Logstash 필터 grok 특징 하나

윈도우 이벤트 로그의 Elasticsearch 연동 시, winlogbeat를 이용하면 한글 인코딩같은 거 신경 안 써도 되고 정말 편하다. 특히 로그 필드 정규화는 이래도 되나 싶을 정도로 알아서 다 해준다. 이래저래 이벤트 로그는 다루기 참 편한 것 같다. Logparser만 있어도 거의 RDB처럼 분석할 수 있으니까.
그런데 nxlog 등을 통해 이미 이벤트 로그를 수집하고 있다면, winlogbeat를 이용한 재구축은 번거로울 것이다. 이렇게 이미 텍스트 형식으로 수집된 이벤트 로그의 필드 정규화가 필요하다면 grok 필터가 최선. 다음은 Logstash 설정.
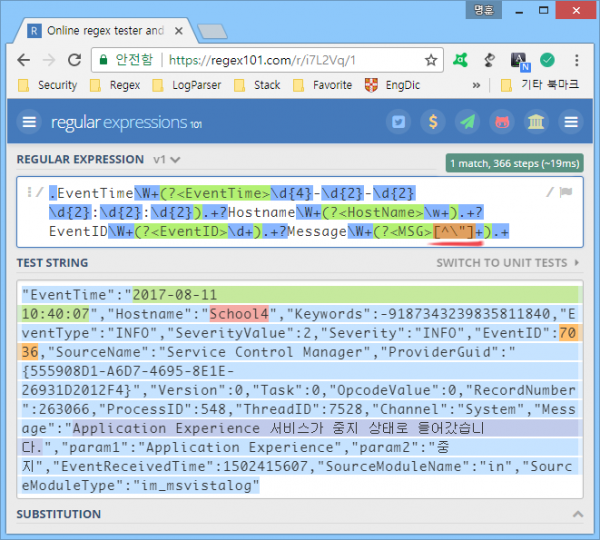
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24input { file { path => "d:/event.log" start_position => "beginning" sincedb_path => "/dev/null" #마지막으로 읽은 로그 무시, 반복 테스트 시 필수 codec => plain { charset => "CP949" #한글 인코딩 } } } filter { grok { match => { "message" => ".EventTime\W+(?<EventTime>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+?Hostname\W+(?<HostName>\w+).+?EventID\W+(?<EventID>\d+).+?Message\W+(?<MSG>[^"]+).+" } } date { match => [ "EventTime", "YYYY-MM-dd HH:mm:ss" ] #로그 수집 시간을 실제 로그 발생 시간으로 지정 } } output { elasticsearch { hosts => [ "localhost:9200" ] index => "event_log" } stdout { codec => rubydebug } #로그 전송 과정 디버깅 }
그런데 에러 발생.
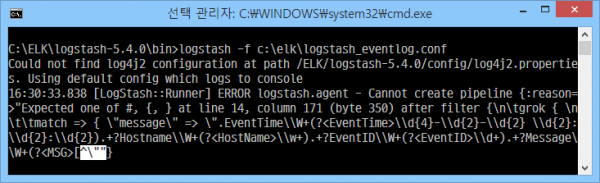
문제가 있다는 14번 라인은 grok 정규표현식 영역인데, EventTime, Hostname, EventID, Message 필드를 추출하는 정규표현식은 문제 없이 잘 동작한다.
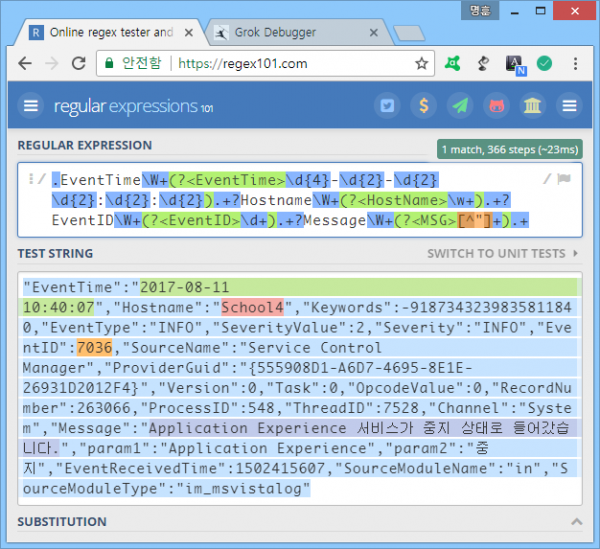
같은 정규표현식으로 grok debugger에서도 필드 추출 잘 되고.
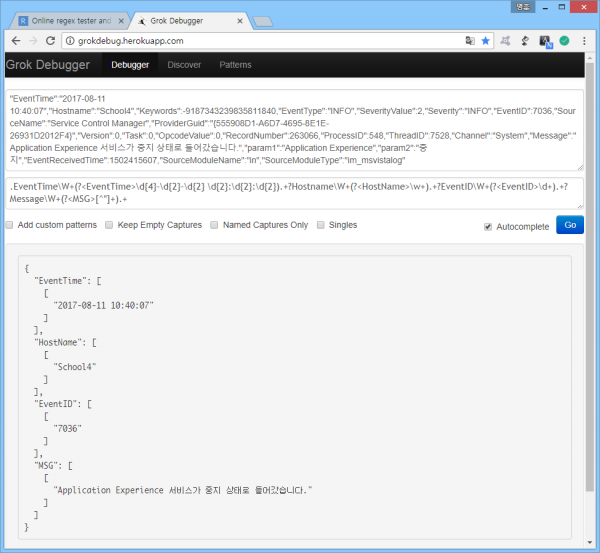
뭐가 문제일까? 정규표현식을 조금씩 바꿔서 테스트 해본 결과 모두 '"' 문자를 검사하는 영역에서 에러가 발생한다는 사실을 알아냈다. 정규표현식에 '"' 문자가 들어가면, grok 정규표현식 구분자인 '"'와 헷갈려서 그런 듯.
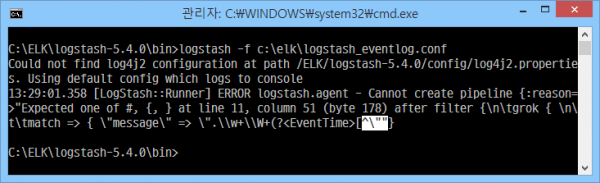
'"'를 grok 정규표현식 구분자가 아닌, 순수 문자로 인식시키기 위해 예외처리(\")를 했다. 이제 잘 됨.
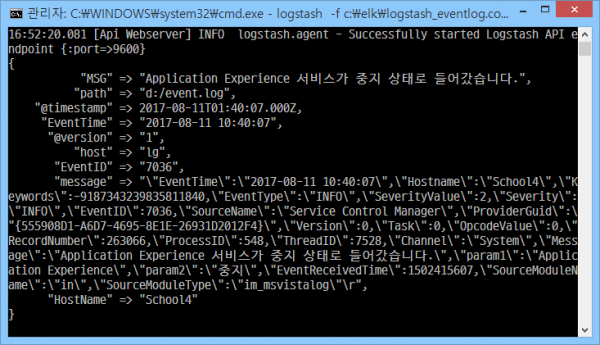
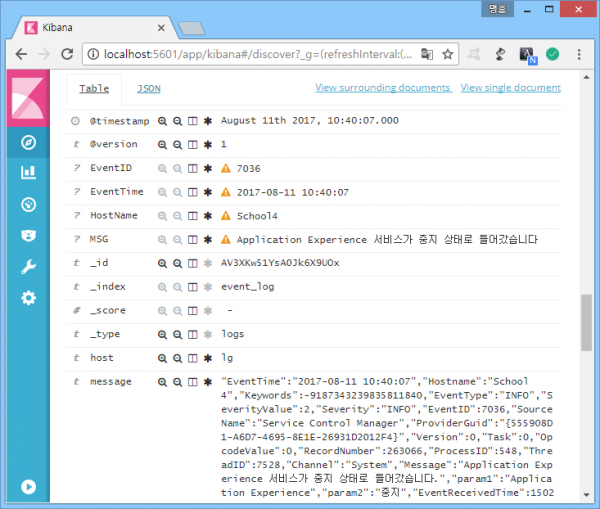
너무 당연한 건데 나만 몰랐나? ㅡㅡ^
Popit은 페이스북 댓글만 사용하고 있습니다. 페이스북 로그인 후 글을 보시면 댓글이 나타납니다.