업그레이드를 부르는 Hadoop 3.0 신규 기능 살펴보기

최근 아파치 하둡 홈페이지에 Hadoop 3.0.0 alpha1 도큐먼트가 공개되면서, 오픈소스 빅데이터 기술의 "아버지" 급이라 할 수 있는 하둡의 3.0 릴리즈에 대한 기대감을 더하고 있습니다. 하둡 3.0 에서 추가되는 주요 특성 및 기능들에 대해 살펴보고 사용자 관점에서 달라지는 의미를 정리해 보았습니다.
[toc]
Java Version
하둡 3.0 에서 요구하는 최소 자바 버전은 기존 Java 7 에서 Java 8 로 변경 되었습니다. 아직 프로덕션 환경의 자바 메인 버전을 Java 7 로 사용하고 계시다면, 다가오는 하둡 3.0 적용을 위해 Java 8 로의 업그레이드를 고려해 보시는 것이 좋겠습니다.
Support Erasure Coding in HDFS
Erasure Coding 은 안정성을 보장하는 데이터 저장 방식의 하나로, 일반적으로 3배의 오버헤드를 갖는 HDFS 의 복제 방식(replica 3)과 비교하여 약 1.4배의 오버헤드 만으로 데이터를 저장하는 것이 가능합니다. 데이터 저장을 위해 원천 데이터의 3배 크기 저장 공간이 필요하다는 것은 하둡을 통하여 비용 효율적인 인프라 구성을 하는 부분에 있어 가장 공격을 당하는 요소 중 하나 였는데, Erasure Coding 기능을 배포함으로 인해 이러한 논란은 완전히 종결될 것으로 보이며, 현재 운영중인 하둡 클러스터의 저장공간 확보에도 크게 도움이 될 것으로 생각됩니다.
저장공간 부족에 허덕이는 상황에서 개인적으로는 3.0 주요 기능 중 가장 기대되는 Feature 이지만, 기존 운영중인 하둡 클러스터를 업그레이드하여 해당 기능을 배포할 때에는 기존 HDFS 에 저장되어 있는 전체 파일에 대하여 Erasure Coding 방식으로의 재구성이 필요하므로, 이 때 발생하는 네트워크 비용과 CPU 연산에 따른 부하를 고려하는 것이 중요하겠습니다. 하지만 추가적인 투자 없이 현재의 HDFS 저장공간이 2배가 뻥튀기 된다는데, 업그레이드를 하지 않을 수 있을까요? ^^
YARN Timeline Service v.2
YARN Timeline Service v.2 에서 달라지는 주요 특성을 살펴보기 이전에, YARN Timeline Service v.1 에 대한 간단히 살펴보겠습니다.
YARN Timeline Server 는 running application 과 completed application 의 일반적인 정보, 예를들면 queue-name, user information 등과 같은 정보(ApplicationSubmissionContext 에 존재하는 정보)를 Resource Manager 의 history store(기본적으로 file system) 에 저장합니다. 이렇게 저장된 정보는 TimelineClient 에서 REST API 를 통해 ApplicationMaster 또는 Application Container 에게 쿼리로 요청될 수 있으며, 이를 통해 얻은 정보를 바탕으로 Application 의 다양한 정보를 확인하거나 UI 로 표현할 수 있습니다.
YARN Timeline Service v.2 에서는 v.1 에서 가지고 있던 두가지 큰 문제점을 개선했는데, 첫번째는 데이터의 쓰기와 쓰기를 HBase 를 활용하여 분산처리 함으로써 확장성과 신뢰성을 확보한 것이며, 두번째는 flows 와 aggregation 을 통해 YARN 애플리케이션에 대한 단계별 정보를 확인하는 기능의 사용성을 개선한 것 입니다.
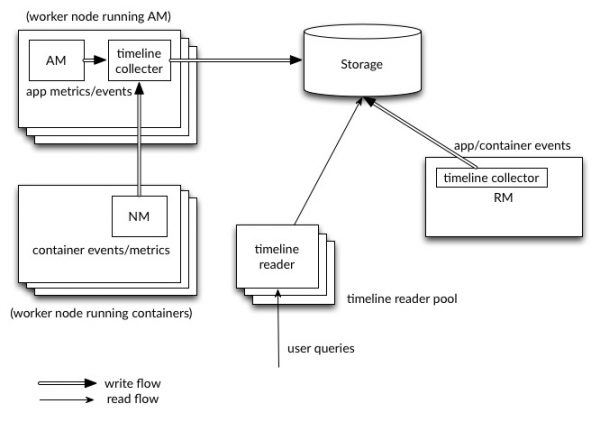
(그림출처 : 아파치 도큐먼트)
위의 Timeline Service v.2 의 아키텍처 그림에서 볼 수 있듯이, 각각 독립된 AM(Application Master)와 같은 노드에 위치한 timeline collector 들은 Storage 로 표현된 HBase 클러스터에 각각의 app 에 대한 metrics/events 들을 분산 저장할 수 있습니다. RM(Resource Manager) 또한 자기 자신의 timeline collector 를 유지하면서 YARN 의 일반적인 라이프사이클 등의 정보를 HBase 에 저장합니다. Timeline reader 또한 timeline collector 와는 분리된 별도의 데몬들로, REST API 를 통해 받은 유저의 쿼리를 HBase 로부터 조회하여 결과를 전달하는 서비스를 제공합니다.
아래는 서로 다른 YARN 엔티티 사이의 모델링 flow 들의 관계를 설명하는 다이어그램 입니다.
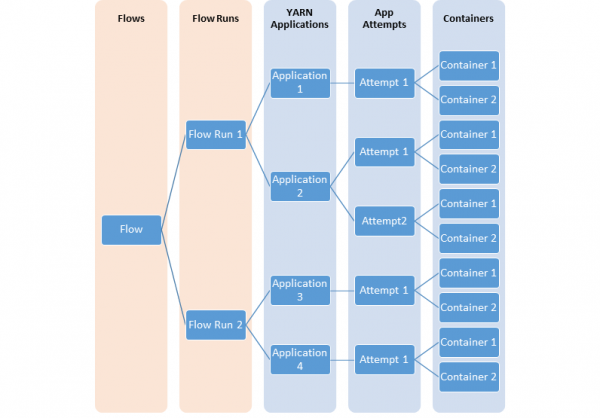
(그림출처 : 아파치 도큐먼트)
대부분의 사용자들은 위 그림과 같이 YARN 애플리케이션의 flows 혹은 논리적인 레벨 기준의 정보를 알기 원합니다. 이번 업그레이드를 통해 위의 flows 기준의 metrics 에 대한 aggregation 까지 지원을 하기 때문에 YARN 애플리케이션 들의 각 단계별 상태 정보를 수집/관리하고 최적화를 하는데 있어 매우 도움이 될 것으로 생각됩니다.
YARN Timeline Service v.2 에서는 사용자와 개발자에게 새 버전을 테스트할 수 있도록 기능을 제공해주며 v.1.x 를 쉽게 대체할 수 있는 제안과 피드백을 제공해 줍니다. 하지만 유의할 부분은 security 기능이 아직 미구현 상태이며, security 가 중요한 요구사항으로 존재하는 환경에서는 해당 기능을 셋업 해서는 안됩니다.
Shell script Rewrite
하둡 쉘 스크립트는 오랫동안 존재하던 버그를 수정하기위해 약간의 새로운 기능을 포함하여 새롭게 재작성 되었습니다. 반면 반드시 확인해야 할 중요한 부분은 기존 설치된 쉘 스크립트 버전과 호환성 유지가 되지 않는 점들이 존재한다는 것이며, HADOOP-9902 이슈에서 자세한 내용을 확인할 수 있습니다.
쉘 스크립트에 대한 더 자세한 정보는 UNIX Shell Guide 문서 와 UNIX Shell API 문서 를 통해 확인하시면 되겠습니다.
MapReduce task-level native optimization
MapReduce 수행 시 셔플 과정에서 발생하는 map output collector 의 정렬 부분을 C++로 구현된 native 프로그램을 JNI(Java Native Interface) 로 호출하는 것을 지원하기 시작하면서 약 30% 이상의 성능개선을 이루었다는 내용입니다.
일반적인 MapReduce Job 의 성능 튜닝은 셔플 과정에서 발생할 수 있는 네트워크 트래픽 전송의 양을 적절한 Combiner 의 구현을 통해 줄여주는 것과 특정 Reducer 로 데이터가 집중되지 않을 수 있도록 적절히 Partitioner 를 구현해 주는 것을 생각해 볼 수 있습니다. 하지만, 이와 같은 튜닝은 MapReduce 의 알고리즘 특성과 데이터의 성격을 잘 알고 있는 개발자에 의해 튜닝이 가능한 내용이지만, Sorting 과정에서 발생하는 성능 저하는 Java 로 구현된 하둡 플랫폼 자체의 Dependancy 를 갖는 요소이기 때문에 개발자 입장에서 튜닝이 어려운 부분 이었습니다. 3.0 업그레이드에서는 하둡 플랫폼 레벨에서 성능 튜닝 요소가 들어가면서 특히나 셔플 과정에 많은 데이터를 처리하는 Job 에 대해서는 많은 성능 개선 효과가 있을 것으로 기대 됩니다.
아래 표는 200GB 의 Test 데이터를 TeraSort 와 WordCount 를 수행했을 때의 결과 표 입니다.

MapReduce 가 Hive 를 비롯한 수 많은 Query 엔진들의 편의성에 밀리는 것은 사실이지만, 여전히 복잡한 Business Logic 구현이 필요한 Batch Job 구현에는 많이 사용되고 있습니다. 따라서 MapReduce 의 성능 개선 또한 매우 중요한 업그레이드 특성 중 하나라고 볼 수 있겠습니다.
Support for more than 2 NameNodes.
하둡 2.x 의 HDFS NameNode HA 는 하나의 Active NameNode 와 하나의 Standby NameNode 로 구현 되어 있습니다. 하지만, Active NameNode 의 서버 혹은 프로세스 등의 장애상황이 발생하거나 소프트웨어/하드웨어 업그레이드를 통한 계획된 클러스터 재구동 상황에서도 Active 혹은 Standby NameNode 가 정상화 되는 시간까지, 전체 하둡클러스터는 서비스를 할 수 없는 장애상황을 맞이하게 됩니다. 이러한 상황은 클러스터를 운영하면서 증가하게되는 파일과 블록의 갯수, 그리고 네임스페이스 이미지의 크기가 커지면서 다운타임 시간이 점점 길어지게되는 치명적인 상황을 초래합니다.
하둡 3.0 에서는 두개 이상의 NameNode 를 Running 상태(Active/Passive)로 운영할 수 있는 설정이 가능합니다. HA 방식은 Quorum Journal Manager (QJM) 를 이용하는 방식과 Network File System (NFS) 를 이용하는 두가지 방식이 있는데, 자세한 내용은 HDFS HA 문서에서 확인하실 수 있습니다.
Active NameNode 가 Standby NameNode 로 Fail Over 되는 시간 동안의 다운타임 발생은 하둡을 기반으로 내부 데이터 분석이 아닌 서비스를 하고자 하는 인프라 구성에 있어서 가장 치명적인 약점 이었습니다. 하둡 3.0 에서 Active/Passive NameNode 설정을 통해 NameNode Fail Over 시 발생하는 다운 타임을 최소화 할 수 있다면, 현존하는 하둡의 가장 큰 약점 중 하나가 사라진다고 볼 수 있겠습니다.
Default ports of multiple services have been changed.
이전 버전 에서는 여러 하둡 서비스의 기본 포트가 리눅스 임시 포트 범위 (32768-61000) 에 있었습니다. 이로인해, 서비스를 시작할 때 종종 다른 응용 프로그램과의 충돌로 인해 서비스 포트에 바인딩하는 것에 대한 실패를 경험하게 되는데, 이러한 충돌 포트들이 임시 범위 밖으로 이동 되었습니다. 변경된 포트 리스트는 아래와 같습니다.
- Namenode ports: 50470 --> 9871, 50070 --> 9870, 8020 --> 9820
- Secondary NN ports: 50091 --> 9869, 50090 --> 9868
- Datanode ports: 50020 --> 9867, 50010 --> 9866, 50475 --> 9865, 50075 --> 9864
- KMS server port : 16000 --> 9600
Support for Microsoft Azure Data Lake filesystem connector
하둡 3.0 에서는 Hadoop-compatible filesystem 으로 Microsoft 의 Azure Data Lake 를 지원합니다. Azure 를 사용하시는 분들께는 좋은 소식이 될 수 있겠습니다.
Intra-datanode balancer
하나의 DataNode 에는 보통 여러개의 디스크를 운용합니다. 정상적인 쓰기 상황에서는 각 디스크에 균등한 양의 데이터 쓰기 동작이 발생하게 되는데, 디스크 교체나 추가 등의 예외 상황이 발생하게 되면 하나의 DataNode 내에 데이터가 불균형하게 저장됩니다. 기존 HDFS 의 balancer 에서는 이러한 상황을 핸들링 할 수 없었지만, 새로운 버전의 CLI 에서는 hdfs diskbalancer 명령어를 호출하는 것으로 해결할 수 있습니다.
자세한 명령어는 HDFS Commands Guide 에서 확인하실 수 있습니다.
Reworked daemon and task heap management
MapReduce tasks 뿐만 아니고 Hadoop 데몬들을 위한 Heap 사이즈 관리에 대한 변화들이 존재합니다. HADOOP-10950 에서 자세한 내용을 확인할 수 있는데 host 의 메모리 크기에 따라서 자동으로 Heap 사이즈를 튜닝하도록 설정할 수 있으며, 기존에 존재하던 HADOOP_HEAPSIZE 설정은 deprecated 되었습니다. HADOOP-10950 에서 더 자세한 내용을 확인해 보시기 바랍니다.
Map 과 Reduce task 의 Heap 사이즈 설정은 간편화 되었고, heap 사이즈는 더이상 task 의 설정이나 Java 의 옵션으로 구체화 될 필요가 없습니다. 이미 기존에 존재하던 설정들은 이번 업데이트에 영향을 주지 않습니다. 자세한 내용은 MAPREDUCE-5785 에서 확인하시기 바랍니다.
결론
아직 정식 릴리즈가 아니지만, Major 버전의 업그레이드 이니만큼 많은 변화가 있습니다. 무엇보다 하둡 자체의 근간이라 할 수 있는 HDFS 와 MapReduce 의 기본 체계가 변화하는 부분을 포함하여 저장 공간을 추가적인 투자없이 늘릴 수 있는 점, 그리고 운영 환경에서의 네임노드 장애로 인한 다운타임 발생 시간의 단축이 가능한 점 등, 하둡을 운영하시는 관리자 분들의 선택은 업그레이드를 하는것과 안하는 것의 선택이 아닌, "언제 해야 하는가?" 의 선택만이 남아 있다고 평하고 싶습니다. ^^