1인 개발자가 글로벌 서비스를 운영하는 방법 - GGtics

GGtics는 세계적으로 인기 있는 ESports 게임인 "리그 오브 레전드(이하 롤)"의 데이터를 분석하여 게이머의 실력을 객관적으로 평가해줍니다. 저는 이번 글에서 GGtics에 대한 소개와 더불어 1인 개발자 체제로 글로벌 서비스를 운영했던 경험을 나누어보고자 합니다. 또한, 마지막으로 GGtics의 개발자 채용에 관해서 소개하고자 합니다.
. . .
게임 실력을 객관적으로 평가하는 GGtics
GGtics를 처음 만들 때 전 세계 어디에도 게임을 객관적으로 평가하는 기준이 없었습니다. 그래서 GGtics는 많은 시행착오를 겪으며 GG(x)라 부르는 함수를 만들고 개선해왔습니다. GG(x) 함수는 게임 중 발생하는 행위가 승리에 미치는 영향을 수치로 분석합니다. 모든 분석이 끝나면 하나의 숫자를 반환하는데 이 숫자는 기여도를 의미합니다. 이 숫자를 한글 버전에서는 '인분' 영어 버전에서는 'gg'라 부릅니다. 1인분은 딱 기대치만큼 했다는 뜻입니다.
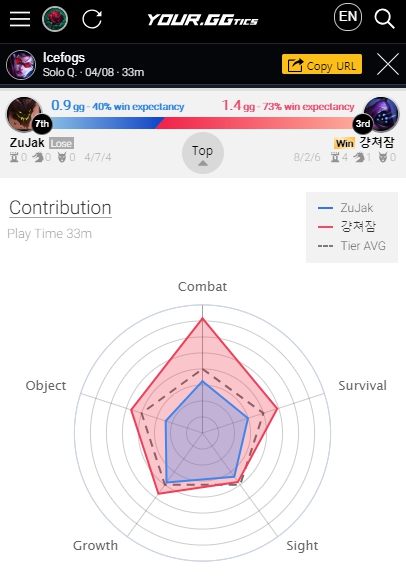
사용자가 게임 후 방문해 본인의 아이디로 검색하면 위 그림처럼 게임 기여도 및 스타일을 즉시 확인할 수 있습니다. 왼쪽 플레이어는 기대치보다 살짝 못한 0.9인분(gg)을 받았고, 경쟁했던 우측 플레이어는 기대치보다 훨씬 높은 1.4인분(gg)을 받았습니다. 이렇게 쉽게 객관적인 평가를 확인할 수 있는 것이 GGtics의 장점입니다.
글 쓰는 시각 기준 월간 약 50만 명의 사용자가 저희 서비스를 이용하고 있습니다. 한 가지 자랑하고 싶은 부분은 마케팅 없이 오직 입소문만으로 성장을 해왔다는 점입니다. 최근에는 입소문이 일본까지 가 일본 사용자도 생겼습니다. 현재 아래 그림처럼 한국, 북미, 라틴 아메리카, 유럽, 러시아, 터키 등 11개 대륙 혹은 국가에 서비스 하고 있습니다. 언어는 현재 한국어, 영어, 일본어를 지원합니다.
. . .
1인 개발자가 글로벌 서비스 운영하기
1인 개발자가 글로벌 서비스를 어떤 방식으로 운영하고 있을까요? 정말 혼자 운영이 가능한 것일까요? 일이 너무 많지는 않을까요? 다양한 변수가 있겠지만 GGtics에서는 가능했습니다. 기획 등의 영역은 뒤로하고 기술적 측면인 '인프라, 백엔드, 데이터 분석, 컴퓨팅' 네 가지 주제로 GGtics가 이 문제에 어떻게 접근하는지 소개해보겠습니다.

인프라 - AWS에 일 위임
더욱 많은 일을 하려면 외부에 일을 위임할 필요가 있습니다. React, Spring, Django 등 프레임워크를 사용해 구조를 만들고 서비스에 필요한 기능만 개발하는 것이 대표적인 예입니다. 그런데 인프라도 이렇게 할 수 있는 세상이 되었습니다. 웹에서의 정적 파일, DB 설치와 운영, 도메인 Redirection 등 예전에 혼자 서비스를 만들 때 직접 처리해야 했던 일을 이제는 AWS에서 제공합니다.
GGtics 역시 인프라를 AWS에 위임합니다. 예로 도메인 Redirection 작업은 이렇게 합니다. 구글에서 "AWS redirection domain"으로 검색하면 AWS의 공식 문서가 나옵니다. 요약하면 AWS 기능을 활용해 설정만으로도 Redirection을 할 수 있다는 내용입니다. 실제 해보면 작업은 약 5분 정도 걸립니다. 작업이 끝나고 브라우저에서 테스트해보면 Redirection이 잘 됩니다. 제가 직접 관리하는 설정이나 소스 코드는 아무것도 변경하지 않고 원하는 결과를 만들었습니다.
또한, AWS 기능 중 RDS(Relational Database Service)를 사용하고 있습니다. RDS를 쓰면 클릭 몇 번으로 DB를 만들 수 있습니다. 게다가 상당한 수준의 안정성과 확장성을 제공하는 MMM (Master-Master Replication Manager for MySQL) 같은 설정도 쉽게 기본 구성으로 포함할 수 있습니다.
RDS에서는 MySQL, PostgreSQL, MariaDB 등 다양한 제품을 지원하는데요. 저희는 Aurora라는 제품을 사용합니다. Aurora는 MySQL 호환 DB로써 Amazon에서 커스터마이징 한 버전입니다. Aurora가 제공해주는 기능 중 가장 매력적으로 느낀 것은 최대 64TB까지 가능한 Storage Scalability입니다. 즉 64TB까지는 저장공간이 자동으로 늘어납니다. 이 정도면 사용자가 폭발적으로 증가해도 용량 걱정 없이 쓸 수 있다고 판단했습니다.
사실 서비스 초기에는 RDS에 대한 거부감이 있어 MySQL을 직접 설치해 사용했습니다. 그런데 제 예상보다는 서비스가 잘 되어 보수적으로 잡았던 DB 서버의 디스크 용량을 언제/어떻게 증설할까 고민하게 되었습니다. 디스크 용량 증설 작업은 익숙하지 않았고 상당한 부담감을 느꼈습니다. 그러나, Aurora로 이전한 뒤에는 이런 걱정을 안 하게 되었습니다.
MySQL에서 Aurora로 이전할 때는 DMS(Database Migration Service)라는 서비스를 이용하여 마이그레이션을 했습니다. 해야 할 일은 DB 정보를 입력해주는 일과 예전 MySQL의 옵션을 바꿔주는 정도였습니다. 마이그레이션 작업을 제가 스스로 했다면 꽤 많은 시간을 투자했을 것입니다. 게다가 작업의 안정성 또한 담보하기 어려웠을 겁니다.

백엔드 - Scala로 코드 적게 쓰기
적은 코드로 같은 기능을 구현하고 결과적으로 개발 시간도 절약한다면 얼마나 좋을까요. Scala의 설계자 마틴 오더스키는 그의 저서 Programming In Scala에서 Scala로 코드를 쓰면 꼭 같은 일을 하면서도 코드가 적어질 수 있음을 강조합니다. 그리고, 적은 코드의 의미를 이렇게 설명합니다.
적은 코드는 프로그램을 읽고 이해하는 데 드는 노력과 결함이 줄어듬을 의미한다. - Scala 언어의 창시자 마틴 오더스키
GGtics는 이 주장에 공감하여 보편적인 Java/Spring 백엔드에서 언어만 Scala로 바꾸어 사용합니다. Java7 시절에 Scala를 공부해보니 같은 코드를 더욱 짧게 쓸 수 있을 것 같았습니다. 그래서 Scala 생태계의 주요한 프레임워크를 조사해보았습니다. 그런데 Spring에 익숙해져서 일까요? MVC부터 ORM까지 마음에 드는 게 별로 없었습니다. 결국 Scala와 Spring Boot를 조합해 사용하게 되었습니다.
실제로 Scala로 기존 Java7보다 적고 유연한 코드를 작성할 수 있었습니다. 지금 생각해보면 Scala가 제공하는 First Class Functions, Implicit Conversion, Case Classes 이 세 가지 개념이 적은 코드를 작성하는 데 큰 도움이 된 것 같습니다. Slipp에 가보면 '리팩토링, 문제를 푸는 방식, 언어의 특징'으로 코드가 더욱 적어짐을 볼 수 있습니다. 아래는 링크의 내용 중 뚜렷하게 대조 되는 코드입니다. 참고로 저는 언어의 우위를 따지자는 의도가 전혀 없으며, 그냥 적은 코드 관점의 단편적 예시일 뿐입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42// Java8 기반 원본 코드 public class CollectionTest { private static final Logger logger = LoggerFactory.getLogger(CollectionTest.class); @Test public void transform() { List<Session> sessions = Arrays.asList(new Session("10:00"), new Session("10:03"), new Session("10:10")); List<String> standardTimes = Lists.newArrayList(); for (int i = 0; i < 10; i++) { standardTimes.add("10:0" + i); } List<Session> filteredSessions = standardTimes.stream().filter(s -> { for (Session session : sessions) { if (session.isSameSessionTime(s)) return false; } return true; }).map(s -> new Session(s)).collect(Collectors.toList()); logger.debug("sessions : {}", filteredSessions); List<Session> newSessions = Lists.newArrayList(Iterables.concat(sessions, filteredSessions)); Collections.sort(newSessions, (s1, s2) -> s1.getSessionTime().compareTo(s2.getSessionTime())); logger.debug("sessions : {}", newSessions); } private class Session { private String sessionTime; Session(String sessionTime) { this.sessionTime = sessionTime; } boolean isSameSessionTime(String standardTime) { if( standardTime == null ) { return false; } return standardTime.equals(this.sessionTime); } String getSessionTime() { return sessionTime; } @Override public String toString() { return "Session [sessionTime=" + sessionTime + "]"; } } }
1 2 3 4 5 6 7 8 9// Scala의 특징을 살리고 간결함을 추구하며 포팅한 코드 class CollectionTest { @Test def transform = { val sessions = List(Session("10:00"), Session("10:03"), Session("10:10")) val filteredSessions = (0 to 9).map(x => Session("10:0" + x)).filter(!sessions.contains(_)) Logger.info((sessions ++ filteredSessions).sortBy(_.sessionTime).toString) } case class Session(sessionTime: String) }
그런데 세상에 공짜는 없는걸가요? 적은 코드 관점에서 좋아보였던 Scala지만 프로젝트에 파일이 많아지며 컴파일 속도가 느려짐을 경험하고 있습니다. 예로 저는 TDD를 즐겨하는데요. Java 시절에는 약간의 코드를 작성하고 Unit Test를 실행하면 번개 같이 실행되곤 했지만 Scala는 그렇지 않습니다. 그러다보니 TDD를 할 때 많이 코딩하고 가끔 테스트를 실행하는 형태의 습관이 생겼습니다. 아쉬운 부분입니다.
데이터 분석 - 시행 착오 빠르게 하기
분석 비용 = (시행착오 1회에 드는 고정 비용 + a) * 시행착오 횟수
그럼 어떻게 해야 분석 비용을 줄일 수 있을까요? GGtics에서는 Scala보다 Python이 좋은 해결책입니다. Python은 컴파일 없이 빠른 실행이 가능하여 시행착오를 더욱 빠르게 할 수 있기 때문입니다. 또한, 데이터 분석에 필요한 방대한 라이브러리가 있습니다. 그래서 GGtics는 데이터 분석을 할 때는 Python을 씁니다.
그럼 Python에서 결과를 만든 후 Scala 백엔드에서 어떻게 사용할까요? 우선 Python 코드를 그대로 Scala/Spark ML로 포팅합니다. 이 코드는 데이터를 학습하여 모델을 만든 후 Serialization을 하여 S3(AWS 파일 저장소)에 업로드합니다. S3에 업로드 하는 것은 모델 배포라 볼 수 있습니다. 마지막으로 애플리케이션 서버를 시작할 때 해당 모델을 S3에서 읽어 메모리에 올립니다. 이후에는 단순히 필요한 곳에서 model.predict(…)와 같은 메서드를 호출해서 사용합니다.
컴퓨팅 - 돈 내고 빨리 개발하기
만약 사용자가 통계성 데이터를 조회할 때마다 DB에 "SELECT COUNT(...)" 같은 쿼리를 실행하면 DB에 부하도 가고 응답 시간도 늦어질 것입니다. 그래서 규모가 큰 서비스에서는 복잡한 계산을 미리 해두고 필요할 때 단순히 조회만 합니다. 하지만 이런 방식은 단점이 있습니다. 만약 통계 데이터를 3개월 쌓다가 계산하는 로직의 버그를 발견했다면 기존 데이터까지 모두 마이그레이션 해야 합니다.
GGtics는 스타트업 서비스다 보니 빠른 기능 실험 중 로직이나 필드가 변경될 때가 많습니다. 그래서 보통 신규 기능을 개발할 때는 OnDemand 컴퓨팅 방식을 사용합니다. 즉 사용자의 요청이 오는 순간 즉시 메모리에 필요한 데이터를 올려 계산한 후 서비스합니다. 이렇게 하면 초기에 DB 스키마를 만들지 않아도 되며, 기능을 변경할 때도 마이그레이션 없이 모델이나 로직만 수정하면 됩니다.
다만 이렇게 하려면 좋은 CPU와 충분한 메모리를 가진 장비가 필요합니다. CPU가 좋지 않다면 응답 속도가 떨어지고, 메모리가 부족하면 안정성이 떨어질 수 있습니다. 결국, 신규 기능의 개발 속도와 유연성을 얻는 대신 서버 비용이 더 듭니다. 그래도 저는 GGtics가 가설을 빠르게 실험하며 성장하는 데 큰 도움을 주기에 긍정적이라 생각합니다.
. . .
GGtics는 어떻게 돈을 버나?
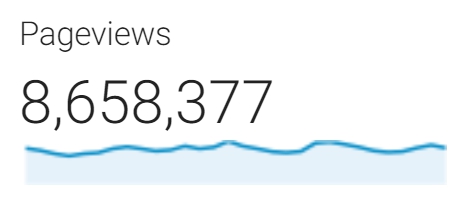 GGtics의 주 수입원은 광고입니다. 1달에 800만~1000만 정도의 PV 정도가 나오고 있어 구글 애드센스로 수익을 얻고 있습니다. 참고로 저희 서비스는 잠재력이 높은 것으로 평가 받아 구글 코리아 애드센스 팀의 광고 컨설팅을 받기도 했습니다.
GGtics의 주 수입원은 광고입니다. 1달에 800만~1000만 정도의 PV 정도가 나오고 있어 구글 애드센스로 수익을 얻고 있습니다. 참고로 저희 서비스는 잠재력이 높은 것으로 평가 받아 구글 코리아 애드센스 팀의 광고 컨설팅을 받기도 했습니다.또한, 저희의 플랫폼적인 성격을 활용하여 게임 강사와 수강생을 연결해주는 모델을 개발하고 있습니다. 우선 강사 모집을 하는 단계인데요. 상위 1% 이내의 실력을 갖춘 좋은 강사가 많이 지원했습니다. 사실 유사한 서비스가 몇 개 있지만 GGtics의 차별점은 게이머의 실력을 평가하는 GG(x)가 있다는 점입니다. 강의 후 데이터를 추적하면 어떤 강사가 잘 가르치고, 수강생이 얼마나 나아졌는지 알 수 있습니다.
그리고 위 그림과 같은 모습의 GGtics Pro 버전입니다. 현 프로의 실력을 측정하는 것과, 잠재력 있는 선수를 찾는 스카우팅에 유용할 것입니다. 현재 국내, 북미, 유럽 구단에 접촉을 시도하고 있습니다.
. . .
개발자를 채용하고 있습니다!
GGtics는 몇 가지 구체적인 개발문화를 갖고 있습니다. 먼저 자율 출퇴근 제도를 시행 중입니다. 즉 출퇴근이나 근무 시간에 제약이 없습니다. 그래서 본인의 책임만 다한다면 집에서 근무하셔도 됩니다. 또한, 서비스 기획에 참여할 수 있습니다. 특히 롤을 좋아하는 분이라면 본인의 아이디어가 서비스에 적용되는 즐거운 경험도 하실 수 있습니다. 보상은 연봉+스톡옵션으로 합니다. 스톡옵션은 많이 남아있습니다. GGtics는 본인이 스스로 판단해서 일을 정의하고 진행할 수 있는 분을 선호합니다. 다만 한 가지 중요한 점은 저희 회사는 서비스 중심 회사라는 점입니다. 따라서 서비스에 어떤 긍정적 영향을 미쳤는지를 가지고 성과를 평가합니다. 사무실 위치는 분당 정자역 앞 킨스타워입니다.
채용에 관심이 있으신 분은 "vayne@ggtics.com"으로 메일 주시면 감사하겠습니다. 또한, B2B 제안이 있으신 회사도 환영합니다. 마지막으로 저희 GGtics를 글로벌 ESports 무대로 가져가는 데 도움을 주실 수 있는 전략적 투자사도 찾고 있습니다.
