JPA 선호하는 패턴

최근 JPA를 3년 가까이 사용하면서 개인적인으로 선호하는 패턴들을 한 번 정리하려고 한다. 어디까지 개인적으로 선호하는 패턴으로 굳이 이런 가이드를 따르지 않아도 된다.
컬럼 에노테이션 사용
1 2 3 4 5 6 7 8 9 10@Entity @Table(name = "member") data class Member( @Column(name = "username", nullable = false) var username: String, @Column(name = "age", nullable = false) var age: Int = 0, @Column(name = "email", nullable = false, unique = true, updatable = false) var email: String )
칼럼 에노테이션과 멤버 필명이 동일한 경우 칼럼에노테이션을 생략하는 경우도 있다. 그래서 일치하지 않은 것들만 작성하는 방법도 있지만 나는 모든 멤버 필드에 칼럼 에노테이션을 작성하는 패턴을 선호한다.
칼럼 에노테이션을 통해 nullable, unique, updatable 등등 여러 메타 정보를 전달해 줄 수 있다. 물론 필요한 경우에만 추가하고 기본적으로 작성하지 않아도 되는 패턴을 선택해도 되지만 개인적으로 이런 예매한 예외를 두는 가이드 보다 조금 불편하더라도 다 작성하는 패턴이 좋다고 본다.
그리고 일단 컬럼 에노테이션을 작성하면 한 번더 이 필드에 대해서 생각을 해보고 unique, nullable 여부 등을 한 번 더 생각 보게 돼서 좋다고 생각한다.
또 멤버 필드 리네임 관련 리팩토링에 과감해질 수 있다. 멤버 필드는 카멜케이스, 데이터베이스는 스네이크 케이스를 사용하는 경우가 흔한데 칼럼명이 긴 경우 가끔 오타 때문에 실수할 수 도 있다. 그러기 때문에 애초에 칼럼 에노테이션으로 다 작성하는 게 리팩토링 할 때도 안전성이 있다. 칼럼 에노테이션을 작성하면 멤버 필드 rename 관련 리팩토링을 과감하게 할 수 있다.
엔티티에 과도한 에노테이션은 작성하지 않는다
1 2 3 4 5 6 7 8 9 10 11 12 13 14@Entity @Table( name = "member", indexes = [ Index(columnList = "username"), Index(columnList = "age") ], uniqueConstraints = [ UniqueConstraint(columnNames = ["username", "age"]) ] ) data class Member( ... )
사실 위 칼럼 에노테이션 사용과는 좀 반대되는 개념이긴 한데 너무 과도한 에노 테이션으로 엔티티 클래스의 비즈니스 코드의 집중도를 떨어트리기 때문에 선호하지 않는다.
물론 위 작업을 아주 간결하게 표현할 수 있다면 가능하면 작성하는 것도 좋지만, 해당 속성들은 비교적 변경사항이 잦기 때문에 작성하지 않는 것을 선호하는 이유이기도 하다.
조인 칼럼을 사용하자
1 2 3 4 5data class Member( @ManyToOne(fetch = FetchType.LAZY, optional = false) @JoinColumn(name = "team_id", nullable = false) // 생략 가능 var team: Team ) : EntityAuditing()
OneToOne, ManyToOne 정보 같은 경우 연관관계의 주인에서 FK를 갖게 되기 때문에 칼럼 에노테이션을 작성할 수 있다. 연관관계 에노테이션으로 작성하면 기본적으로 PK 기반으로 되기 때문에 생략 가능하다.
하지만 칼럼 에노테이션을 사용하는 이유와 마찬가지로 조인 칼럼 에노테이션을 작성하는 것을 선호한다. nullable, unique, updatable 등 정보를 많이 표현해 준다.
무엇보다 nullabel 설정에 따른 조인 전략이 달라질 수 있어 성능상 이점을 얻을 수 있는 부분이 있다. 이 부분은
step-08: OneToOne 관계 설정 팁 : 제약 조건으로 인한 안정성 및 성능 향상에서도 포스팅 한적 있다.
그리고 익숙하지 않은 프로젝트에서 칼럼명으로 엔티티 클래스를 찾는 경우가 있는데 이런 경우 해당 칼럼명으로 쉽게 검색할 수 있어 약간의 장점이 있다.
양방향 보다는 단방향으로 설정하자
기본적으로 JPA 연관관계 설정은 단방향으로 설정하는 것을 선호한다. 사실 이것은 선호하기보다는 가이드 쪽에 가깝다. 우선 양방향 연관관계를 작성하면 생각 보다 고려할 부분이 많다. 양방향 편의 메서드, 디펜던시 사이클 문제가 있기 때문이다.
무엇보다 OnyToMany, ManyToOne 관계는 설정은 선호하지 않는다. OneToMany를 관계를 갖게 되면 N+1 문제(물론 OneToMany를 관계에서만 N+1 문제가 발생하지는 않는다.) OneToMany 2개 이상 갖는 경우 카테시안 곱 문제로 MultipleBagFetchException 발생한다. 양방향 메서드를 반드시 지정해야 할 이유가 없다면 단방향 관계를 지향하는 것이 좋다고 생각한다.
Open Setting View false로 두자

OSVI는 영속성 컨텍스트를 View 레이어까지 열어 둘 수 있다. 영속성 컨텍스트가 살아있으면 엔티티는 영속 상태로 유지된다. 따라서 뷰에서도 지연 로딩을 사용할 수 있다. 하지만 View에서 트랜잭션을 계속 가지고 있는 것이 좋다고 생각하지 않는다.
기존 OSVI 문제를 해결하기 위해서 비즈니스 계층에서만 트랜잭션을 유지하는 방식의 OSVI를 스프링에서 지원해주고 있긴 하지만 ModelAndView를 사용하지 않고 단순하게 API로 JSON 같은 응답을 내려주는 서버로 사용한다면 View false를 false 두는 것이 좋다.(기본이 true이다)
객체 그래프 탐색은 어디까지 할것인가? 좀 끊자!
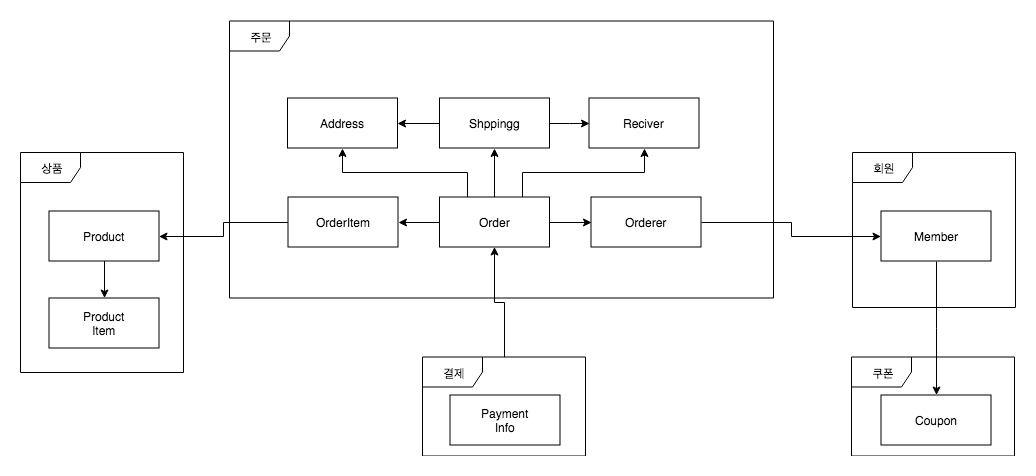
관계형 데이터베이스는 FK를 통해서 연관 탐색을 계속 진행할 수 있다. 마찬가지로 JPA도 객체 그래프 탐색을 통해서 연관 탐색을 계속 진행할 수 있다. 이것은 그래프 탐색의 오용이라고 생각한다.
DDD를 프로덕션 레벨에서 진행해본 적은 없지만 DDD에서 주장하는 에그리거트 단위, 그 단위가 다르면 객체 탐색을 끓는 것은 매우 동의한다.
위 처럼 주문, 회원이 있는 경우
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@Entity @Table(name = "orders") data class Order( @Column(name = "amount", nullable = false) var amount: BigDecimal, @Embedded var orderer: Orderer ) : EntityAuditing() @Embeddable data class Orderer( @Column(name = "member_id", nullable = false, updatable = false) var memberId: Long, @Column(name = "email", nullable = false, updatable = false) var email: String )
연관관계를 명확하게 끊는 것이 옳다고 본다. 연관관계를 계속 탐색할 수 있는 것도 문제지만 연관관계를 갖게 되면 주문을 조회한 이후에 회원 정보를 변경할 수도 있다. Order 객체의 책임과 역할이 어디까지 인가를 봤을 때 이렇게 명확하게 끊는 것이 옳다고 본다. 만약 조회가 필요한 경우 Orderer객체에 memberId가 있으니 회원정보가 필요시에 조인해서 가져오면된다.
이것도 가이드 수준으로 생각하고 있지만 아직 DDD를 실무에서 진행해본 적이 없어 막연하게 드는 생각이라 가능하면 에그리거트 기준으로 연관관계를 끊는 것이 좋다고 생각만 하고 있다.
쿼리 메서드는 선호하지 않는다.

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20public interface AccountRepository extends JpaRepository<Account, Long>, AccountCustomRepository { } public interface AccountCustomRepository { List<Account> findRecentlyRegistered(int limit); } @Transactional(readOnly = true) public class AccountCustomRepositoryImpl extends QuerydslRepositorySupport implements AccountCustomRepository { public AccountCustomRepositoryImpl() { super(Account.class); } @Override // 최근 가입한 limit 갯수 만큼 유저 리스트를 가져온다 public List<Account> findRecentlyRegistered(int limit) { final QAccount account = QAccount.account; return from(account) .limit(limit) .orderBy(account.createdAt.desc()) .fetch(); } }
이건 정말 개인적인 선호도이다. 일단 조건이 까다로운 조회용 코드인 경우 쿼리 메서드로 표현하면 너무 장황해서 코드 가독성이 좋지 않다고 본다.
쿼리 메서드를 사용하지 않고 QuerydslRepositorySupport를 이용한 Query DSL 기반으로 모두 작성하는 것을 선호한다. 물론 findByEmail 같은 것들은 쿼리 메서드가 더 편리하고 직관적이다고 생각하지만 위에서도 한 번 언급했지만 예외를 하나를 허용하면 추가적인 예외가 생기게 되기 때문에 아주 명확한 가이드가 없다면 모두 Query DSL 기반으로 작성하는 것을 선호한다.
또 엔티티의 멤버 필드 변경 시에도 쿼리 메서드의 변경돼야 하는 것도 문제라고 생각한다. 물론 인텔리 제이에서 멤버 필드 rename 시에 적절하게 변경해주기도 하고, 스프링에서 쿼리 메서드가 문제가 있는 경우 스프링 구동시 예외가 발생하기 때문에 최소한의 안전장치가 있긴 하지만(이것도 없었다면 쿼리 메서드는 사용하지 않는 것을 가이드 했을 거 같다) 이러한 문제 때문에도 쿼리 메서드를 선호하지 않는다.
물론 Query DSL도 멤버 필드 변경 시에는 문제가 발생한다. 그 문제는 Qxx.class관련 Syntax이기 때문에 더 명확하다는 장점이 있다고 본다.
그리고 무엇보다 비즈니스 로직의 컨텍스트를 메서드명으로 표현 못 한다. 활동하지 않은 휴면 회원의 정의를 마지막 로그인, 회원의 등급, 현재 회원의 상태 등등으로 정의하는 경우 이것을 쿼리 메서드로 작성하면 findByLastLoginatAndStatusAndGrade 와 유사하게 작성해야 한다.
이것은 그냥 쿼리조건문을 뜻할 뿐 활동하지 않은 휴먼회원을 뜻하지 않는다. 물론 앞뒤 코드를 가지고 어느정도 유추는할 수 있지만 정확하게 전달하는 것은 아니다. 차리리 Querydsl으로 코드를 작성하고 findDormancyMember 으로 메서드를 지정하는 것이 훨씬 더 좋다고 생각한다.
또 다른 이유는, 지극히 주관적인 생각이지만 쿼리 메서드는 인터페이스 기반으로 작성하기 때문에 테스트 코드를 작성하지 않는 경우도 많다. 반면 Query DSL 세부 클래스를 작성하기 때문에 뭔가 테스트를 더 작성하게 하는 심리적인 이유도 있는 거 같다.
위 코드처럼 QuerydslRepositorySupport을 이용하면 Repository를 통해서 세부 구현체의 코드를 제공하기 때문에 이런 식의 패턴을 선호한다. 해당 패턴은 step-15: Querydsl를 이용해서 Repository 확장하기 (1)에서 자세하게 다룬 적 이 있다.
Auditing 상속 구조로 사용하자
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27@EntityListeners(value = [AuditingEntityListener::class]) @MappedSuperclass abstract class EntityAuditing { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) var id: Long? = null private set @CreationTimestamp @Column(name = "created_at", nullable = false, updatable = false) lateinit var createdAt: LocalDateTime private set @UpdateTimestamp @Column(name = "updated_at", nullable = false) lateinit var updatedAt: LocalDateTime private set } @Entity @Table(name = "member") data class Member( @Column(name = "username", nullable = false) var username: String, @Column(name = "age", nullable = false) var age: Int = 0, @ManyToOne(fetch = FetchType.LAZY, optional = false) @JoinColumn(name = "team_id", nullable = false) var team: Team ) : EntityAuditing()
@MappedSuperclass, @EntityListeners를 사용하면 반복적인 id, createdAt, updatedAt을 코드를 상속받아 해결할 수 있다. 예전에는 이런 식의 상속 구조는 올바르지 않다고 생각해서 이런 패턴에 거부감이 있었다.
하지만 요즘에는 잘 사용하고 있다. 순수한 객체지향 코드를 유지하는 것도 중요하지만 결국 실리성 있는 부분을 택하는 것도 중요하다고 본다. 특히 코틀린으로 넘어오면서 id, createdAt, updatedAt 등 우리가 직접적으로 핸들링하지 않는 값에 대한 바인딩 방법이 많기 때문에 각각 엔티티에서 처리하면 코드 통일성이 떨어진다. 그래서 이렇게 처리하는 것이 좋다고 생각한다.