코드 복잡도 줄이기 (Cyclomatic Complexity, NPath Complexity)

이번 포스팅도 어떤 백엔드 서비스의 코드를 리팩터링한 내용을 정리하는 것으로, 이번에는 코드 복잡도 줄인 리팩터링에 대한 내용을 정리한다.
이전에 포스팅했던 '가변 Context 클래스는 신중하게 사용하자'와 '고차 함수로 의존성 줄이기'로 코드의 의존성 문제들이 많이 정리된 상태라서 복잡도 줄이기를 진행할 수 있었다.
아래는 어떤 백엔드 서비스 코드의 리팩터링 전과 후의 코드 복잡도 Cyclomatic Complexity와 NPath Complexity의 수치 변화다. 많이 줄어든 것을 볼 수 있다.

실제로 작업했던 코드를 기반으로 소개할 수는 없으니, 일반화해서 조금은 억지스러운 예제로 만들어 내용을 정리한다.
전체 코드는 여기에 있다.
코드 복잡도
코드 복잡도를 수치로 계산하는 방법들이 많이 있겠지만, 그중에서 Cyclomatic Complexity(이하 CC)와 NPath Complexity(이하 NPath)를 공식 등은 생략하고 골격만 간단히 소개한다. 더 자세한 내용은 아래를 참고 바란다.
- https://en.wikipedia.org/wiki/Cyclomatic_complexity
- https://modess.io/npath-complexity-cyclomatic-complexity-explained/
- 순환 복잡도 - 소프트웨어 아키텍처 101 번역서 (118p)
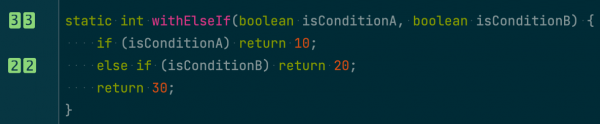
아래와 같이 골격만 간단히 정리할 수 있다. 물론, 위의 세부적인 계산식과 다른 수치가 나올 수 있지만 코드의 상태를 쉽게 가늠할 수 있다. CC는 함수에 제어문(분기, 루프 등)이 없다면 1점, 있다면 제어문마다 1점이며 조건식 안에 논리식도 1점이고 각 점수를 더한다. NPath는 코드를 실행할 수 있는 비순환 경로의 수로 말이 어려운데, 분기마다 2점이고 각 점수를 곱한다. 2점이 아닌 케이스도 있는데 if / else if 조합은 실행할 수 있는 경로의 수가 3이다.
IntelliJ를 사용한다면 Complexity reducer Plugin을 설치하면 아래와 같이 CC와 NPath를 계산해서 보여준다. 다만, 해당 플러그인이 IntelliJ 213.* 버전까지만 지원하여 최신 버전에서는 동작하지 않는다.
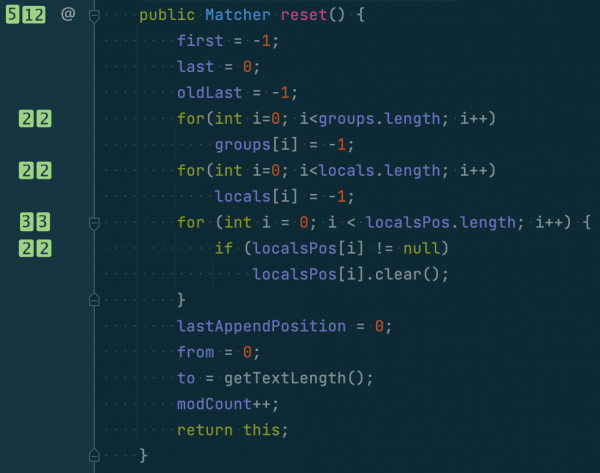
java/util/regex/Matcher.java in adoptopenjdk-11
위 코드를 보면, CC는 5점(reset + for + for + for + if), NPath는 12점(for * for * (for + if))이다.
여기서 3점이 약간 이상해 보일 수 있는데, for/if 조합의 실행 경로는 for를 안 타는 경우, for를 타고 if를 안 타는 경우, for, if 모두 타는 경우 3갈래다.
이 내용을 대략 이해하고 아래 예제 코드를 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26public Data buildData(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { int someValue; if (isConditionA) { someValue = 10; } else { if (extraCondition.equals("ForceB") || isConditionB) { someValue = 20; } else { if (isConditionC) { someValue = 30; } else { someValue = 40; } } } Data data = new Data(); data.setA(someValue + 1); if (someValue == 30) { data.setB(someValue + 2); } else { data.setB(someValue + 4); } data.setC(someValue + 3); return data; }
위 buildData() 함수는 CC가 6, NPath가 8이다. 높은 수치는 아니지만, 예제로 더 복잡하게 만들기도 어려우니 이 함수의 복잡도를 줄여보자. 코드 복잡도 줄이기라고 해서 특별한 것은 없다. 기본은 똑같다. 하나의 함수에 많은 코드가 있다는 것은 많은 책임을 가지고 있다는 것이다. 함수의 책임을 여러 함수로 나누면 복잡도 역시 각 함수가 나누어 가지면서 개별 함수의 복잡도는 낮아진다.
함수 추출하기
참고로 함수 추출하기(Extract Function)는 리팩터링 도서에 다양한 케이스에 대해서 자세히 설명되어 있다.
먼저 buildData() 함수는 크게 2가지 책임을 가지고 있다. someValue의 값을 구하고 Data 객체를 생성한다. 이 2개의 책임을 각각의 함수로 추출하자.
someValue의 값을 구하는 부분을 아래와 같이 getSomeValue() 함수로 추출한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18private int getSomeValue(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { int someValue; if (isConditionA) { someValue = 10; } else { if (extraCondition.equals("ForceB") || isConditionB) { someValue = 20; } else { if (isConditionC) { someValue = 30; } else { someValue = 40; } } } return someValue; }
getSomeValue() 함수는 CC가 5, NPath가 4인 함수가 되었다. 그리고, Data 객체를 생성하는 부분도 아래와 같이 makeData() 함수로 추출한다.
1 2 3 4 5 6 7 8 9 10 11private Data makeData(int base) { Data data = new Data(); data.setA(base + 1); if (base == 30) { data.setB(base + 2); } else { data.setB(base + 4); } data.setC(base + 3); return data; }
makeData() 함수는 CC가 2, NPath가 2인 함수가 되었다.
이렇게 buildData() 함수에 몰려있던 코드를 getSomeValue(), makeData() 2개의 함수로 모두 추출하여, 복잡도는 2개의 함수가 나누어 가져갔고, buildData() 함수는 아래와 같이 단출해지면서 코드 복잡도라고 수치로 뽑을 것이 남지 않았다.
1 2 3public Data buildData(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { return makeData(getSomeValue(isConditionA, isConditionB, isConditionC, extraCondition)); }
중첩 조건문을 보호 구분으로 바꾸기
참고로 중첩 조건문을 보호 구분으로 바꾸기(Replace Nested Conditional with Guard Clauses)는 리팩터링 도서에 다양한 케이스에 대해서 자세히 설명되어 있다.
getSomeValue() 함수를 추출하고 보니 더 정리할 수 있을 것 같다. someValue를 제거하자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16private int getSomeValue(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { if (isConditionA) { return 10; } else { if (extraCondition.equals("ForceB") || isConditionB) { return 20; } else { if (isConditionC) { return 30; } else { return 40; } } } }
someValue를 제거하고 모두 return 문으로 치환하고 보니, 중첩된 if 문들을 정리할 수 있을 것 같다.
1 2 3 4 5 6 7 8 9 10 11 12private int getSomeValue(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { if (isConditionA) { return 10; } if (extraCondition.equals("ForceB") || isConditionB) { return 20; } if (isConditionC) { return 30; } return 40; }
한결 보기 편해졌다. 혹시, Complexity reducer Plugin을 활성화해두고 작업을 따라왔다면 중첩된 if 문들을 정리하면서 getSomeValue() 함수의 NPath가 4에서 8로 2배가 증가한 것을 확인할 수 있을 것이다. 코드의 로직은 동일하고 가독성도 좋아졌는데 코드 복잡도를 나타내는 수치가 증가했다.
첫 번째 if 문의 조건이 만족하면 바로 return하여 두 번째 if 문을 타지 않는다는 것을 계산에 포함하지 않고 나온 수치라서 그렇다. 잠시 아래와 같이 수정해 보자.
1 2 3 4 5 6 7 8 9 10 11 12private int getSomeValue(boolean isConditionA, boolean isConditionB, boolean isConditionC, String extraCondition) { if (isConditionA) { return 10; } else if (extraCondition.equals("ForceB") || isConditionB) { return 20; } else if (isConditionC) { return 30; } return 40; }
명확하게 첫 번째 if 문의 조건이 만족하면 두 번째 if 문을 타지 않는다고 조건문으로 명시하면 getSomeValue() 함수의 NPath가 다시 4로 감소하는 것을 확인할 수 있다.
이런 케이스처럼 코드 복잡도 수치가 실제 코드가 가진 복잡도보다 높게 나오는 케이스가 있으니 각 함수의 적절한 가독성을 유지하는 선에서 조율할 필요가 있다.
(원글: https://prostars.net/336)