JPA 엔터티 카운트 성능 개선하기

JPAJava Persistence API로 애그리게잇을 구현할 때면 흔히 루트 엔터티(전역 식별성을 지니며 주체로 쓰이는 엔터티)에 연관 엔터티 컬렉션을 매핑한다. 때때로 루트 엔터티는 연관 엔터티 컬렉션의 카운트를 제공해야 하는 경우가 있는데 여기서 성능 문제가 발생할 수 있다.
이 글은 연관 엔터티 컬렉션의 카운트를 구할 때 발생할 수 있는 성능 문제를 알아보고 이를 개선해 가는 과정을 소개한다.
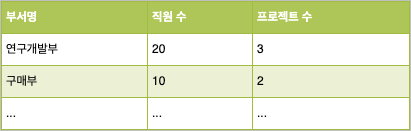
부서 목록을 보여주는 화면
부서 목록과 함께 직원 수와 프로젝트 수를 보여주는 화면을 만든다고 가정해 보자.
데이터 모델은 아래와 같다.
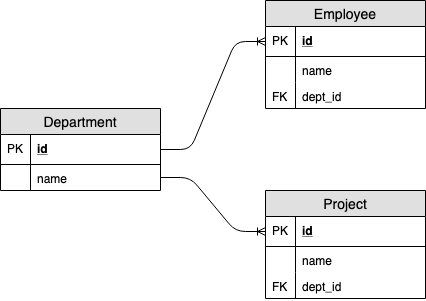
JPA 엔터티로 아래와 같이 매핑할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34@Entity public class Department { @Id @GeneratedValue private Long id; private String name; @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Employee> employees = new ArrayList<>(); @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Project> projects = new ArrayList<>(); // ... } @Entity public class Employee { @Id @GeneratedValue private Long id; private String name; @ManyToOne @JoinColumn(name = "dept_id", referencedColumnName = "id") private Department department; // ... } @Entity public class Project { @Id @GeneratedValue private Long id; private String name; @ManyToOne @JoinColumn(name = "dept_id", referencedColumnName = "id") private Department department; // ... }
직원 수와 프로젝트 수는 어떻게 구할 수 있을까?
먼저 JPQLJava Persistence Query Language로 부서 목록을 조회한다.
1 2 3EntityManager em = emf.createEntityManager(); List<Department> departments = em.createQuery("select d from Department as d", Department.class).getResultList();
이제 부서의 직원 수와 프로젝트 수를 구해야 한다. 쉬운 선택은 Department 객체의 엔터티 컬렉션(employees, projects)의 size() 메서드를 호출하는 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14@Entity public class Department { // ... @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Employee> employees = new ArrayList<>(); @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Project> projects = new ArrayList<>(); public int getCountOfEmployees() { return this.employees.size(); } public int getCountOfProjects() { return this.projects.size(); } }
아래 코드는 잘 동작한다.
1 2 3 4 5 6 7List<Department> departments = em.createQuery("select d from Department as d", Department.class).getResultList(); departments.forEach(department -> { System.out.println("Department : " + department.getName()); System.out.println("CountOfEmployees : " + department.getCountOfEmployees() + "," + "CountOfProjects : " + department.getCountOfProjects()); });
무엇이 문제인가?
문제는 Employee 나 Project 수가 많아질수록 조회 속도가 느려진다는 것이다. 왜일까? 실제로 JPA가 실행한 SQL 로그를 보면서 확인해 보자.
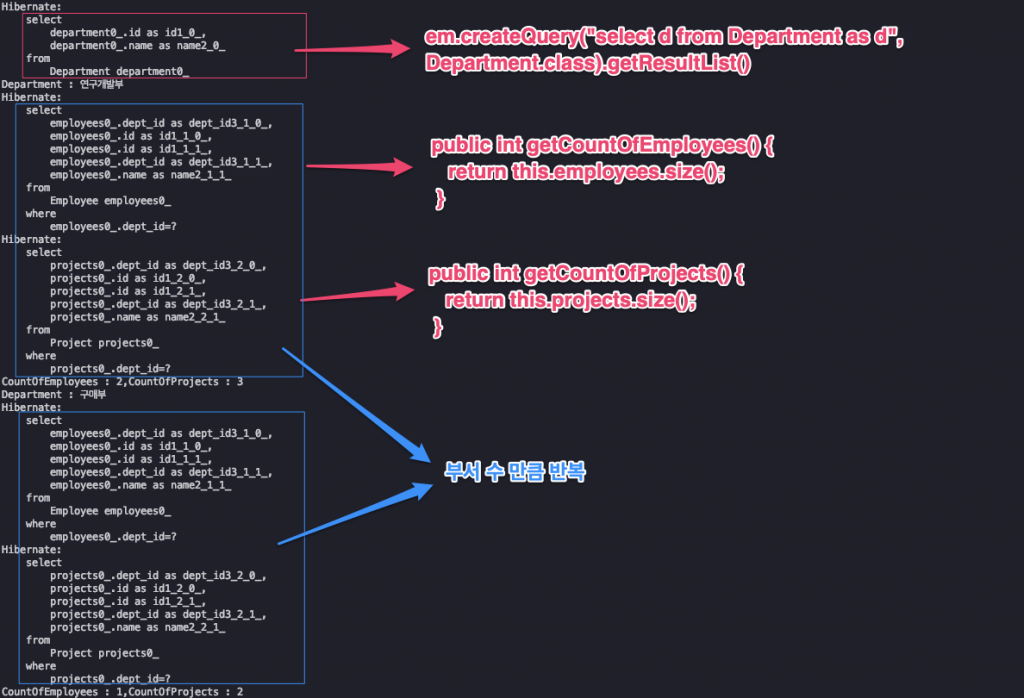
size() 메서드를 호출하면 JPA는 Employee, Project를 실제 데이터베이스에서 조회(SELECT)하여 Department의 매핑 컬렉션(List<Employee> employee, List<Project> projects)에 넣는다. 그리고 컬렉션의 수를 반환한다. 이렇게 동작하는 이유는 JPA 페치Fetch 전략과 관계가 있다.
JPA는 기본적으로 연관 엔터티(Employee, Project)가 컬렉션이면 지연 로딩Lazy Loading 패치 전략이다. 지연 로딩이라는 것은 연관 객체를 처음부터 데이터베이스에서 조회하는 것이 아니라, 실제 사용하는 시점에 데이터베이스에서 조회하는 것이다. 왜냐하면 사용할지 말지 모르는 데이터를 미리 조회하는 것은 성능 상 좋지 않기 때문이다. 그래서 Department를 조회했을 때 연관 엔터티 컬레션을 데이터베이스에서 조회하지 않은 것이다.
1 2 3 4 5 6 7 8 9 10List<Department> departments = em.createQuery("select d from Department as d", Department.class).getResultList(); /* Hibernate: select department0_.id as id1_0_, department0_.name as name2_0_ from Department department0_ */
엔터티 컬렉션 사용 시점 즉, size()를 호출 하니 그때야 JPA가 데이터베이스에서 조회한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36System.out.println("CountOfEmployees : " + department.getCountOfEmployees() + "," + "CountOfProjects : " + department.getCountOfProjects()); @Entity public class Department { // ... public int getCountOfEmployees() { return this.employees.size(); } public int getCountOfProjects() { return this.projects.size(); } } /* Hibernate: select employees0_.dept_id as dept_id3_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id3_1_1_, employees0_.name as name2_1_1_ from Employee employees0_ where employees0_.dept_id=? Hibernate: select projects0_.dept_id as dept_id3_2_0_, projects0_.id as id1_2_0_, projects0_.id as id1_2_1_, projects0_.dept_id as dept_id3_2_1_, projects0_.name as name2_2_1_ from Project projects0_ where projects0_.dept_id=? */
요컨대, 단순히 카운트만을 조회하기 위해서 연관 엔터티를 사용한다면 데이터(Employee, Project)가 많아지면 많아질수록 SQL 실행 속도가 느려질 뿐만 아니라 데이터를 담는 컬렉션도 많은 메모리를 사용하기 때문에 점점 성능이 떨어진다. 더 큰 문제는 카운트를 조회하는 일련의 과정이 Department 수만큼 반복한다는 것이다.
부서 목록 화면에서 실제로 사용하는 것은 카운트뿐이다. 다른 연관 엔터티 속성을 사용하지 않는다. 그렇다면 카운트만 추출해서 성능을 개선할 수 있지 않을까?
개선 1
카운트만 따로 조회하기 위해 JPQL 카운트 쿼리를 만들어 실행한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42List<Department> departments = em.createQuery("select d from Department as d", Department.class).getResultList(); /* Hibernate: select department0_.id as id1_0_, department0_.name as name2_0_ from Department department0_ */ for (Department department : departments) { System.out.println("Department : " + department.getName()); // 카운트 질의 실행 Query countQuery = em.createQuery("select " + "(select count(e) from Employee e where e.department.id = d.id) as emp_cnt, " + "(select count(p) from Project p where p.department.id = d.id) as proj_cnt " + "from Department d where d.id = :departmentId") .setParameter("departmentId", department.getId()); Object[] singleResult = (Object[])countQuery.getSingleResult(); /* Hibernate: select (select count(employee1_.id) from Employee employee1_ where employee1_.dept_id=department0_.id) as col_0_0_, (select count(project2_.id) from Project project2_ where project2_.dept_id=department0_.id) as col_1_0_ from Department department0_ where department0_.id=? */ System.out.println("CountOfEmployees : " + singleResult[0] + "," + "CountOfProjects : " + singleResult[1]); }
Department의 연관 엔터티 컬렉션을 사용하지 않고 카운트 쿼리를 따로 만들어 실행 했기 때문에 이 전에 발생했던 엔터티 컬렉션 데이터베이스 조회가 일어나지 않았다.
하지만 카운트 쿼리를 Department 수만큼 반복해서 실행하는 것은 여전히 문제다.
개선 2
아마도 SQL에 능숙한 분들이라면 개선 과정이 매우 답답했을 것이다. 그것도 그럴 것이 SQL 하위 쿼리Sub-queries로 Department 조회 할 때 카운트를 함께 조회하면 간단히 해결할 수 있기 때문이다.
1 2 3 4 5SELECT dept.id , dept.name , (SELECT count(*) FROM employee e WHERE e.dept_id = dept.id) as emp_cnt, , (SELECT count(*) FROM project p WHERE p.dept_id = dept.id) as proj_cnt, FROM department dept
어떻게 JPA로 구현할 수 있을까?
카운트 컬럼(emp_cnt, proj_cnt)는 Department에 실제하지 않는 가상 컬럼이다. JPA 명세Specification는 아니지만 하이버네이트Hiberante에서 제공하는 Formula 어노테이션으로 가상 컬럼을 매핑할 수있다. Formula 어노테이션 사용시 알아두어야 할 점은 하이버네이트 문서에도 언급되어 있지만 네이티브 SQL을 사용한다는 것이다.
2.3.20. @Formula Sometimes, you want the Database to do some computation for you rather than in the JVM, you might also create some kind of virtual column. You can use a SQL fragment (aka formula) instead of mapping a property into a column. This kind of property is read-only (its value is calculated by your formula fragment) - https://docs.jboss.org/hibernate/stable/orm/userguide/html_single/Hibernate_User_Guide.html#mapping-column-formula

Formula로 가상의 카운트 컬럼을 Department에 매핑하고 여기에 하위 쿼리를 사용한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16//... import org.hibernate.annotations.Formula; @Entity public class Department { // ... @Formula("(select count(*) from employee e where e.dept_id = id)") private int countOfEmployees; @Formula("(select count(*) from project p where p.dept_id = id)") private int countOfProjects; public int getCountOfEmployees() { return this.countOfEmployees; } public int getCountOfProjects() { return this.countOfProjects; } }
아래 코드를 실행해 보면 Department를 데이터베이스에서 조회할 때 하위 쿼리로 카운트도 함께 조회하는 것을 확인할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27List<Department> departments = em.createQuery("select d from Department as d", Department.class).getResultList(); /* Hibernate: select department0_.id as id1_0_, department0_.name as name2_0_, (select count(*) from employee e where e.dept_id = department0_.id) as formula0_, (select count(*) from project p where p.dept_id = department0_.id) as formula1_ from Department department0_ */ departments.forEach(department -> { System.out.println("Department : " + department.getName()); System.out.println("CountOfEmployees : " + department.getCountOfEmployees() + "," + "CountOfProjects : " + department.getCountOfProjects()); });
GitHub
전체 코드는 필자의 GitHub 저장소에서 확인할 수 있다.