Druid 성능 엿보기. Spark이랑 같이 보자.

들어가면서..
Druid는 Timeseries 데이터를 자체에 내장된 Lambda architecture 구조를 기반으로 데이터의 eventually exactly-once delivery를 보장하는 시스템입니다. 또한 데이터 적재시에 지정한 단위 시간 기준의 rollup(pre-aggregation)을 통한 데이터 축약과 column기반의 dictionary 인코딩 및 bitmap 자료구조로 복수개의 임의의 조합으로 구성된 column들에 대한 aggregation 질의에 대하여 sub-second수준으로 응답할 수 있습니다. 그리고 높은 ingestion 성능과 대용량의 과거 데이터에 대한 빠른 쿼리 성능을 동시에 달성하기 위해서 realtime node와 historical node를 각각 따로 둔 것이 특징입니다. realtime node에서는 row기반의 write 성능이 좋은 in-memory자료구조를 유지하여 ingestion에 최적화하고, 대용량의 과거 데이터 처리를 위해서는 대단위의 historical node들이 read 성능을 올리기 위한 자료구조를 가지고 있어서 효율적이고 빠른 데이터 적재와 동시에 대용량의 과거 데이터에 대하여 빠른 질의 처리가 가능합니다. 마지막으로 쿼리 처리시에 최근 데이터에 대한 질의 결과와 과거 데이터에 대한 질의 결과를 병합하는 broker node가 있어서 따로 별도의 질의 결과를 통합하기 위한 시스템을 구축할 필요가 없습니다.
정리하자면, Druid는 Timeseries 데이터에 대하여 ingestion 속도가 빠르고, 실시간으로 들어오는 최근 데이터와 과거 데이터들에 대한 Multi-dimensional OLAP 쿼리의 통합 결과를 sub-second 수준의 응답으로 보여주는 엔진입니다. 본 글에서는 이러한 Druid의 쿼리 응답 성능을 측정하고 요즘 각광을 받고 있는 Spark과 비교, 대조함으로써 Druid가 가진 장단점을 파악하고자 합니다. 참고로 Druid에 대한 벤치마크는 아래 참고1에 나와 있는 링크를 참고하여 수행하였으며, 벤치마크시에 사용한 버전은 Druid 0.9.2, Spark 2.0입니다. Druid의 컨셉과 동작 과정에 대해서 더욱 자세히 알고 싶으시다면 아래 시리즈를 참고하시면 많은 도움이 되실 것 같습니다.
http://www.popit.kr/time-series-olap-druid-입문/
Dataset
벤치마크 수행을 위한 데이터로 TPC-H Benchmark 1GB, 100GB에서 lineitem 테이블만을 대상으로 했습니다. lineitem 테이블은 TPC-H Benchmark 데이터셋에서 제품, 주문과 배송 일자등의 정보를 담고 있는 가장 큰 테이블입니다. 참고로 Druid가 사용하는 HDFS상의 데이터 사용량이 아래 표에 나타나 있는데, Druid는 쿼리 처리시에 각 historical node의 로컬 상에 다운로드하여 실제 사용되는 디스크량은 표에 나와 있는 것보다 더 크니, Druid가 표에 있는 것만큼 디스크를 사용한다고 오해마시길 바랍니다.
|
Dataset |
rows |
원본 size |
druid segment size
(HDFS) |
|---|---|---|---|
| TPC-H 1G lineitem | 6,001,215 | 725M | 614M |
| TPC-H 100G lineitem | 600,037,902 | 74G | 35G |
Ingestion
Druid에 데이터 적재를 위해 AWS EMR을 사용하였습니다. Druid는 실시간뿐만 아니라 MapReduce를 이용하여 batch로도 데이터를 적재할 수 있는데, 설정한 파라미터에 따라서 적재 소요시간이 크게 차이가 날 수 있으니 참고하시길 바랍니다. 또한 적재시에 설정한 파라미터가 shard 수와 같이 쿼리 시간 성능에 영향을 줄 수 있습니다. Druid는 데이터를 적재할 시에 rollup과 필요한 인덱스를 생성을 하기 때문에 생각보다 시간이 오래 걸릴 수 있는데, 쥐어짜도록 튜닝하거나 하둡 클러스터를 증설하는 식으로 대응할 수 있습니다. Ingestion 옵션중에서 하나를 짚고 가자면 targetPartitionSize가 가장 중요한 옵션일 것인데 Druid에 저장되는 데이터를 몇 개의 Shard로 나눌 것인지 결정하는 것입니다. 이 숫자를 늘리면 하나의 reducer에서 처리하는 시간이 길어져 ingestion시간이 길어지지만 압축이 잘 되기 때문에 Druid의 segment의 크기와 수가 줄어드는 장점이 있습니다.
|
Dataset |
소요시간(초) |
Ingestion 옵션 |
|---|---|---|
| TPC-H 1G lineitem |
395 초
|
targetPartitionSize : 5000000
mapreduce.map.java.opts : -Xmx1024m -Duser.timezone=UTC mapreduce.reduce.java.opts : -Xmx1024m -Duser.timezone=UTC query granularity : 1 day segment granularity : 1 month |
| TPC-H 100G lineitem |
2558 초 |
targetPartitionSize : 5000000
mapreduce.map.java.opts : -Xmx1024m -Duser.timezone=UTC mapreduce.reduce.java.opts : -Xmx8000m -Duser.timezone=UTC query granularity : 1 day segment granularity : 1 month |
환경 : AWS EMR 5.0.0, r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
Queries
쿼리 수행을 위해서 Druid의 경우에는 R로 작성된 RDruid를 이용했습니다. 또한 Druid는 기본적으로 SQL을 지원하지 않기 때문에 Spark과 비교할 시에는 Druid 쿼리에 대응되는 SparkSQL 쿼리를 사용 하였습니다. 참고로 이 쿼리들은 TPC-H Benchmark의 쿼리들이 아님에 주의하시기 바랍니다. SparkSQL 벤치마크 수행과 관련하여 궁금한 부분이 있으시면 참고 2에 있는 소스코드를 확인하시기 바랍니다. 마지막으로, 좀 더 정확한 벤치마크를 위해 Druid에서 쿼리 캐시 설정을 모두 해지(useCache=false)하였습니다.
벤치마크에 사용한 쿼리는 총 2가지 유형이 있습니다. timeseries aggregation은 Druid의 가장 기본적인 쿼리로 적재시에 rollup이 되어 있는 metric에 대하여 쿼리 시간에 aggregation하는 것입니다. 여기서 metric이란 Druid에서 aggregation 연산을 수행할 column을 말하는 것이고 rollup이란 Druid가 가진 주요한 특징으로 데이터 적재시에 주어진 시간 간격과 유니크한 column들을 기준으로 metric들을 그룹핑하고 각 그룹마다 min, max와 같은 partial aggregation 연산들을 미리 해 놓는 것입니다. 여기서 그룹핑할 때 사용하는 column들을 dimension이라고 부릅니다. top-n은 metric에 대하여 aggregation을 하고 그 결과를 정렬하여 상위 n개를 반환하는 쿼리입니다. top-n을 할 때는 컬럼의 cardinality의 수준에 따른 응답 속도를 비교하고자 cardinality가 높은 l_partkey와 cardinality가 낮은 l_commitdate로 각각 top-n 쿼리를 수행 했습니다.
- 넓은 시간 범위에 대해서 count(*) 쿼리
- dimension필터링을 적용하여 몇 개의 metric에 대하여 timeseries aggregation 쿼리
- high cardinality, low cardinality dimension에 대해서 top-n쿼리.
- high cardinality : l_partkey, 100G에서 20,272,236 unique values
- low cardinality : l_commitdate, 100G에서 2466 unique values
|
Name |
Druid query type |
SQL Query |
|---|---|---|
| count_star_interval | timeseries | SELECT COUNT(*) FROM LINEITEM WHERE L_SHIPDATE BETWEEN '1992-01-03'AND '1998-11-30'; |
| sum_price | timeseries | SELECT SUM(L_EXTENDEDPRICE) FROM LINEITEM; |
| sum_all | timeseries | SELECT SUM(L_EXTENDEDPRICE), SUM(L_DISCOUNT), SUM(L_TAX), SUM(L_QUANTITY) FROM LINEITEM; |
| sum_all_year | timeseries | SELECT YEAR(L_SHIPDATE), SUM(L_EXTENDEDPRICE), SUM(L_DISCOUNT),SUM(L_TAX), SUM(L_QUANTITY) FROM LINEITEM GROUP BY YEAR(L_SHIPDATE); |
| sum_all_filter | timeseries | SELECT SUM(L_EXTENDEDPRICE), SUM(L_DISCOUNT), SUM(L_TAX),SUM(L_QUANTITY) FROM LINEITEM WHERE L_SHIPMODE LIKE '%AIR%'; |
| top_100_parts | top-n | SELECT L_PARTKEY, SUM(L_QUANTITY) FROM LINEITEM GROUP BY L_PARTKEY ORDER BY SUM(L_QUANTITY) DESC LIMIT 100; |
| top_100_parts_details | top-n | SELECT L_PARTKEY, SUM(L_QUANTITY), SUM(L_EXTENDEDPRICE),MIN(L_DISCOUNT), MAX(L_DISCOUNT) FROM LINEITEM GROUP BY L_PARTKEY ORDER BY SUM(L_QUANTITY) DESC LIMIT 100; |
| top_100_parts_filter | top-n | SELECT L_PARTKEY, SUM(L_QUANTITY), SUM(L_EXTENDEDPRICE),MIN(L_DISCOUNT), MAX(L_DISCOUNT) FROM LINEITEM WHERE L_SHIPDATE BETWEEN '1996-01-15' AND '1998-03-15' GROUP BY L_PARTKEY ORDER BY SUM(L_QUANTITY) DESC LIMIT 100; |
| top_100_commitdate | top-n | SELECT L_COMMITDATE, SUM(L_QUANTITY) FROM LINEITEM GROUP BY L_COMMITDATE ORDER BY SUM(L_QUANTITY) DESC LIMIT 100; |
Druid 쿼리 응답속도
그림 1은 컴퓨팅 노드(historical node)의 수를 1개에서 6개로 늘리면서 쿼리 응답 속도를 측정한 것입니다. 측정 방식은 동일한 쿼리를 총 20번 수행하여 그 중에서 median값을 뽑은 것입니다. 때문에 초기에 warm-up으로 인한 초기 응답이 긴 쿼리들은 빠져 있다고 보시면 되고 반복적으로 같은 쿼리를 수행하기 때문에 여러 단계의 캐시들이 적용되어 있는 결과입니다. 객관적인 자료로는 제시하지는 않았지만 초기에 약 3~5번 이후의 쿼리들에 대해서는 응답속도는 거의 변화가 없이 수렴하였습니다.
timeseries aggregation은 노드가 하나 일 때도 상당히 좋은 응답성을 보여주고, 노드 수가 6개 일 때는 1초 미만의 속도로 쿼리에 대해 응답합니다. top-n쿼리의 경우 노드가 1개일 때와 6개일때 응답 속도에서 절대적 시간에서 큰 차이를 보이고 있습니다. 가장 오래 걸리는 쿼리는 cardinality가 높은 column을 기준으로 여러 개의 aggregation을 수행하는 top_100_parts_details인데, 그 이유에 대해서는 뒤에서 Spark과 비교하면서 자세히 다루겠습니다.
6대 보다는 50대, 100대 이상의 노드에서 벤치마크를 수행하는 것도 좋겠으나 실험 환경 마련이 쉽지 않아서 참고한 자료와 동일한 6대만으로 수행했습니다. 혹시 많은 노드들 상에서 벤치마크를 수행하시는 분께서는 결과를 커뮤니티에 공유해 주시면 감사하겠습니다.
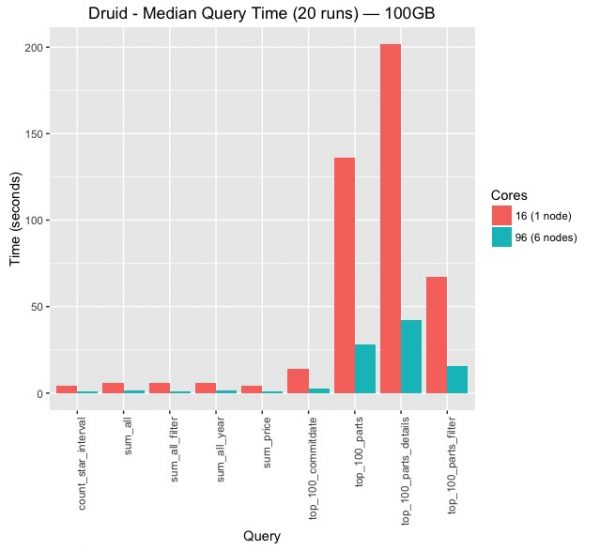
그림 1.
환경 : AWS EMR 5.0.0, r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
그림2는 AWS EC2에서 Druid 전용 클러스터와 AWS EMR에 Druid를 설치한 후의 쿼리 성능 비교한 것입니다. 당초에 EC2와 EMR 사이에 성능 차이가 크지 않을 것이라고 예상을 했었는데, 쿼리 성능에서 상당한 차이를 보입니다. EC2 인스턴스에 Druid를 구성한 것의 성능이 EMR상에 구성한 것보다 2~3배 이상 나오는 것을 확인 할 수 있습니다. Druid를 EMR위에 설치하는 것 외에도 인스턴스 타입에서 차이점이 있는데 broker가 설치된 인스턴스를 메모리가 많은 r3.4xlarge에서 CPU 성능이 더 좋은 c4.4xlarge로 변경한 것입니다. 물론 EMR 상에 Druid를 설치하는 것은 권장되는 것은 아니지만, 아래에 Spark과 비교하는 섹션에서 Spark을 EMR상에서 구동시켰기 때문에 Spark과 비교를 하기 위해 EMR상에 Druid의 성능을 확인해 보았습니다. 일반적으로는 Druid를 AWS상에 설치할 때는 Broker, Historical서버마다의 특징에 맞는 인스턴스를 선택하는 것이 권장된다고 하겠습니다. 그 외에 같은 인스턴스 타입이라도 EMR과 EC2 인스턴스간에 어떤 차이가 있는 것 같기는 한데, 안타깝게도 필자는 AWS에 익숙하지 않아서 확인하기가 어렵습니다.
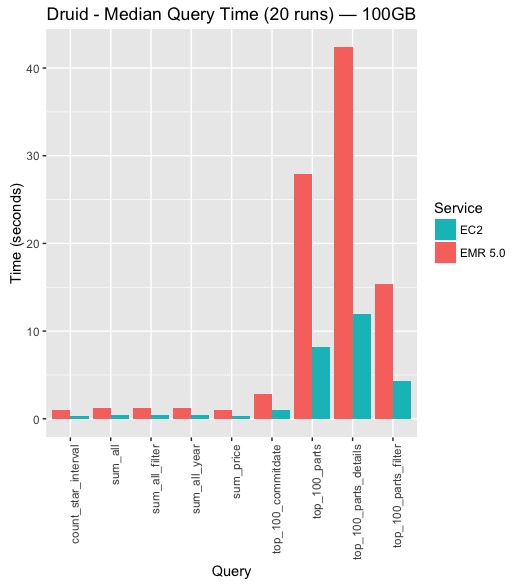
그림 2.
EC2 환경 :
- AWS EC2 Amazon Linux AMI 2016.09
- broker : c4.4xlarge(2.9GHz * 16, 30G, EBS)
- historical nodes : r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
EMR 환경 : AWS EMR 5.0.0, r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
Druid와 Spark의 쿼리 응답속도 비교
이번에는 Druid와 Spark의 쿼리 응답속도를 비교할 예정입니다. 물론 Druid는 pre-aggregation(rollup)을 이용하여 데이터를 적재할 시에 sum, min, max와 같은 summary들을 위한 중간 데이터를 미리 생성해 놓는 등 Spark과는 다른 성질이 있기 때문에 누가 더 빠르고 어느 것이 더 좋다고 말하는 것은 무리가 있을 것입니다. 그러나 Druid와 Spark을 비교함으로 해서 Druid가 가진 인터랙티브한 분석 능력을 Spark을 기준으로 가늠해 볼 수 있고 서로가 가진 장단점을 알 수 있기 때문에 비교하는 과정은 나름 의미가 있다고 하겠습니다.
그림3은 Druid와 HDFS에서 데이터를 읽어서 처리하는 Spark, 그리고 DataFrame을 미리 캐시해 둔 Spark의 쿼리 응답속도를 비교한 것입니다. 참고로 그림3은 쿼리 타입에 따라서 aggregation과 top-n의 응답시간이 크게 달라질 수 있기 때문에 차트를 두 개로 나누어 표시했습니다. 비록 그림3의 분리한 두 차트에서 수행시간을 나타내는 y-scale은 같지만 다른 그림에서는 다를 수 있으니 주의하시기 바랍니다. 그리고 Spark의 경우에는 SparkSession을 미리 만들어두어 SQL을 쿼리를 실행하기 직전과 직후의 시간 차이를 측정한 것임을 밝혀둡니다.
그림3을 보면 당연한 결과이겠지만 디스크에서 데이터를 로딩하는 Spark(HDFS)의 응답속도가 가장 떨어지고, 그 다음으로 Spark(Cached)이 중간이고, Druid가 가장 응답속도가 빠릅니다. Spark(HDFS)의 경우 각 쿼리마다 약 60초 내외의 응답시간을 보여주고, Spark(Cached)는 aggregation 쿼리에 대해서 sum_all_year를 제외하고 약 3초 이하의 응답속도를 가지지만 top-n 쿼리에 대해서는 8초~10초 중반의 응답 속도를 보여줍니다. Druid의 경우에는 aggregation 쿼리에서는 1~2초 미만의 가장 우수한 성능을 보여주지만, top-n에서는 쿼리 응답속도가 최대 40초까지 급격하게 증가함을 알 수 있습니다. 마지막으로 각 항목의 응답시간 분포를 보면 Spark(HDFS)의 경우는 응답시간이 비교적 일정한 것에 비해서, Druid는 응답시간의 차이가 쿼리 타입에 따라서 상당합니다.
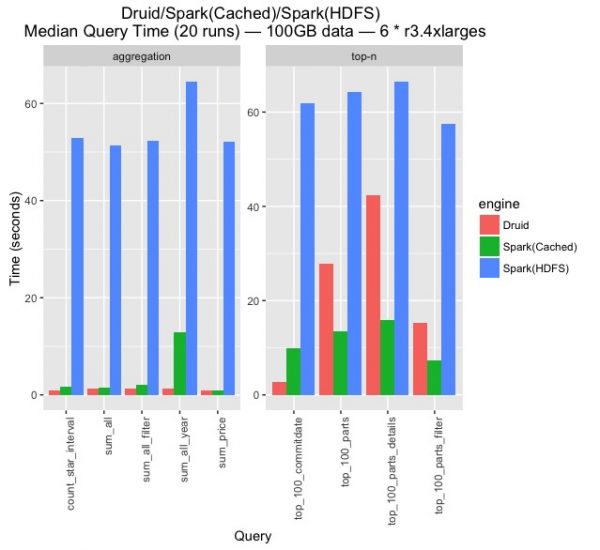
그림 3.
환경 : AWS EMR 5.0.0, r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
그림4는 그림3에서 Druid와 Spark(Cached)만을 따로 빼내서 비교한 것입니다. 그림3과 마찬가지로 쿼리 타입에 따라서 차트를 나누었는데, 두 차트에서 y-scale이 다른 것에 주의하시기 바랍니다. Druid와 Spark을 비교하는 것이 글의 목적이기는 하지만 우선 DataFrame으로 변환하여 메모리에 캐시한 Spark의 경우에는 상당히 뛰어난 응답성을 보여주는 것이 인상적입니다. Spark 2.0에서의 Catalyst와 Tungsten 최적화 기술의 효과를 확인할 수 있겠습니다. 더불어 그림4에서 다음과 같은 몇 가지 사항들을 확인해 볼 수 있습니다.
첫번째로 Spark에서 aggregation 타입의 쿼리 중 sum_all_year의 경우 다른 쿼리들과 수행 시간 측면에서 양상이 다릅니다. 다른 aggregation 타입의 쿼리들은 Spark과 Druid의 쿼리 속도에서 1.5~2배 정도로 Druid가 더 빠르지만, sum_all_year의 경우 거의 10배 가까이 차이가 납니다. 왜 이런 현상이 벌어지는 걸까요? sum_all_year 쿼리 내용을 보면 알 수 있습니다. sum_all_year는 aggregation 타입의 다른 쿼리들과는 다르게 GROUP BY 쿼리입니다. 그 때문에 Spark에서는 shuffling등의 오버해드로 인해 다른 aggregation보다 sum_all_year의 응답속도가 훨씬 느리게 나오는 것입니다. sum_all_year의 응답속도를 오른쪽의 top-n 타입의 다른 GROUP BY 쿼리들과 비교해 보면 15초 이상으로 비슷한 것을 확인할 수 있습니다.
반면에 Druid를 살펴보자면, 해당 sum_all_year 쿼리를 다른 aggregation 타입의 쿼리들과 비교하면 응답성능에서 큰 차이가 없는데요, 그것은 Druid의 가장 중요한 특징중 하나인 timeseries 데이터를 처리하는 방식 때문입니다. 위에 이와 관련한 간단한 설명이 있었지만 좀 더 자세히 Druid의 특성을 말씀드리자면 다음과 같습니다. 먼저, Druid에 데이터를 적재하기 위해서는 반드시 timestamp dimension이 있어야 하고 적재시에 이를 지정해야 합니다. Druid에서는 이 timestamp dimension을 segment를 나누는 것과 rollup을 하는 기준으로 사용합니다. 아래 쿼리에서 GROUP BY 컬럼으로 사용하고 있는 L_SHIPDATE는 Druid에서 데이터를 ingestion할 때 지정한 timestamp dimension이었고, 데이터 적재시 rollup에 의해서 미리 L_SHIPDATE를 기준으로 GROUP BY를 한 후 SUM(L_EXTENDEDPRICE)와 같은 aggregation 값들의 중간(intermediate)값들을 미리 계산해 놓고 쿼리 시에 merge하는 것입니다. 때문에 sum_all_year도 sum_all나 sum_all_filter와 같은 aggregation 쿼리들과 응답속도에서 큰 차이가 없는 것입니다. 이러한 Druid의 성능적인 특징으로 인해서 Druid가 timeseries 데이터에 대해서 timestamp dimensions을 포함한 GROUP BY 형태의 워크로드에 대해서는 다른 데이터 처리 엔진보다 월등히 빠르지만 반대급부로 일반적인 분석 쿼리쪽은 범용성 측면에서 다소 제약점을 가질 수 있다고 하겠습니다.
| SELECT YEAR(L_SHIPDATE), SUM(L_EXTENDEDPRICE), SUM(L_DISCOUNT),SUM(L_TAX), SUM(L_QUANTITY) FROM LINEITEM GROUP BY YEAR(L_SHIPDATE); |
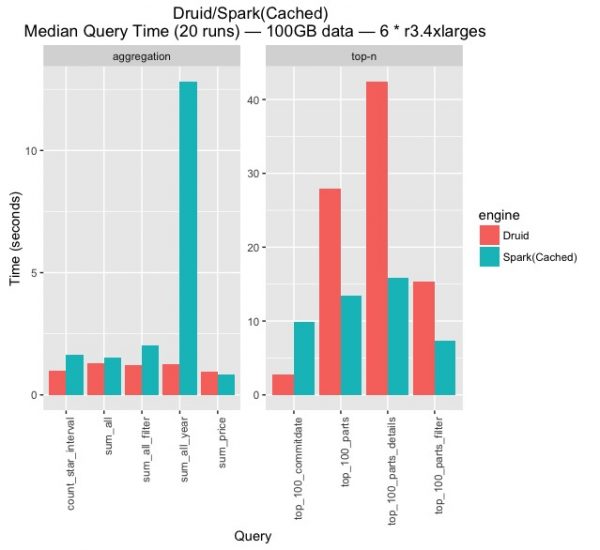
그림 4.
환경 : AWS EMR 5.0.0, r3.4xlarge (2.5GHz * 16, 122G, 320G SSD) * 6 workers
두번째로 top-n 쿼리에 대해서 Spark과 Druid를 비교하면 Spark은 비교적 수행시간 편차가 작은데 비해서 Druid는 편차가 상당히 크다는 것을 알 수 있습니다. 또한 일부 쿼리는 Druid가 더 빠르지만 다른 쿼리들에 대해서는 Spark이 좋게 나타나고 있습니다. 이러한 결과를 이해하기 위해서는 Druid의 top-n 쿼리의 동작과정을 먼저 이해할 필요가 있습니다. Druid의 top-n쿼리는 정확한 결과를 보장하지 않는 추정값임을 미리 밝혀둡니다. Druid는 top-n쿼리 수행시에 각 컴퓨팅 노드(historical node)에서 k-threshold 만큼 상위 k개의 항목을 샘플링하여 query master 서버(broker)에서 이들을 merge하는 식으로 동작합니다. 이 과정에서 쿼리 성능은 top-n을 구하고자 하는 dimension(column)의 cardinality(unique 수)에 큰 영향을 받게 됩니다. 세부적으로 프로파일링을 하지는 않았지만 일반적으로 cardinality가 높게되면 서버간 JSON으로 통신하는 Druid의 특성상 네트워크 트래픽 증폭 및 single node로써 쿼리를 취합하는 broker에서 중간 결과들을 merge할 때 할 일이 많아지게 되기 때문이라 생각합니다. 2,466의 cardinality를 가진 L_COMMITDATE로 top-n을 구하는 top_100_commitdate의 경우 수행시간이 3초정도 인 것에 반해, cardinality가 20,272,236로 높은 L_PARTKEY로 top-n을 구하는 top_100_parts, top_100_parts_details는 쿼리 수행시간이 약 30~40초 가량 됩니다. cardinality에 따라서 쿼리 성능이 10배 가량 나는 것을 확인할 수 있습니다. 반면에 Spark의 경우 top-n을 위한 기준 column의 cardinality가 쿼리 수행시간에 미치는 영향이 Druid보다 작습니다. 아무래도 하나의 노드에서 중간 결과들을 merge하는 과정이 없고, shuffling 및 서버간 RPC와 관련한 최적화가 많이 되었기 때문일 것입니다.
결론
정리하면, 직접적인 비교는 어렵겠지만 Druid는 timeseries 데이터를 rollup, aggregation하는 워크로드에서는 Spark보다 10배 이상의 응답성을 보여주는 것에 반해, cardinality가 높은 column에 대해 top-n쿼리쪽은 다소 약한 모습을 보여주고 있습니다. Spark의 경우 DataFrame으로 변환한 후 메모리에 캐시해 놓으면 스캔 쿼리에 대해서 상당한 수준의 응답성을 보여주고 있고 GROUP BY쿼리의 경우 cardinality에 따른 영향이 Druid보다 작습니다.
끝으로, 이번 비교를 통해서 얻은 것이 있다면 Druid가 가진 장단점을 확인할 수 있었다는 것입니다. timeseries 데이터에 대한 빠른 응답성을 요구하는 요구사항과 노드에 따른 구동 환경이 잘 맞게 설정된다면 Druid는 상당히 매력적인 솔루션으로 다가올 것으로 기대됩니다. 개인적으로 Druid의 search와 같은 좀 더 많은 종류의 쿼리와 더 다양한 환경에서 다뤘으면 했는데, 시간 관계상 다음 기회로 미루겠습니다.
참고
1. Druid performance benchmark
http://druid.io/blog/2014/03/17/benchmarking-druid.html
2. SparkSQL 쿼리를 위한 소스코드
https://github.com/jaehc/tpch-spark/tree/feature-run-multiple-queries