3# 데이터 엔지니어와 마이크로 서비스 구축 SI 프로젝트

https://www.popit.kr/2-데이터-엔지니어와-마이크로-서비스-구축-si-프로젝트/
이전 포스팅에서 데이터 엔지니어링에 대해 알아보았습니다만, 이 글의 주제는 어디까지나 데이터 마이그레이션에 대한 것이지 데이터 엔지니어링에 대한 것이 아닙니다.
디지털 트랜스포메이션 절차에서 데이터 엔지니어 투입 타이밍
웹 로그 수집을 통해 구글의 빅쿼리(BigQuery), 구글 애널리틱스 를 활용하여 개인화 추천 콘텐츠를 제공하는 등의 데이터 엔지니어링은 이미 대부분의 커머셜 기업에서 이미 수행중인 작업이고, SI 프로젝트의 영역이 아닙니다.
현재 행해지는 데이터 엔지니어링은 웹 로그 분석을 통한 것이 대부분으로, 핵심 비즈니스 프로세스를 건드리지 않고 아우터 아키텍트 (로그 데이터 중앙 수집기 등) 영역에서 비교적 쉽게 수집할 수 있는 것이기 때문에 데이터 분석 부서에서 독립적으로 수행할 수 있는 영역입니다.
따라서 이 글의 본래 목적인 ERP 등과 같은 정규화 된 비즈니스 데이터로부터 디지털 트랜스포메이션을 작업을 수행하기 위한 use case 를 살펴보도록 하겠습니다.
다음은 클라우드 사업자가 말하는 디지털 트랜스포메이션 작업 절차입니다.
- 클라우드 api gw 구축 및 레거시 벡엔드 라우팅
- 리프트 앤 시프트
- 리-아키텍처링 (DMS 등 데이터 이관 작업을 포함)
필자는 많은 기업의 의사 결정권자들이 트랜드에 휩쓸려 리-아키텍처링이라고 불리는 영역은 SI 업체가 알아서 개발 하는 영역이고, 누구도 자세한 절차를 설명 해 주지 않고 무작정 프로젝트를 밀어붙이다 망하거나 단순히 리프트 앤 시프트 단계에서 적당히 타협하고 프로젝트를 종료하는 케이스를 굉장히 많이 보아왔습니다.
이제 시대가 파일럿 프로젝트를 넘어서 실제 수행 가능 능력을 요구하고 있으므로, 정확한 절차에 대해 짚고 넘어가 봅시다.
- 백엔드(API) 와 프론트 분리
- 클라우드 api gw 구축 및 레거시 벡엔드 라우팅
- 리프트 앤 시프트
- DDD 설계 (이벤트 스토밍 및 보리스)
- 구체화 된 설계 (데이터 모델과 이벤트 구조)
- 데이터 마이그레이션 (데이터 싱크)
- 어플리케이션 제작
- 트래픽 미러링 (레거시 시스템과 신규 시스템) 과 오류 수정 과정
- 웨이트 가중치를 통한 리얼 트래픽 부여 (신규시스템 트래픽 1~2%) 와 오류 수정 과정
핵심 비즈니스 전환에 대한 리스크 최소화
8번과 9번 절차를 먼저 살펴봅시다.
커머스 사업자 입장에서는 서브 도메인(상품 추천 서비스) 정도야 얼마든지 새로운 시도를 할 수 있습니다. 그러나 핵심 비즈니스 프로세스인 주문,결제 등에 이런 위험하기 그지 없는 시도를 할 수는 없습니다. 8,9 번 절차는 이 새로운 시도에 대한 리스크를 최소화 하는 안정장치 입니다.
8번 절차인 트래픽 미러링은 레거시 시스템으로 흘러들어가는 API 트래픽을 복제하여 신규 시스템으로 똑같이 반영하게 합니다.
이 시점에서는 실제 결제는 샌드박스 계정으로 이루어지도록 하는 조정이 필요합니다.
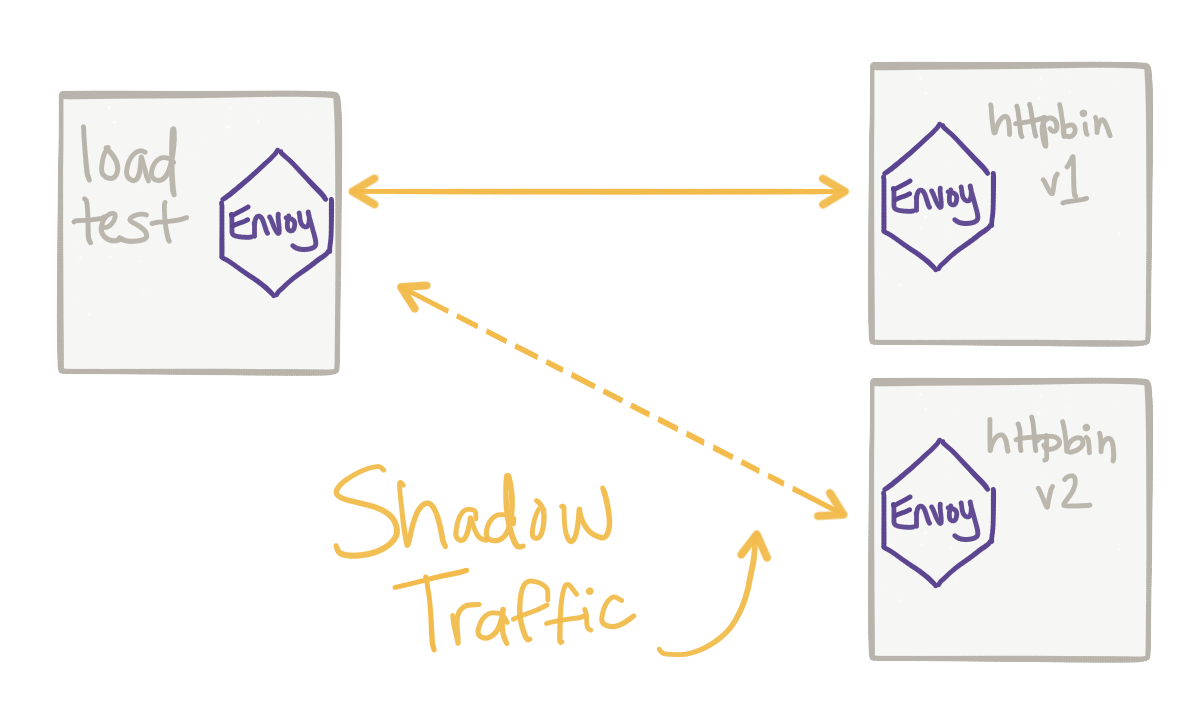
트래픽 미러링으로 중요 비즈니스 릴리즈 전 새도우 테스팅이 필요합니다.
9번 절차는 8번의 테스팅-수정 절차가 끝나면 1% 내외의 리얼 트래픽만 신규 시스템으로 흘러들어가도록 합니다.(이때는 실제 결제가 이루어 지도록 조정합니다.) 눈에 보이지 않던 오류는 리얼 트래픽 환경에서 일어납니다. 이 과정에서 0% ~ 1% 의 트래픽을 조정 해 가며 오류를 수정하는 과정을 반복해야 합니다.

트래픽 미러링, 웨이트 가중치 라우팅 모두 어플리케이션에 관계 없이 클라우드 상에서 코드 기반으로 민첩성 있게 관리 되야 하는 것이 마이그레이션 과정에서 중요한 요소입니다.
`8,9 번 절차를 위해서는 반드시 백엔드와 프론트가 분리되어 있어야 합니다`. 백엔드가 100% API 화 작업이 되어 있지 않는 시스템에 대해서는 디지털 트랜스포메이션 작업을 시도 조차 할 수 없으니 고객에게 언급하지도 않는 것이 좋습니다.
그리고 왜 클라우드 상에서 이 모든 구축과정이 이루어 져야 하는지에 대한 답도 여기에 있습니다.
트래픽을 미러링하고, 웨이트 기반 가중치로 조정하고, 때로는 특정 지역에 노출시키는 등 릴리즈에 대한 충격을 최소화 할 수 있는 민첩성을 가진 로드밸런서는 클라우드 기반의 컨테이너 오케스트레이터 및 L7 레이어 리버스 프락시(Nginx 등) 의 콜라보레이션으로 가능하기 때문입니다.
만일 온-프레미스 환경에서 k8s 와 Envoy 프락시를 완벽하게 제어 가능한 운영 인력이 있다고 한다면, 온-프레미스 환경에서도 가능한 시나리오 입니다.
데이터 전환 과정
그리고 4번 DDD 설계와 5번 구체화 과정은 우리가 그동안 수도 없이 받았던 마이크로 서비스 개발 방법론에 입각하므로, 자세한 설명은 넘어가도록 하겠습니다.
이제 4번과 5번을 거쳐 7번 어플리케이션을 제작하기 전, 6번 과정인 데이터 마이그레이션 과정이 있습니다.
- 여러 테이블을 참조하거나 참조되고 있는 도메인 영역의 테이블들을 2~3 개의 테이블로 이루어진 Thin Database 로 이전해야 함.
- 기존 데이터가 실시간으로 새로운 마이크로 서비스의 데이터베이스로 이관되고 있어야 함.
이 작업은 아웃풋이 되는 Thin Database 는 전통적인 데이터베이스처럼 Function, 프로시져 가 존재하지 않습니다.
그리고 Thin Database 로 이전하는 과정은 데이터 가공 단계를 동반하기 때문에 단순히 SQL 을 작성해 View Table 을 생성 후 이식하는 프로세스가 통용되지 않는 경우가 많습니다.
따라서 차세대사업, 기업 합병 등 시스템의 변경에 의해 데이터를 새로운 시스템으로 이관하는 행위 같은 DBA 가 투입되어야 하는 거창한 데이터 마이그레이션을 의미하는 것이 아닙니다.
AS-IS 와 TO-BE 모델이 어떻게 바뀌어야 하는가 이해하고, 데이터 가공 코드를 작성할 수 있는 데이터 엔지니어 (개발자) 가 수행해야 하는 타스크 입니다.
CDC(Change Data Capture) 는 데이터베이스에서 데이터 변경이 일어났을 경우 이벤트를 전송시켜 주는 기능입니다.
모든 기간계 시스템의 오라클을 비롯한 상용 데이터베이스에서는 CDC 옵션을 설정해야 합니다.
그리고 이 CDC 들은 클라우드 상의 메시지 처리 시스템으로 흘러들어가, Redshift 등 데이터 웨어하우스에 적재되야 합니다.

데이터 웨어하우스로 CDC 동기화는 디지털 트랜스포메이션을 위한 마이그레이션 작업 및 기타 확장성 있는 아이디어를 실현 가능하게 합니다.
디지털 트랜스포메이션을 진행하기 위한 모든 새로운 시도들은 이 데이터 웨어하우스에 적재된 데이터들로부터 시작되야 합니다.
데이터 엔지니어는 spark sql 을 통해 실시간으로 데이터 웨어하우스의 원시 데이터들로부터 Thin Database 로 Data Sync 가 이루어 지도록 작업해야 합니다.
Spark Structured Streaming 을 활용해 Streming 으로 읽어들이는 다수의 테이블들을 메모리 상에서 join 하도록 한 후, Thin Database 로 적재되도록 프로그래밍 해야 합니다.
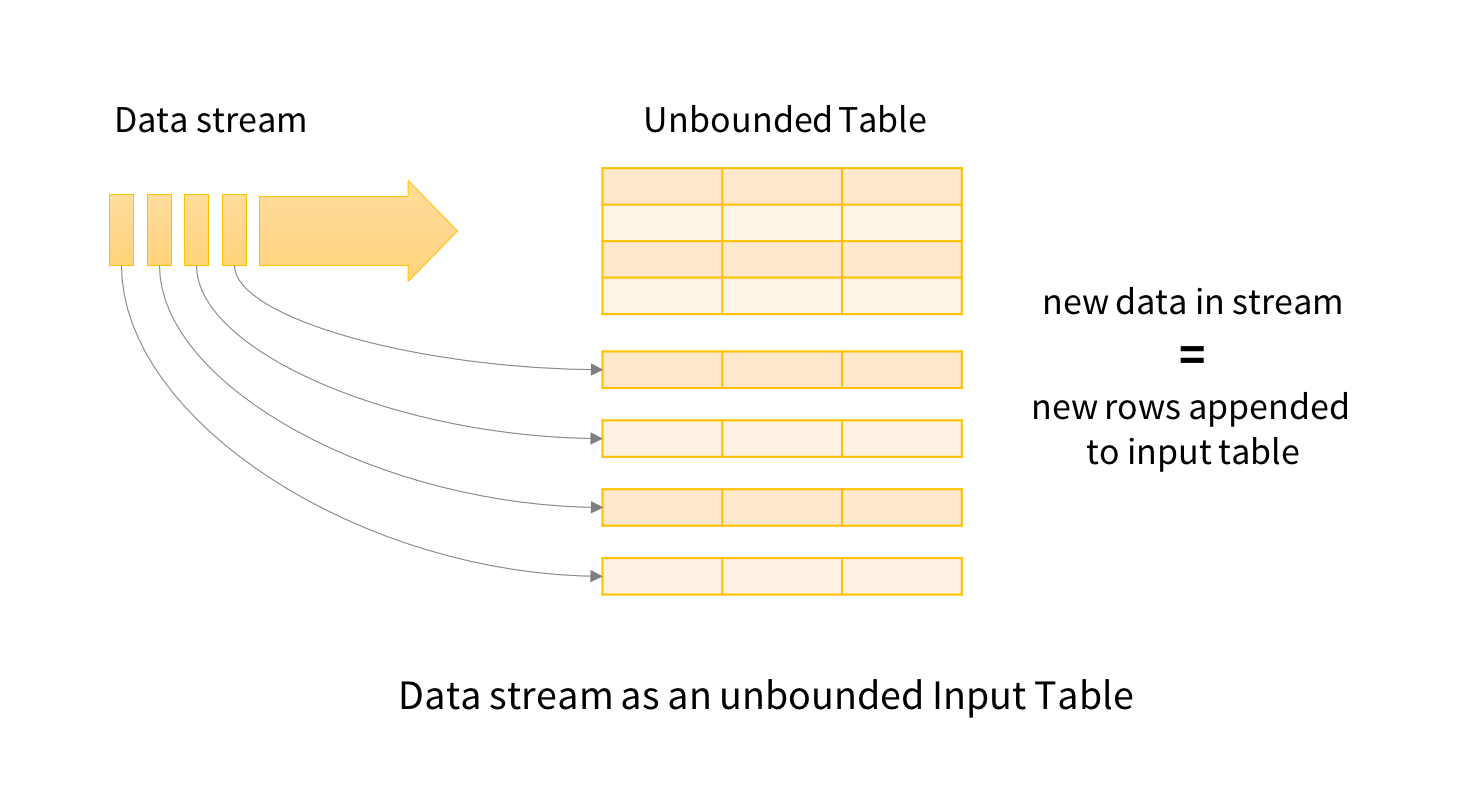
Spark Structured Streaming 은 실시간으로 주입되는 데이터들을 메모리 상의 데이터프레임(테이블) 에 인서트하여 줍니다. 실시간으로 갱신되는 데이터프레임들을 상대로 sql 쿼리 문을 사용하여 리얼 타임 데이터 가공 절차를 가능하게 합니다.
이 작업은 이벤트 스토밍을 통한 구체화 작업 이후로 바로 이어져야 하며, 어플리케이션 제작은 그 이후입니다.
신규 어플리케이션 제작 과정은 이 실시간으로 갱신되는 실제 데이터를 바탕으로 테스트 되야 합니다.
그래야 테스트 후 실 사용자에게 릴리즈 하는 과정도 별다른 부가적인 절차 없이 저비용으로 전환이 가능합니다.
신규 서비스 팀은 데이터 문제 때문에 기존 운영 서비스 팀과 협의해 어플리케이션 로직을 수정해야 하는 과정은 이루어지지 않아야 합니다. 이는 곧 생산성 문제와 직결되기 때문입니다.
데이터 웨어하우스 이관 후 마이그레이션 전략을 세우지 않고 현업의 DBA 를 동반하는 동시에 레거시-신규 어플리케이션 끼리의 직접적인 핸들링을 통해 일을 진행하려 한다면, 디지털 트랜스포메이션 작업은 매번 많은 비용을 지불해야 하는 부담스러운 작업이 될 것입니다.
Summary
이제까지, 디지털 트랜스포메이션 작업에서 고려하지 않았던 데이터 마이그레이션의 리스크에 대해 살펴보았고, 이것을 수행할 수 있는 데이터 엔지니어가 필요한 순간이 온다는 것을 살펴보았습니다.
일반 개발자가 Thin Database 를 설계할 수는 있지만, Spark / 데이터웨어하우스 를 이용하여 실제 마이그레이션 하는 코드를 작성하는 것은 난이도의 문제라기 보단 러닝 커브의 시간 문제이기 때문에 어려울 수 있습니다.
SI 수행에서도 서비스 하는 회사와 다를 것 없이, 점점 장인정신을 기반한 버티컬 얼라인된 팀플레이가 중요해지는 순간이 오고 있는 것 같습니다. 데이터 엔지니어, Devops 엔지니어, 클라우드 SA, 아키텍터 등 이전까지는 없던 키-플레이어들이 프로젝트 수행 시 없어서는 안되는 포지션이 되었지만, 아직까지 이들 직군들의 투입에 대해 어떻게 보수를 지급 받을 수 있을 것인가 하는 시장의 공감대가 형성되어 있는 것 같지는 않습니다.
하지만 고객으로부터 하는 일에 대한 가치를 인정 받고 정당한 보수를 받는 것은 더 나은 소프트웨어를 개발하고 이러한 특수 직군들이 서비스 기업으로 이동하지 않고 SI 시장에서 계속 존속할 수 있게 하는 원동력이 되므로 언젠가는 이루어 져야 하는 일입니다. 물론 거기에 합당한 경험과 실력을 쌓는 것이 최우선시 되어야 합니다.
디지털 트랜스포메이션 사업을 추진하시는 분께 고객에게 데이터 엔지니어가 왜 필요한지 설득하고, 적정한 M/M 을 할당받을 수 있는 근거로 이 글이 조금이나마 도움이 되었으면 합니다.