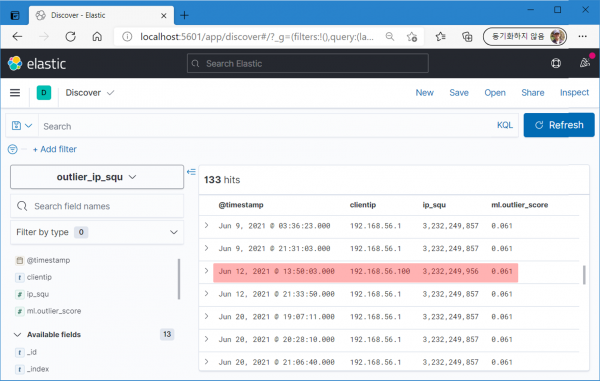
패턴 차원에서 '56.1'과 '56.100'의 차이는 크지만 숫자 차원에서의 차이는 미미하구나. 그래도 outlier 탐지가 anomaly 탐지보다는 숫자 변화 감지에 좀 더 효과적인 듯.
그런데 느낌이 좀 묘하다. 뭐랄까? 머신러닝 하는 짓이 사람과 별 차이가 없어 보인다고나 할까? 계산은 빠르겠지만 숫자를 인식하는 감각은 사람과 비슷해보인다. 사람이 만들었으니 당연한 건가?