아파치 실시간 처리 프레임워크 비교분석 (2)

이전글 : 아파치-실시간-처리-프레임워크-비교분석 (1)
지난 글 에서는 아파치 프로젝트로 오픈되어 많은 인기를 얻고있는 Storm, Trident, Spark, Samza, Flink 에 대한 기본 특성과 분산 플랫폼의 필수 이론을 살펴보았습니다.
이번 글 에서는 무정지형(Fault Tolerance) 시스템구축, 상태관리, 성능 등의 좀더 깊이있는 주제와 더불어 실시간 스트리밍 처리 플랫폼에 대한 가이드라인 및 추천을 해보려고 합니다.
[toc]
Fault Tolerance
스트리밍 플랫폼에서 Fault Tolerance 한 시스템을 구현한다는 것은 배치(batch) 플랫폼에서의 구현과 비교하여 본질적으로 더 많은 어려움을 가지고 있습니다.
배치 처리 플랫폼에서는 데이터 처리에 실패했을 때 연산에 실패한 부분을 재실행 함으로써 쉽게 해결할 수 있으나, 스트리밍 플랫폼에서는 지속적으로 유입되는 데이터와 365일 실행되고 있는 많은 Job 들로 인해 실패한 부분의 연산을 재실행 하는 것이 쉽지 않게 됩니다. 또다른 어려운 점으로는 상태관리의 일관성을 유지하는 부분이 있는데, 예를들면 날짜가 바뀌는 시점에 실패가 발생하여 현재 상태는 이미 날짜가 바뀌었는데 이전 날짜의 데이터를 처리하여 상태를 참조해야할 경우와 같은일이 발생할 수 있습니다.
설명드린 것처럼 스트리밍 플랫폼에서 Fault Tolerance 한 시스템을 구현한다는 것은 꽤 어려운 일이며, 이러한 부분을 아파치 오픈소스 플랫폼에서는 어떻게 처리하고 있는지 플랫폼 별로 각각 살펴보도록 하겠습니다.
먼저 Storm 은 메세지 처리의 실패에 대한 재처리 작업을 위해 upstream 백업과 record acknowledgements(이하 ACK) 메카니즘을 사용하며, ACK 의 동작방식은 다음과 같습니다.
하나의 operator 는 모든 record 에 대해서 처리가 된 시점에 해당 record 를 보내온 이전 operator 에게 ACK 신호를 전송합니다. Storm Topology 의 source 에서는 생성된 모든 records 에 대해서 백업을 유지하고 있다가 sinks 로 부터 ACK 를 받게되면 record 가 전달된 것으로 판단하고 백업데이터를 폐기할 수 있습니다. 만약 ACK 를 받지 못한 실패 케이스에는 백업을 가지고 있는 source 로 부터 해당 record 를 재처리하게 됩니다.
이러한 방식은 데이터 유실이 없는 것을 보장하지만 중복이 발생할 수 있는 것을 허용하는 메카니즘이며 이러한 데이터 전달 방식을 At least once 라고 부릅니다. 개발자는 필요에 따라 중복제거에 대한 고민을 해야하며, 모든 레코드에 대한 ACK 처리 등으로 인해 매우 낮은 throughput 을 보이는 문제와 더불어 flow control 의 어려움이 존재하는 점 등이 Storm 데이터 처리 메카니즘의 단점이기도 합니다.
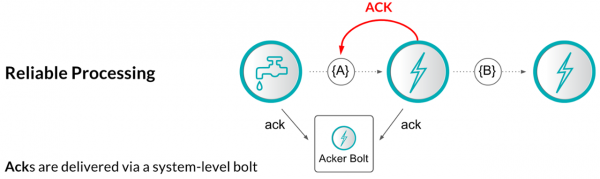
(그림 : Storm's Reliable Processing)
Spark Streaming 에서는 실패한 Task 에 대한 재처리를 전혀 다른 방식으로 진행하며 그 방식은 매우 간단합니다. 이전글 에서 설명 했듯이 Spark Streaming 은 micro-batching 방식으로 짧은 주기의 batch 처리 방식으로 서로 다른 Worker 노드에서 데이터 처리를 하게되며, 각각의 batch job 에 대해서는 성공하거나 실패하거나 둘 중 하나의 상태로 관리를 하게됩니다. 따라서 실패를 한 micro-batch job 에 대해서 새로운 Worker 노드에게 재실행 할 수 있도록 관리를 하게되며, 정확히 한번만 데이터를 전달하는 방식을 쉽게 구현할 수 있습니다.
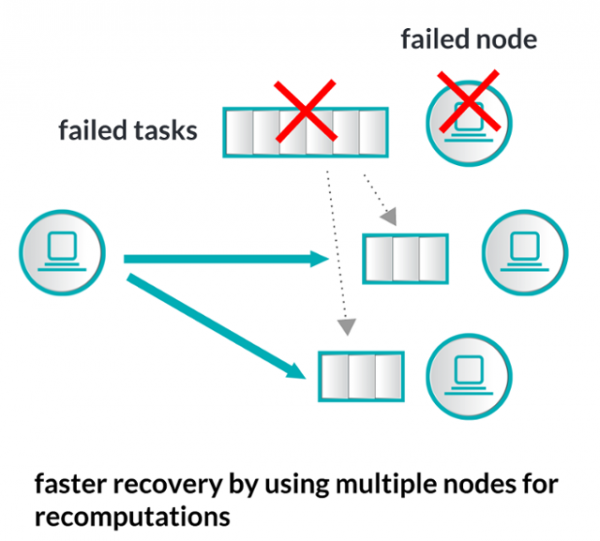
(그림 : Spark Streaming's Reliable Processing)
Samza 의 접근방식 또한 완전히 다른 방식인데, offset 기반의 메세징 시스템을 활용하며 일반적으로 Kafka 를 사용합니다.
Kafka 는 아래 그림에서 처럼 input stream 의 partition 별로 offset을 저장하는데, Samza 는 이 offset 값을 모니터링 하다가 데이터 처리를 실패하게 되면 이 offset 값을 참조하여 실패한 데이터에 대한 재처리를 하게 됩니다. 문제는 offset 이 기록된 이후 새로운 offset 을 남기기 전까지 어떤 메세지까지 처리되었는지를 알 수 없게 되며, 장애 발생 시 offset 시점 이후 데이터를 재처리 하게되면 두번씩 처리되게 되는 경우가 발생할 수 있습니다(이러한 데이터 전달 방식을 At least once 라고 부릅니다).
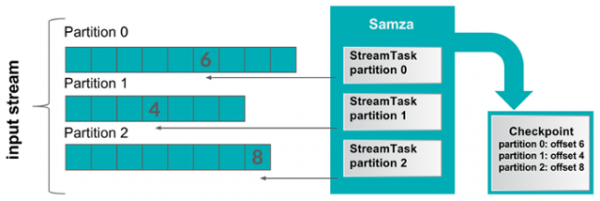
(그림 : Samza's Reliable Processing)
마지막으로 Flink 는 Streaming Job 의 상태를 유지하는 분산 스냅샷을 기반으로 합니다. Flink 는 일종의 마커라고 할 수 있는 checkpoint barrier 들을 전송하고 각 operator 들은 해당 checkpoint 에 해당하는 stream 데이터를 처리하게 됩니다. Storm 과 비교하자면 모든 레코드에 대한 ACK 처리를 하지 않아도 되기 때문에 보다 효율적이라고 할 수 있으며 Spark 의 micro-batching 방식과는 다르게 여전히 native streaming 개념을 고수하는 플랫폼 입니다. Flink 의 데이터 전달 방식은 Exactly once 입니다.
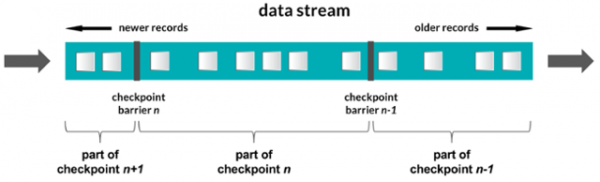
(그림 : Flink's Reliable Processing)
Managing State
대부분의 스트리밍 플랫폼에서는 일종의 상태 관리를 하게 됩니다. 하나의 input 이 처리되고 output 결과로 나오게되면, 각각의 상태가 변경되며 데이터 처리가 실패한 경우에도 상태관리가 되어야 합니다. 데이터 처리의 실패 여부에 따라 재처리되는 과정에서 일부 records 들은 여러번 재처리 될 수도 있으며, 이로인해 발생하는 데이터의 중복 문제는 일반적으로 우리가 원하는 데이터 전달방식(Exactly once)이 아닙니다.
위에서 살펴봤듯이 Storm 은 최소한 한번 데이터를 전달해주는 것에 대한 보장을 하는데, 정확히 한번 데이터 전달을 해주는 요구사항을 만족시키기 위해 Storm Trident 를 사용할 수 있으며 records 를 commiting 하는 방식(transaction 처리를 의미)을 사용하게 됩니다. 개념적으로는 매우 간단한 방식이지만 모든 records를 transaction 처리하는 것은 효율적이지 않기 때문에 작은 배치 단위로 처리하는 것이 가능하며 이부분에서 최적화를 해야할 요소들이 있습니다.
Trident 는 정확히 한번만 데이터를 전달하는 것을 보장하기 위해 아래 표와같은 추상화 개념을 정의하고 있으며, 관련하여 약간의 제약들이 있는데 자세히 파악하기 위해서는 많은 시간이 걸립니다(시간이 허락할 때 별도의 포스팅을 하겠습니다).
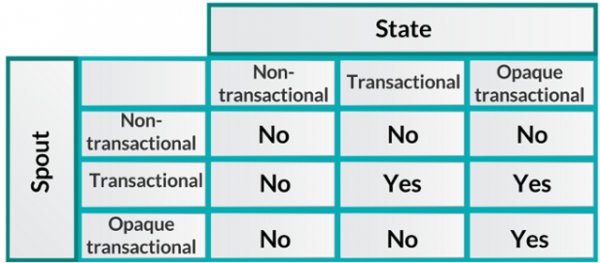
(그림 : Strom Trident 의 추상화 개념 테이블)
스트리밍 프로세싱 시스템에서 상태관리 오퍼레이터들을 생각해 볼 때, 여러개의 레코드를 하나의 스트림으로 처리하는 것을 생각해 볼 수 있지만, micro-batching 시스템인 Spark Streaming 은 이와는 다른 방식으로 처리됩니다. 기본적으로 Spark Streaming 에서는 현 상태를 또 하나의 micro-batching 스트림으로 간주하여, 모든 Spark의 micro-batch 프로세스는 현재 상태와 오퍼레이션 함수를 받아들여 각 batch 가 수행된 결과와 상태를 업데이트합니다.
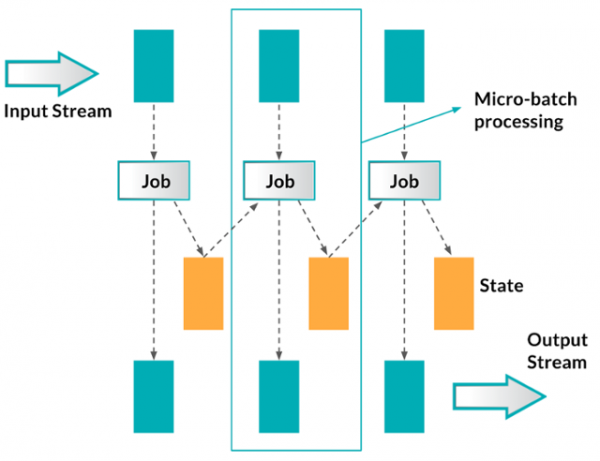
(그림 : Spark's Reliable Processing)
Samza 의 해결책은 모든것을 Kafka 에 넣는 것이며 그것으로 상태 관리를 포함한 모든 문제가 해결됩니다.
Samza 는 상태의 변화 로그 자체를 Kafka 에 넣을 수 있는 상태관리 오퍼레이터들을 가지고 있습니다. 필요하다면 상태정보를 Kafka 의 Topic 으로 재생성할 수 있으며, 로컬 저장소를 스토리지로 사용하는 key-value 저장소를 플러그인으로 사용할 수 있어서 모든 것을 Kafka 로 보내야 하는 것을 하지 않을수도 있습니다.
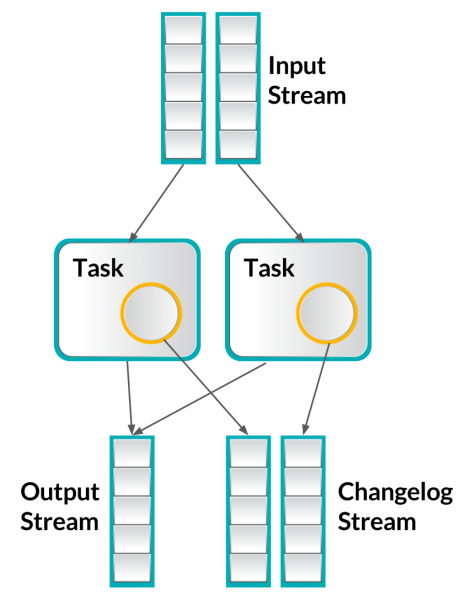
(그림 : Samza's Reliable Processing)
Flink 는 단계별 오퍼레이터를 제공하는데 개념적으로는 Samza 와 비슷합니다. Flink 를 사용할 때 두가지의 서로 다른 단계별 유형이 존재합니다.
첫번째는 로컬 시스템의 하나의 오퍼레이터에서 실행되는 여러개의 Task 들 중 하나의 Task 에 대한 상태를 말하며 서로 다른 Task 간에는 서로 상호작용 하지 않습니다. 그리고나서, 프로그래밍 상에서 정해진 Key 의 상태에 따라 파티셔닝되고 이를 통해 생성된 전체 파티션의 상태를 관리하게 됩니다.
Flink 는 정확하게 한번 의미를 전달하는 방식을 지원하며, 아래 그림에서 3개의 로컬 Task 에 대한 상태를 갖는 오퍼레이터의 그림을 확인할 수 있습니다.
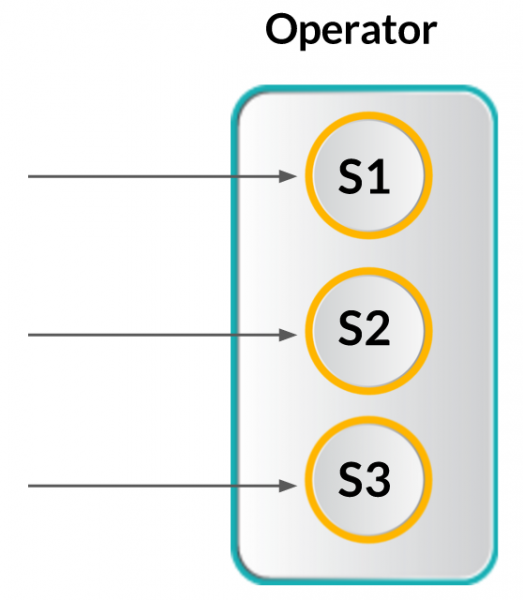
(그림 : Flink's Reliable Processing)
Counting Words with State
스트리밍 플랫폼에서의 Hello World 와 같은 예제인 WordCount 예제를 상태관리의 측면에 집중해서 살펴보도록 하겠습니다.
먼저 Storm Trident 입니다.
1 2 3 4 5 6 7 8 9public static StormTopology buildTopology(LocalDRPC drpc) { FixedBatchSpout spout = ... TridentTopology topology = new TridentTopology(); TridentState wordCounts = topology.newStream("spout1", spout) .each(new Fields("sentence"),new Split(), new Fields("word")) .groupBy(new Fields("word")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")); ... }
9번 라인에서 처럼 persistentAggregate 함수를 호출하는 것으로 상태를 생성할 수 있으며 중요한 변수는 숫자를 저장하기 위한 Count 입니다. 만약 데이터를 처리하기 위해서라면 Stream 을 생성해야 합니다.
다음은 Spark 의 예제코드 입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14// Initial RDD input to updateStateByKey val initialRDD = ssc.sparkContext.parallelize(List.empty[(String, Int)]) val lines = ... val words = lines.flatMap(_.split(" ")) val wordDstream = words.map(x => (x, 1)) val trackStateFunc = (batchTime: Time, word: String, one: Option[Int], state: State[Int]) => { val sum = one.getOrElse(0) + state.getOption.getOrElse(0) val output = (word, sum) state.update(sum) Some(output) } val stateDstream = wordDstream.trackStateByKey( StateSpec.function(trackStateFunc).initialState(initialRDD))
우선적으로 초기 상태로 RDD 생성을 해줘야 합니다(2번 라인). 그리고나서 약간의 변환(5~6번 라인)을 하고, 그 이후로 8~14번 라인에서 단어와 단어의 카운트와 더불어 상태변환 함수(state.update)를 이용한 상태 관리를 하게 됩니다.
연산이 끝나면 상태를 업데이트하고 결과를 리턴합니다. 그리고 마지막으로 16~17 라인에서 모든 데이터를 함께 전송하고 단어의 카운트를 포함한 스트림의 상태를 가져오게 됩니다.
Samza 의 코드를 살펴보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16class WordCountTask extends StreamTask with InitableTask { private var store: CountStore = _ def init(config: Config, context: TaskContext) { this.store = context.getStore("wordcount-store") .asInstanceOf[KeyValueStore[String, Integer]] } override def process(envelope: IncomingMessageEnvelope, collector: MessageCollector, coordinator: TaskCoordinator) { val words = envelope.getMessage.asInstanceOf[String].split(" ") words.foreach { key => val count: Integer = Option(store.get(key)).getOrElse(0) store.put(key, count + 1) collector.send(new OutgoingMessageEnvelope(new SystemStream("kafka", "wordcount"), (key, count))) } }
가장먼저 상태에 대한 선언(3번 라인)이 필요합니다. 위 예제의 경우에는 key-value 저장소이며 5~8 라인에 초기화 선언을 한 후 연산을 수행합니다. 코드에서 볼 수 있듯이 매우 직선적으로 표현되는 편입니다.
마지막으로 Flink 의 API 를 살펴보겠습니다.
1 2 3 4 5 6 7 8 9 10 11val env = ExecutionEnvironment.getExecutionEnvironment val text = env.fromElements(...) val words = text.flatMap ( _.split(" ") ) words.keyBy(x => x).mapWithState { (word, count: Option[Int]) => { val newCount = count.getOrElse(0) + 1 val output = (word, newCount) (output, Some(newCount)) } }
코드에서는 6번 라인에서 단지 mapWithState 함수를 호출하였고, 하나의 argument 와 두개의 parameter 를 포함합니다. 첫번째 것은 단어를 카운트하기 위해서이며, 두번째 것은 상태 관리를 위해서 입니다.
Performance
합리적인 성능 비교는 하나의 글로 표현이 되어야 하기 때문에, 이번 글 에서는 인사이트 관점에서 살펴보겠습니다.
각각의 플랫폼에서 명백하게 다른 특성의 문제 해결방법들을 가지고 있기 때문에, 성능 측정에 있어서 완벽하게 공정한 테스트를 설계하는 것은 매우 어려운 일 이지만, 스트리밍 플랫폼의 성능을 얘기하기 위해 throughput 과 latency 두가지를 살펴볼 수 있습니다. 이것 또한 매우 많은 변수에 의존관계가 있지만 최대한 간단한 Task 를 통해 평가할 수 있는 기준은, 노드 하나에 초당 5만 의 레코드를 처리하면 ok, 100만 레코드면 nice, 100만 이상이면 great 로 평가할 수 있으며, 노드의 사양은 24 cores 에 메모리 24 또는 48GB 정도로 일반적인 사양으로 가정할 때 입니다.
Latency 측면에서, micro-batch 시스템은 일반적으로 수초 이내를 의미하며, native streaming 시스템은 수백 millis 단위 이하를 의미하는데 Storm 과 같은 플랫폼에서는 쉽게 그 값을 수십 milis 단위로 조정할 수 있습니다.
데이터의 전달방식과 상태관리, fault tolerance 설정도 성능에 많은 영향을 미치는 요소인데, 예를들어 falut-tolerance 기능을 on 했을 경우 10~15% 의 비용(성능저하)이 발생하게되며, Storm 에서는 70% thoughput, Spark 50%, Flink 25% 정도로 차이가 나는데 언제나 그렇듯이 좋아지는 점과 나빠지는 점이 공존하게 됩니다.
이것은 이전글에서 살펴봤던 상태관리가 없는 WordCount 예제와 이번글에서 살펴본 상태관리가 있는 예제를 통해 비교해 볼 수 있으며 당연히 상태관리가 없는 예제가 빠른 성능을 나타냅니다.
분명한 것은 이러한 플랫폼 성능이 여러가지 시스템적 튜닝 요소를 가지고 있으며, 성능의 이득을 가져올 수 있는 사항들을 꾸준히 찾고 개선해야 한다는 것 입니다.
분산 플랫폼의 성능과 관련하여 역시나 가장 중요한 개념중에 하나는, 데이터 처리과정에서 네트워크를 통해 전송되는 비용이 매우 비싸다는 것이며 이를 위해 데이터의 로컬리티를 살릴 수 있는 튜닝이 애플리케이션의 성능을 향상시키는데 중요한 요소라는 것 입니다.
Project Maturity
플랫폼을 고를 때에는 항상 그 플랫폼의 성숙도를 살펴봐야 하며, 몇가지를 빠르게 살펴보도록 하겠습니다.
Storm 은 스트리밍 시스템의 주류에 해당하며 Twitter, Yahoo, Spotify 등 많은 기업이 사용하는 업계 표준 시스템 이었습니다.
Spark 은 스칼라의 인기를 업어 최근 가장 유행하는 플랫폼이라고 할 수 있으며, Netflix, Cisco, DataStax, Intel, IBM 등 Spark 을 적용하는 회사들이 증가하고 있습니다.
Samza 또한 Linked In, Netflix, Uber 등을 비롯한 수십여개의 회사에서 사용하고 있으며, Flink 는 이제 막 떠오르는 프로젝트이지만 곧 첫번째 적용사례를 볼 수 있을것으로 보이며 그 증가 추세는 매우 빠를 것으로 확신합니다.
플랫폼 성숙도를 평가할 수 있는 또다른 지표로 프로젝트의 contributor 수를 볼 수 있는데, Storm & Trident 는 약 180명, Spark 은 720명, Samza 는 40명, Flink 는 130 명 이상의 contributor 가 있습니다.
Summary
프레임워크의 추천으로 가기전에 아래 테이블에서 각 플랫폼간의 특성을 비교해볼 수 있는 매우 유용한 정보를 확인하실 수 있습니다.
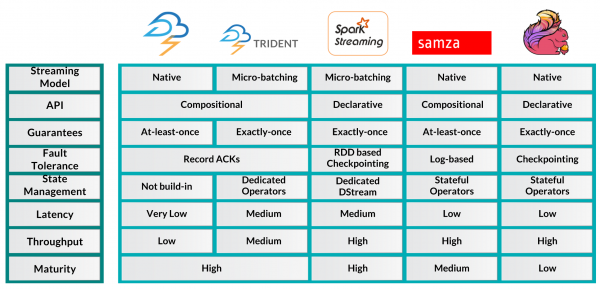
Framework Recommendations
매우 전형적인 답변일 수 있는데, "어떤 플랫폼을 사용하는 것이 좋은가?" 에 대한 답변은 상황에 따라 다를 수 있다는 것 입니다.
항상 요구사항을 명확히 평가하고 어떤것이 중요한가에 따라 적절한 플랫폼을 선택해야 하는데, 개인적으로는 보다 우아하고 효율적인 기능 제공이 가능한, 고차원 API 지원 플랫폼을 고르라는 말을 해주고 싶습니다.
또한, 대부분의 스트리밍 애플리케이션들은 상태 관리의 필요성이 있는데, 보다 쉽게 Exactly once 전달 방식을 구현할 수 있는 플랫폼을 추천하고 싶습니다. 그러나 실제로 이 모든것은 요구사항에 따라 달라질 수 있습니다.
마지막으로 스트리밍 플랫폼에서는 장애 발생 시 복구를 하는 것이 쉽지 않기 때문에, 문제가 발생했을 경우 빠르게 복구가 가능한지에 대한 확인도 중요한 요소라는 것을 말씀드립니다.
Storm 은 작고 빠른 Task 들을 수행하기에 매우 적합한 플랫폼 입니다. 만약 시스템 요구사항 중에 Latency 가 굉장히 중요한 요소라면 Storm 이 매우 좋은 해결책이 될 수 있습니다. 그러나 fault tolerance 와 trident 의 상태 관리 기능 등은 플랫폼 성능을 매우 저하시킬 수 있는 요소라는 것을 알아야 합니다. 재미있는 옵션은 Twitter 에서 Storm 의 단점을 보완하기 위해 개발하고 있는 Heron 이라는 프로젝트가 있으며 Storm Topology API 를 유지하고 있다는 점 입니다.
Spark 플랫폼이 이미 당신의 인프라에 구축되어 있는 상태라면, Spark Streaming 을 사용하는 것을 고려해 보는 것이 좋습니다. 왜냐하면 많은 Spark 라이브러리들을 그대로 사용할 수 있으며 Lamda 아키텍처를 손쉽게 구현할 수 있기 때문입니다. 단, micro-batching 방식의 한계점들과 느린 latency 에 대해서 고려해 볼 필요가 있겠습니다.
당신의 시스템 아키텍처에 Samza 를 고려한다면, Kafka 와 같은 offset 을 관리하는 큐가 그 주춧돌이 될 수 있으며, 여러가지 플러그인 형태의 다른 플랫폼을 고려할 수 있지만 가장 좋은 방법은 Kafka 를 사용하는 것 입니다. Samza 는 로컬 저장소의 파워풀한 사용과 더불어 많은 상태를 쉽게 관리함으로 인해 수십 GB 이상의 데이터를 쉽게 처리할 수 있지만, at least once 전달 방식으로 인한 데이터 중복 발생에 대한 부분을 고려해 봐야 합니다.
Flink 는 개념적으로 거의 대부분의 스트리밍 유즈케이스를 만족시킬 수 있는 매우 훌륭한 스트리밍 플랫폼 입니다. 또한 windowing, time handling 등 경쟁 플랫폼에서는 아직 구현되지 않은 진보적인 기능들도 제공합니다. 따라서 Spark 과 같은 micro-batching 시스템에서 구현하기 힘든 기능이 필요할 때 고려해 볼 수 있으며, batch 프로세싱을 위한 API 를 제공하는 것 또한 매력적인 부분입니다. 하지만 다른 플랫폼 대비 레퍼런스가 적고 관심을 받기 시작한지 오래되지 않은 프로젝트라는 것을 감안한다면 적용을 하는데에 있어 어느정도 용기(?)가 필요할 수도 있습니다. 또한 시작된지 오래된(2008년) 프로젝트 이다보니 앞으로의 로드맵을 확인하는 것도 필요합니다.
Conclusion
이번 글(시리즈 2편) 에서는 아파치 오픈소스 프로젝트들 중 인기 있는 실시간 데이터 처리 플랫폼들의 비슷한 점과 차이점, 그리고 여러가지 상황에 따른 장단점 등을 살펴봤습니다.
무엇보다 실시간 데이터 처리 플랫폼의 특성을 잘 파악하여 요구사항에 맞는 적절한 시스템과 기능구현이 중요하며 여러분들의 람다 아키텍쳐 구성 진행에 있어 조금이나마 도움이 되었으면 좋겠습니다.
관련글