모두 거짓말을 한다


구글 트렌드로 미국 인종차별 실체를 밝혔다가 구글에 채용됐다는 세스 스티븐스 다비도위츠의 2017년 저서.
제목에 끌려서 골랐는데 구글 검색 데이터가 사람들 예측에 유용하다는, 그리 새롭지는 않은 내용. 대신 저자 유머 코드가 나랑 좀 맞아서 지루하지 않게 읽을 수 있었다(..) 이 책은 저자가 구글 트렌드로 인종차별 지도를 그리면서 시작한다.
2008년 버락 오바마의 대통령 당선은 유구했던 미국 인종차별주의 퇴색의 방증이라는 의견이 많았었다. 그런데 웬걸, 같은 기대를 했던 저자가 구글 검색어를 뒤져보니
구글 트렌드에 처음 '깜둥이'를 입력해봤을 때가 기억난다... 그 말이 얼마나 모욕적인가를 고려했을 때 나는 검색량이 적으리라고 생각했다. 틀린 생각이었다. (18페이지)
그렇게 그려진 인종차별 지도는 트럼프의 정치적 성공을 설명하는 데도 유용했다고.
트럼프의 지지율이 높은 지역은 '깜둥이'라는 구글 검색이 가장 많았던 지역 (25페이지)
기존 언론은 물론 선거 결과 잘 맞추기로 소문난 네이트 실버조차 당선까지는 예상하지 못했다.
한창 줏가를 올리던 빅데이터로 무장한 그들은 왜 틀렸을까?
사람들은 거짓말을 한다
저자는 사람들의 생각이나 행동을 예측하기 위해 데이터를 수집하는 과정에 근본적인 문제가 있다고 얘기한다. 선의나 평판을 목적으로 사람들이 너무 쉽게 거짓말을 한다는 것.
사람들은 대부분 자신이 도덕적으로 바람직하게 비춰지기를 바란다. 웬만한 똥배짱 아니고는 비도덕적, 저급한 언사 및 인물 등에 대한 동조 의사를 드러내지 않는다는 얘기. 어떻게 하면 진실을 말하게 할 수 있을까? 익명성을 제공해주면 된다. 사람이 아닌, 벽에다 대고 얘기하는 거라고 믿게 해주면 된다. 그게 바로 검색창.
사람들은 친구, 연인, 의사, 설문조사원은 물론 자기 자신에게도 거짓말을 한다. 하지만 구글에서는 섹스 없는 결혼생활, 정신건강 문제, 불안감, 흑인을 향한 적대감에 관해 다른 곳에서는 내놓기 힘든 정보를 공유한다. (35페이지)
공감한다. 최근에 지극히 개인적인, 남과 공유하기엔 솔직히 꺼림칙한 키워드인 '똥 굵기'를 망설이지 않고 검색한 적이 있다. 배가 자꾸 나와서 저녁량을 줄였더니 그런 게 궁금해지더라(..) 저녁량 늘리면 뱃살과 함께 바로 원상복귀 -_-
검색창은 사람(?)이 아니니 나를 모를 거라는 기대, 내 검색이 나로 특징지어지지 않을 거라는 막연한 기대가 있기에 가능한 일. 누구나 비슷한 경험 한 번쯤은 있지 않을까?
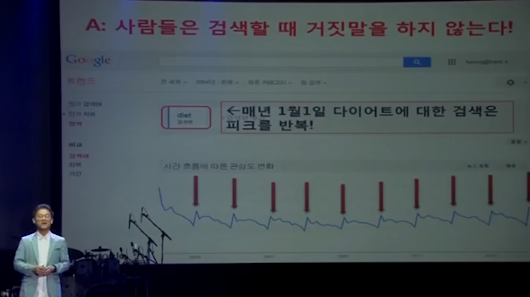
정하웅 교수가 이미 2014년에 다 한 말
결과적으로 검색 데이터는 나보다 더 나를 속속들이 잘 알고 있을 수 있다. 빅브라더 탄생 그래도 사랑해 구글 사람을 예측하는 데 이만한 데이터가 없다는 얘기.
그래서 검색 데이터가 최고?
사실 트럼프 지지율이 높았던 지역이 흑인 비하 검색량도 높았다는 스토리는 너무 매력적이라 감히 반박할 엄두가 나지 않는다. 하지만 '트럼프 지지자 = 인종차별주의자'일까?
성공한 사람들 중 노력하지 않은 사람은 없다. 그럼 노력하면 다 성공할 수 있을까? 로또에 당첨된 사람은 모두 로또를 샀으니, 나도 로또를 사면 당첨될 수 있을까? (네 이 책도 상관성과 인과성을 헷갈리지 말라는 얘기를 합니다.)
적절한 양의 알콜을 섭취하는 사람이 더 건강한 경향이 있다... 그것이 상관관계. 이것이 적절한 양의 술을 마시면 건강이 개선된다는 인과관계를 의미? 건강하기 때문에 적정한 양의 술을 마시는 것일 수도...
적절한 음주와 건강 모두에 작용하는 독립 요인이 있을 수도 있다. 어쩌면 친구들과 많은 시간을 보내는 것이 적절한 알콜 소비와 건강으로 연결된 것일 수도... (239페이지)
하나의 현상에는 상호작용하는 수많은 변수들이 존재한다. 결국 모든 변수의 관계를 모르는 상태에서 일부만 보고 전체를 판단하는 것은 그냥 운에 맡기는 것과 별반 다르지 않을 것이다. 그러니
자신의 연구에 대해 겸손해야 하고 자신이 찾아낸 결과와 사랑에 빠지지 말아야 한다 (287페이지)
음, 결국 연구자가 똘똘해야 한다는 얘기인가?-_- 결과를 계속 의심하면서 더 정확한 변수를 찾으라는 얘긴데 돈, 시간, 데이터도 받쳐줘야 하니 연구자만 똘똘해서 될 일은 아닌 듯(..)
사람을 분석하는 건 참 어려운 일인 것 같다. 하긴 거짓말이라곤 1도 모르는 컴퓨터(IDS 넌 빼고) 분석도 어려워 쩔쩔 매는데 사람 분석하는 게 어디 쉬울까.
나가며
"마약 밀수업자를 100번 중 80번 정확하게 확인할 수 있는 모델을 구축할 수 있다면, 그 모델이 20퍼센트의 불행한 사람들을 끊임없이 괴롭힐 터... 우리가 무엇을 계산하고 있으며 왜 그 계산을 하고 있는지에 대한 생각을 멈추지 말아야 한다. " - 벌거벗은 통계학 (197페이지)
"우리는 더 나은 가치를 알고리즘에 포함시키고, 윤리적 지표를 따르는 빅데이터 모형을 창조해야 한다. 그렇게 하려면 가끔은 이익보다 공정성을 우선시해야 한다. " - 대량살상 수학무기 (337 페이지)
빅데이터 유행 이후 출간된 많은 책들이 빅데이터의 부작용을 경고한다. 이 책도 빅데이터 남용에 의한 비윤리를 걱정한다. 열 명의 범인을 놓치더라도 한 명의 무고한 죄인을 만들지는 말자는 얘기.
그런데 잘 모르겠다. 십원 잃더라도 백원 벌 수 있다면 난 절대 망설이지 않을 것 같은데? 기억에 남는 문구를 남긴다.
인간은 극적인 것에 강한 흥미를 느끼기 때문에 직관에 의지하면 판단이 흔들릴 수도 있다 (49페이지)
사람들이 말하는 것을 믿지 말고 행동하는 것을 믿어라 (183페이지)
검색 데이터는 성난 사람들을 가르치려 하면 오히려 분노가 커질 수 있다고 암시한다. (190페이지)
폭력적인 영화는 폭력성이 잠재된 사람들이 거리에 나가지 못하게 만든다 (224페이지)
우리가 측정할 수 있는 것은 종종 우리가 관심을 갖고 마음을 쓰는 것과 일치하지 않는다 (291페이지)
보안장비 성능에 관심이 쏠리는 이유는 성능과 정확도가 정비례해서일까? 아니면 정확도를 측정하지 못해서일까?