아파치 실시간 처리 프레임워크 비교분석 (1)

최근 실시간 처리를 위한 다양한 프레임워크가 오픈되어 있는데, 각 프레웜워크의 특성과 장단점을 비교해 보려고 합니다(원문 : cakesolution.net ).
실시간 분산 처리 프레임워크는, DAGs(Directed Acyclic Graphs)라 불리우는 데이터 처리 모델을 바탕으로, 수초(혹은 ms) 이내에 무한한 데이터의 처리, 집계, 분석을 할 수 있습니다.
DAG는 아래 그림에서 볼 수 있듯이 sources 로부터 sinks 까지의 task 들이 사슬처럼 엮여있는 것에 대한 표현인데, 일반적으로 스트리밍 Job의 Topology 를 설명하는 것으로 사용됩니다. DAG 는 단일 노드에서도 실행, 생성될 수 있으나 이번 글에서는 분산 처리가 가능한 DAG 솔루션 들에 대해서 살펴보도록 하겠습니다.
주요 관심 포인트
분산 스트리밍 플랫폼을 비교 분석하기 위해 보고자하는 주요 관심사항들은 아래와 같습니다.
Runtime and Programming Model
서로 다른 분산 스트리밍 플랫폼을 선택할 때에는 몇가지 주의깊게 살펴봐야할 점들이 있는데, 가장 먼저 Runtime 과 Programming Model 을 보려고 하며, 어떤 Programming 모델을 지원하느냐에 따라 플랫폼의 많은 특성(Features)이 결정되기 때문에 여러가지 사용예를 충분히 검토해야 합니다.
Functinal Primitives
분산 스트리밍 플랫폼에서는, 단일 노드에서 제공되는 기본적인 map, filter 등의 기능(비교적 구현이 쉬움)들 뿐만아니라, 서로 다른 노드의 데이터에 대한 aggregation, join 과 같은 기능들도 제공될 수 있어야 합니다.
State Management
대부분의 애플리케이션은 상태에 대한 관리가 필요하고 플랫폼에서 상태 정보를 관리하고 업데이트 하는 것이 허락되어야 합니다.
Message Delivery Guarantees
메세지 전달 방식에는 Most once, At least once, Exactly once 가 있으며, Most once 는 메세지가 중복을 허용하지 않도록 한번만 전달하는 것을 의미하고, 이로인해 데이터의 유실이 발생할 수 있습니다. At least once 는 여러번의 메세지 전달 시도를 통해 적어도 한번의 메세지 전송 성공을 보장하는 방식이며, 데이터의 중복은 허용하는 방식입니다. 마지막으로 Exactly once 는 정확하게 한번의 메세지 전달이 되어야 하는 방식이며, 중복과 유실 둘다 허용하지 않는 전달 방식 입니다. 비즈니스 환경의 요구사항에 따라 적절히 선택이 가능해야 하며 성능에 매우 많은 영향을 미치는 요소입니다.
Failures
장애 발생은 네트워크, 디스크, 서버 다운 등의 다양한 원인이 있을 수 있으나, 플랫폼은 이와 같은 장애로 부터 큰 영향 없이 복구가 가능해야 합니다.
Latency, Throughput and Scalability
스트리밍 처리 플랫폼에 있어서는 Latency, Throughput, Scalability 모두 성능과 관련이 있는 매우 중요한 요소들 입니다.
Maturity and Adoption Leve & Ease of Development and Ease of Operability
많은 라이브러리들이 있는지, Stackoverflow 에 많은 답변들이 있는지 등 플랫폼의 성숙도를 평가하고, 쉬운 개발과 적용이 가능한지 여부도 중요한 요소입니다.
Runtime And Programming Model
Runime 과 Programming Model 에 따라 처리가 가능한 동작 방식과 제약사항들이 결정되므로, 시스템의 여러가지 특성들 중에 가장 중요한 특성이라고 할 수 있습니다.
Streaming 시스템을 구현하기 위한 두가지 서로 다른 방법이 있는데, 첫번째 방법으로는 유입되는 모든 records, 혹은 events 를 스트리밍 시스템에 도착하는 시점에 하나씩 하나씩 처리하는 Native stream 방식 입니다.
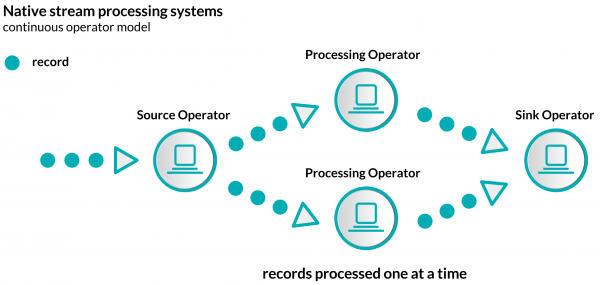
(이미지:http://www.cakesolutions.net/teamblogs/)
두번째 접근 방식은 Micro-batching 이라 불리는 방식이며, 유입되는 records 를 짧은 주기의 batches 처리가 가능한 단위로 묶어서 스트리밍 시스템으로 보내는 방식입니다. 일반적으로 짧은 주기는 수초 정도가 됩니다.
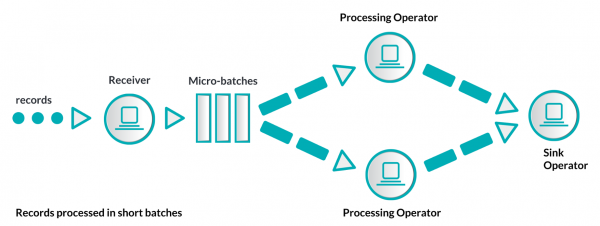
(이미지:http://www.cakesolutions.net/teamblogs/)
두가지 방식 모두 서로 장단점을 가지고 있으며, Native streaming 방식의 최대 장점은 모든 표현(로직 처리)이 가능하다는 점과 데이터가 유입되는 즉시 처리를 하기 때문에 Micro-batching 방식 보다 Latency 측면의 장점이 있다고 할 수 있습니다. 상태 관리에 대한 구현이 비교적 쉬운편이며, 모든 레코드를 각각 처리하기 때문에 Throughput 은 낮고 장애처리를 위한 비용이 크다고 할 수 있습니다. 특정 키를 가지고 파티셔닝 처리를 하기 위한 요구사항이 있을 때에, 특정 키에 전체 데이터가 집중되게 되면 해당 Job 의 병목요소가 될 수있는 단점도 있습니다.
두번째 방식은 Micro-batching 방식이며, 예상할 수 있듯이 작은 단위의 batch 처리로 인해 연산을 수행하는데 있어 표현할 수 있는 로직에 제약을 받게됩니다. 상태관리나 join, split 등의 특정 오퍼레이션의 구현이 상대적으로 어려우며, batch 의 주기는 인프라의 상태와 비지니스 로직에 관계가 될 수 밖에 없는 반면에, 장애복구나 로드밸런싱 등의 구현이 상대적으로 용이한 편입니다.
Programming Model 은 Compositional 과 Declarative 로 나눌 수 있습니다. Compositional 에서는 목표로하는 topology 를 만들기 위해 기본적인 sources 와 operation 을 구축할 수 있는 기능을 제공하며, Declarative API 의 operators 에서는 추상화된 함수형 코드를 작성하거나 topology 를 최적화 하기위한 함수, windowing 함수, 상태 관리 등의 보다 상위 operation 과 function 들을 제공합니다.
Apache Streaming Landscape
다양하고 유용한 플랫폼들이 있지만, 그중에서 Apache Storm과 Storm trident, Spark, Samza, Flink 를 살펴보려고 합니다.
(이미지:http://www.cakesolutions.net/teamblogs/)
Apache Storm 은 2010년 Nathan Marz(BackType 소속) 에 의해서 만들어 졌으며, 그 이후 Twitter 에 의해 오픈소스화 되고 2014년 Apache Top Level 프로젝트가 되었습니다. 의심할 여지없이 Large Scale Streaming Processing 플랫폼의 선구자이며 업계 표준이 되었고, low-level API를 제공하는 native streaming 시스템으로 topology 구현을 위해 다양한 언어를 지원합니다.
Trident 는 Storm 위에 구현될 수 있는 고차원 micro-batching 시스템 입니다. Trident 는 topology 구축 과정을 간소화하고 windiowing, aggregation, 상태 관리 등의 고차원 operation을 쉽게 추가할 수 있습니다. 추가적으로 메세지 전달 방식(글 위쪽에 설명)이 Storm 의 Most once 방식과는 반대로 Exactly once 방식을 제공합니다.
Spark 은 sparkSQL, MLlib, Spark Streaming 을 필두로 최근 가장 인기 있는 batch processing 플랫폼이며, 기본적으로 Spark 의 runtime 은 batch processing 을 할 수 있도록 build 가 되며, micro batching 처리를 할 수 있는 spark streaming 이 약간 뒤늦게 추가가 되었습니다. Spark Streaming 에서는 input data 가 receiver 로 들어오게 되면, micro-batch 들을 생성하여 기본적인 Spark 의 Job 을 처리하는 방식(batch processing)과 동일하게 데이터를 처리하게 되며 Java 와 Scala, 그리고 Python 등의 언어를 지원합니다.
Samza 는 Kafka 와 더불어 LinkedIn 에서 독점적으로 개발한 Streaming 처리 플랫폼이며, 기본적으로 Kafka 의 로그 데이터를 처리한다는 철학을 바탕으로 두개의 플랫폼이 매우 잘 통합되도록 구성되어 있습니다. Samza 는 Compositional API 와 Scala 를 지원합니다.
마지막으로 Flink 는 2008년에 만들어진 꽤 오래된 프로젝트지만, 최근에서야 주목을 받고 있는데, hive-level API를 지원하는 native streaming 플랫폼이며, Spark 과 마찬가지로 batch 처리를 위한 API 역시 지원합니다. Spark 과의 결정적인 차이점은, Flink 에서는 데이터를 batch 단위로 처리하는 것 자체를 꽤 예외적인 케이스로 생각한다는 것에 있습니다.
아래 그림에서 각 플랫폼들의 차이점을 쉽게 볼 수 있습니다.
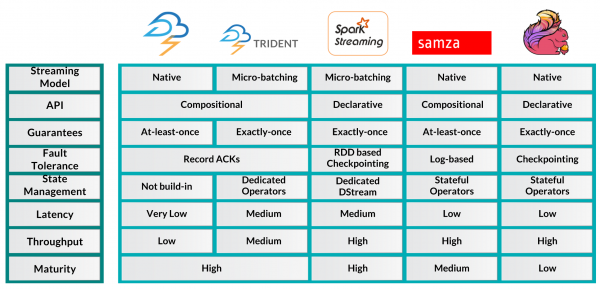
(이미지:http://www.cakesolutions.net/teamblogs/)
Counting Words
Word Count 는 streaming 플랫폼에서의 hello world 와 같은 존재이며, 각 플랫폼들의 차이점을 잘 보여줍니다.
Storm 에서의 예제를 살펴보도록 할텐데, 간단하지만 매우 중요한 부분이라고 생각합니다.
1 2 3 4 5 6 7 8 9 10 11 12TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new Split(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); ... Map<String, Integer> counts = new HashMap<String, Integer>(); public void execute(Tuple tuple, BasicOutputCollector collector) { String word = tuple.getString(0); Integer count = counts.containsKey(word) ? counts.get(word) + 1 : 1; counts.put(word, count); collector.emit(new Values(word, count)); }
첫번째 라인에서는 TopologyBuilder 를 생성하고, 두번째 라인에서 처리를 하기 위한 source 데이터를 받아오기 위해 spout 을 생성합니다. 그리고 나서 toplogy 의 첫번째 bolt 에게 하나의 text를 단어로 split 하고, 또 다른 bolt 에서 단어의 count 를 세도록 topology 를 구성하였습니다.
중간에 섞여있는 5, 8, 12 등의 숫자가 전체 클러스터에서 몇개의 thread 를 통해 분산처리 할 것인지에 대한 정보를 제공하며, 코드에서 볼 수 있듯이 매우 low-level 제어를 하게됩니다. Storm 에서는 상태관리를 위한 지원을 하지않으며, 아래 Trident 에서 지원하는 상태관리 코드와 비교해 보도록 하겠습니다.
1 2 3 4 5 6 7 8 9 10public static StormTopology buildTopology(LocalDRPC drpc) { FixedBatchSpout spout = ... TridentTopology topology = new TridentTopology(); TridentState wordCounts = topology.newStream("spout1", spout) .each(new Fields("sentence"),new Split(), new Fields("word")) .groupBy(new Fields("word")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")); ... }
코드에서 볼 수 있듯이 6번째 줄 each 와 7번째 줄 groupBy 등 보다 고차원 operation 을 사용할 수 있고, 9번째 줄에서 처럼 Trident 가 관리하는 저장소에 count 값을 저장할 수 있습니다.
다음은 Apache Spark 인데, 코드가 매우 간단하며 아래가 Word Count 를 만들기 위한 거의 모든 코드 입니다.
1 2 3 4 5 6 7 8 9val conf = new SparkConf().setAppName("wordcount") val ssc = new StreamingContext(conf, Seconds(1)) val text = ... val counts = text.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.print() ssc.start() ssc.awaitTermination()
모든 Spark Streaming Job 은 StreamingContext 를 필요로 합니다. 위 예제 코드에서는 굉장히 제한된 설정 값들만 표현(batch interval 1초)되었으나, 실제로는 더 많은 설정들을 사용할 수 있습니다. 6~8째 줄에 WordCount 의 모든 연산코드가 있는데, 매우 간단하며 이것이 Spark 이 때때로 분산 스칼라라고 불리는 이유이기도 합니다. 코드에서 볼 수 있듯이 매우 표준화된 function 들을 바탕으로 topology의 분산 실행을 위한 구현이 가능하며, 12번째 라인에서 실제 분산코드가 실행됩니다.
다음은 대표적인 Compositional API 방식을 지원하는 Apache Samza 입니다.
1 2 3 4 5 6 7 8 9class WordCountTask extends StreamTask { override def process(envelope: IncomingMessageEnvelope, collector: MessageCollector, coordinator: TaskCoordinator) { val text = envelope.getMessage.asInstanceOf[String] val counts = text.split(" ").foldLeft(Map.empty[String, Int]) { (count, word) => count + (word -> (count.getOrElse(word, 0) + 1)) } collector.send(new OutgoingMessageEnvelope(new SystemStream("kafka", "wordcount"), counts)) }
Toplogy 의 정의는 Samza 의 property 파일에 정의되어있으나 위의 예제에서는 찾을 수 없습니다. 중요한 점은 kafka topic 과 통신하여 input 과 output 채널을 정의하여야 한다는 점 입니다. 위의 예제에서 WordCountTask 가 전체 Topology 를 구성하는 class 이며, StreamTask 를 상속받아 구현되어야 할 메소드를 overide 하였습니다. 실제 구현 코드는 8~10째줄에 있는 간단한 Scala 코드 입니다.
마지막으로 Flink 의 코드인데, Spark streaming 코드와 매우 유사하게 보이지만, batch 주기를 설정하는 부분이 없습니다.
1 2 3 4 5 6 7 8val env = ExecutionEnvironment.getExecutionEnvironment val text = env.fromElements(...) val counts = text.flatMap ( _.split(" ") ) .map ( (_, 1) ) .groupBy(0) .sum(1) counts.print() env.execute("wordcount")
보시다시피 코드 자체가 꽤 직선적으로 표현되어 있으며, Flink 는 몇개의 function 을 통해 분산 처리 자체에 집중하고 있습니다.
Conclusion
아파치 오픈소스 프로젝트에 활성화되어있는 실시간 처리 플랫폼에 대해 기본적인 이론과 특성을 살펴보았는데, 비즈니스 요구사항에 따라 적절한 플랫폼을 선택하여 구현하면, 많은 양의 데이터를 실시간으로 분산처리 할 수 있는 인프라를 구성할 수 있습니다. 최근에는 실시간 플랫폼에 머신러닝 알고리즘을 올리는 방향으로 기술진화가 되고 있을 정도로 단순 통계 처리에서 보다 복잡한 알고리즘 구현이 실시간 처리를 통해 구현되고 있는 추세이며, Spark MLlib 을 주의깊게 살펴볼 필요가 있겠습니다.