REST 기반의 간단한 분산 트랜잭션 구현 - 3편 TCC Confirm(Eventual Consistency)

- REST 기반의 간단한 분산 트랜잭션 구현 -1편 TCC 개관
- REST 기반의 간단한 분산 트랜잭션 구현 - 2편 TCC Cancel, Timeout
- REST 기반의 간단한 분산 트랜잭션 구현 - 3편 TCC Confirm(Eventual Consistency)
- REST 기반의 간단한 분산 트랜잭션 구현 - 4편 REST Retry
지난 글에서는 TCCTry-Confirm/Cancel에서 'Confirm 하기 전에 실패하는 경우' 일관성을 유지하기 위한 방법으로 Timeout과 Cancel을 이야기했다. 그리고 휴리스틱 예외를 언급하면서 결과적 일관성 모델을 간단하게 소개하였다.
이번 글은 결과적 일관성 모델을 사용하여 'TCC Confirm 중에 실패하는 경우' 일관성을 유지하는 방법에 대해 다룬다.
예외 시나리오
클라이언트가 OrderService로 주문 요청(1)하고, OrderService는 StockService와 PaymentService로 Try 한다(2)(3). 그리고 '구매 주문'을 생성(4) 후 Confirm 하였다(5, 6). StockService는 재고 처리에 성공한(5.1) 반면 PaymentService는 결제 처리에 실패하였다(6.1).
이런 상황에서 어떻게 일관성을 유지할 수 있을까?
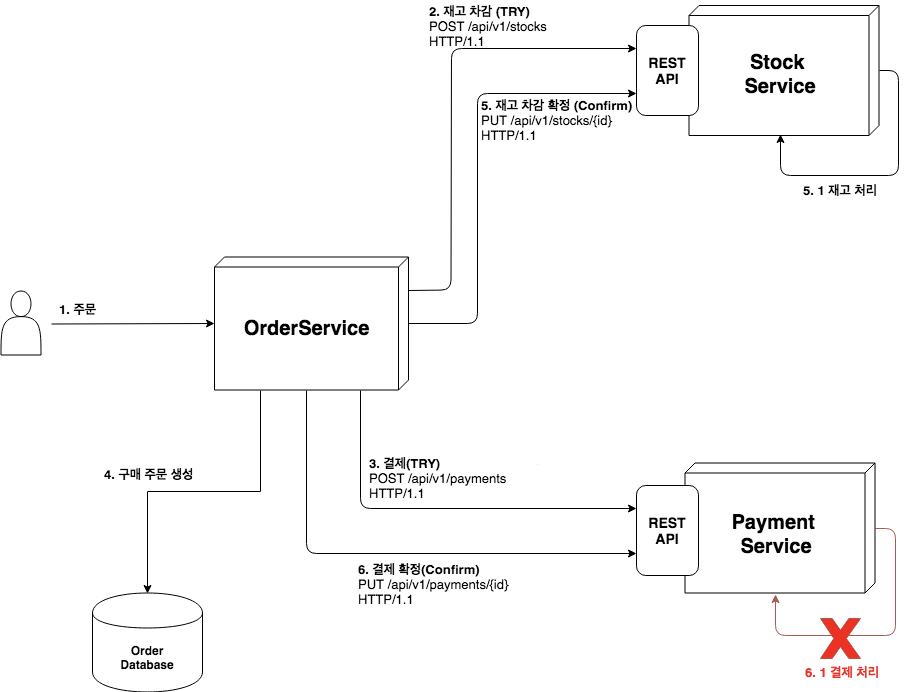
그림. 예외 시나리오
결과적 일관성Eventual Consistency
결제 처리(6.1)가 실패했다고 해서 결국 주문이 실패했다고 보아야 할까? 만약 주문을 실패로 처리한다면 일관성 측면에서 이미 재고 처리(5.1)한 부분에 대한 롤백Rollback은 어떻게 해야 할까? 관계형 데이터베이스에서 트랜잭션 처리할 때에는 데이터의 정합성 보장해야 하기 때문에 엄격한 일관성Strict Consistency모델을 사용한다. 하지만 분산 시스템에서 일관성을 엄격하게 다룰 필요가 있을까?
예를 들어 PaymentService가 결제사 시스템과 결제 연동하고 있다고 가정해보자. 엄격한 일관성 모델을 사용하는 경우 결제사 시스템이 장애가 발생한다면 결제사 시스템의 장애가 PaymentService 그리고 OrderService로 전파되어 결국 주문은 실패하게 된다. PaymentService뿐만 아니라 StockService도 마찬가지이다. 비즈니스 관점에서 이것은 판매자는 판매의 기회를 잃는 것이고 소비자에게는 불만을 줄 수 있는 것이다.
그렇다면 이건 어떨까? OrderService가 Confirm을 전달하면 언제가(미래 특정 시점) 해당 서비스가 책임지고 Confirm을 성공적으로 처리해준다고 믿고 클라이언트에게 성공을 반환하는 것이다.
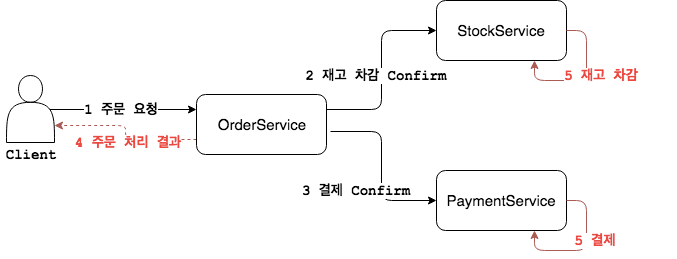
StockService/PaymentService는 OrderService로 부터 받은 Confirm 요청을 큐Queue나 로그Log파일에 큐잉Queuing하고 이를 비동기로 처리 한다. Confirm 처리 과정에서 오류가 나는 경우 계속 재시도[1] 하여 결국(언젠가)은 처리한다.
이렇게 단기적으로 일관성을 잃더라도(클라이언트 입장에서 주문을 성공했다고 받았지만 결제는 되지 않을 수 있다) 결국에는 일관성을 유지하는 모델을 결과적 일관성이라고 한다. 다만 결과적 일관성 모델을 사용하는 경우 단기적으로 일관성을 잃어버릴 때를 대비한 화면 처리 같은 것을 함께 고려해야 한다.
아마존에서도 결과적 일관성 사례를 엿볼 수 있는데 얼마 전 필자가 아마존에서 전자책을 샀을 때의 일이다. 필자의 아마존 계정에 추가해 둔 결제 수단이 문제(유효기간이 만료된 신용카드)가 있다는 것을 모르고 전자책을 구매하였다. 책은 구매 되었으며 볼 수 있었다. 다만 아마존으로부터 결제 수단 오류로 결제가 되지 않았다는 메일을 받았다. 필자는 결제 수단을 올바른 것을 수정하였지만 바로 결제가 되지 않았다. 그리고 이틀 정도 흐른 후 결제가 되었다는 문자를 받았다.
아마존 이외에도 장재휴 님의 내 멋대로 구현한 이벤트 드리븐 글에서도 결과적 일관성 구현 사례를 엿볼 수 있다.
결과적 일관성 구현
API Consumer로부터의 Confirm을 큐잉Queuing하여 비동기로 처리하려면 이를 보관하고 다시 차례로 꺼내어 처리 가능한 신뢰(손실되지 않게)할 수 있는 저장소가 필요하다. Apache Kafka(이하 카프카)는 이런 목적에 잘 부합한다.
카프카를 사용하여 결과적 일관성 모델을 아래와 같이 구현할 수 있다.
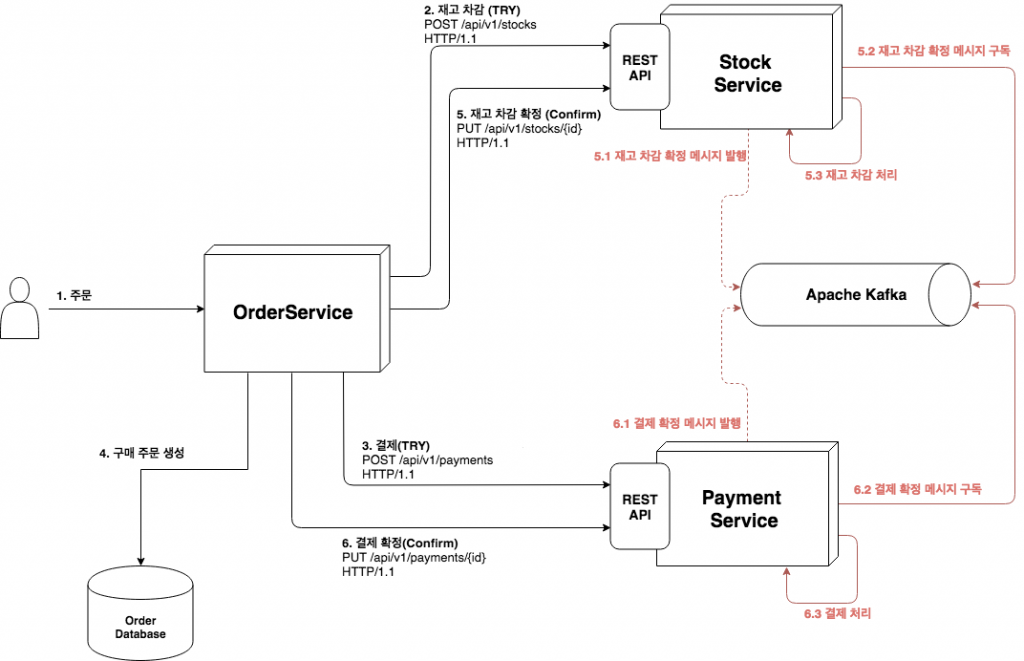
그림. TCC Confirm 결과적 일관성 구현
API Provider가 Confirm 요청을 받으면 예약된 리소스를 조회하여 이를 메시지[2]로 변환하여 카프카로 발행Publish(5.1, 6.1)하고 바로 API에 성공을 반환한다. 그리고 발행한 Confirm 메시지를 구독Subscribe(5.2, 6.2)하여 실제 Confirm 처리(5.3, 6.3) 한다. Confirm 처리 중에 오류가 발생하는 경우 계속 재시도하여 결과적으로는 성공 처리한다.
카프카 토픽Topic 생성
카프카에서는 메시지 발신자(프로듀서)가 메시지를 토픽이라는 메시지 저장소로 발행하고 메시지 수신자(컨슈머)는 토픽을 메시지를 구독한다. 또한 메시지 손실 최소화하기 위해 메시지를 디스크에 저장하고 유지한다.
아래와 같이 kafka-topics 명령어를 사용하여 2개의 토픽(stock-adjustment, payment-order)을 생성한다.
1 2./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic stock-adjustment ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic payment-order
이 글에서 사용한 카프카 설치/실행은 필자의 GitHub 페이지 참조하면 된다.
코드
아래부터는 API Provider 중 하나인 PaymentService 코드의 일부이다.
스프링 카프카 설정
스프링에서 카프카를 쉽게 사용하기 위해서 Spring for Apache Kafka[3]를 사용한다. 아래와 같이 Maven POM 의존성을 추가한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> //... <properties> <spring-kafka.version>2.1.6.RELEASE</spring-kafka.version> </properties> <dependencies> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>${spring-kafka.version}</version> </dependency> //.. </dependencies> </project>
스프링 부트 application.properties에 카프카 설정을 추가한다. API Provider는 메시지 프로듀서이자 컨슈머이기 때문에 둘 다 설정한다.(수동 커밋 부분은 이 글 말미에 자세히 설명한다)
1 2 3 4 5 6 7 8 9 10 11 12 13 14# Kafka spring.kafka.bootstrap-servers=localhost:9092 # Kafka Producer spring.kafka.producer.acks=1 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer # Kafka Consumer spring.kafka.consumer.group-id=payment-group spring.kafka.consumer.auto-offset-reset=latest # 수동 커밋을 하기 때문에 자동 커밋 기능을 false함 spring.kafka.consumer.enable-auto-commit=false spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.listener.ack-mode=manual_immediate
Spring Controller
이전 글의 코드와 동일하다. PathVariable로 id를 매개변수로 받아 Spring Service로 위임한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@RestController @RequestMapping("/api/v1/payments") public class PaymentRestController { private PaymentService paymentService; //... @PutMapping("/{id}") public ResponseEntity<Void> confirmPayment(@PathVariable Long id) { try { paymentService.confirmPayment(id); } catch(IllegalArgumentException e) { return new ResponseEntity<>(HttpStatus.NOT_FOUND); } return new ResponseEntity<>(HttpStatus.NO_CONTENT); } }
Spring Service
confirmPayment 메소드는 Spring Controller로부터 전달받은 id로 예약한 리소스를 조회하고 이를 카프카로 보내기 위해서 PaymentOrderChannelAdapter로 위임한다.
실제로 결제 처리는 payOrder 메소드가 담당한다. payOrder 메소드는 카프카로부터 메시지를 수신하게 되면 호출된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29@Service public class PaymentServiceImpl implements PaymentService { private ReservedPaymentRepository reservedPaymentRepository; private PaymentOrderChannelAdapter paymentOrderChannelAdapter; @Transactional @Override public void confirmPayment(final Long id) { ReservedPayment reservedPayment = reservedPaymentRepository.getOne(id); if(reservedPayment == null) { throw new IllegalArgumentException("Not found"); } reservedPayment.validate(); reservedPayment.setStatus(Status.CONFIRMED); reservedPaymentRepository.save(reservedPayment); // 결제 Confirm 메시지 발행 paymentOrderChannelAdapter.publish(reservedPayment.getResources()); log.info("Confirmed Payment : " + id); } @Transactional @Override public void payOrder(final String orderId, final Long amount) { // ex) 결제사 연동 등등.. // ... final Payment payment = new Payment(orderId, amount); paymentRepository.save(payment); log.info(String.format("Paid Order..[orderId : %s][amount : %d]", orderId, amount)); } // ... }
ChannelAdapter[4]
Spring Service로부터 전달받은 메시지를 KafkaTemplate를 사용하여 토픽에 메시지를 발행한다. 그리고 KafkaListener로 구독할 토픽과 처리할 메소드를 지정한다.
subscribe 메소드에서는 카프카로부터 읽은 메시지를 PaymentRequest 객체로 역 직렬화하고 실제 결제 처리를 위해 Spring Service에 위임(paymentService.payOrder)한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24@Component public class PaymentOrderChannelAdapterKafkaImpl implements PaymentOrderChannelAdapter { private final String TOPIC = "payment-order"; @Autowired private KafkaTemplate<String, String> kafkaTemplate; private PaymentService paymentService; //... @Override public void publish(String message) { this.kafkaTemplate.send(TOPIC, message); } @KafkaListener(topics = TOPIC) public void subscribe(String message, Acknowledgment ack) { log.info(String.format("Message Received : %s", message)); try { PaymentRequest paymentRequest = PaymentRequest.deserializeJSON(message); paymentService.payOrder(paymentRequest.getOrderId(), paymentRequest.getPaymentAmt()); // Kafka Offset Manual Commit ack.acknowledge(); } catch (Exception e) { e.printStackTrace(); } } }
재시도 메커니즘으로써 카프카 수동 커밋
카프카에서는 메시지 컨슈머마다 자신이 가져간 메시지의 위치를 기록한 정보 가지고 있는데 이를 오프셋Offset이라고 한다. 그리고 메시지를 읽어 갈 때마다 오프셋을 갱신하는데 이 동작을 커밋Commit한다고 한다. 커밋은 크게 자동 커밋과 수동 커밋이 있다. 자동 커밋은 말 그대로 메시지를 읽어가면 자동으로 오프셋이 갱신되는 방식이며, 수동 커밋은 메시지 컨슈머가 명시적으로 커밋 하는 방식이다.
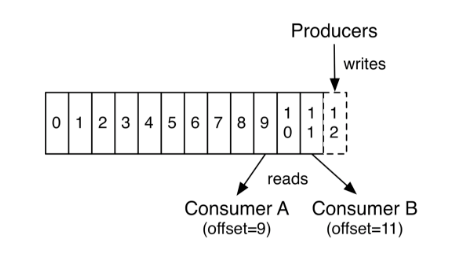
출처 : https://kafka.apache.org/intro
앞서 결과적 일관성에서 재시도를 언급한 적이 있다. 여기에 카프카 수동 커밋을 사용할 수 있다.
Confirm 처리 과정에서 오류가 나는 경우 계속 재시도[1] 하여 결국(언젠가)은 처리 한다.
스프링 카프카에 수동 커밋 사용하기 위해 이미 application.properties에 설정을 추가해 두었다.
1 2 3# ... # 수동 커밋을 하기 때문에 자동 커밋 기능을 false함 spring.kafka.consumer.enable-auto-commit=false
PaymentOrderChannelAdapterKafkaImpl에서 카프카 메시지를 구독하는 subscribe 메소드를 다시보자.
메소드 매개변수로 Acknowledgment를 받아 결제 처리(paymentService.payOrder)가 오류가 없으면 수동 커밋을 하고 반면 오류가 있다면 커밋을 하지 않는다. 커밋 하지 않으면 메시지는 재 수신되므로 메시지는 재 처리된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@Component public class PaymentOrderChannelAdapterKafkaImpl implements PaymentOrderChannelAdapter { //... @KafkaListener(topics = TOPIC) public void subscribe(String message, Acknowledgment ack) { try { PaymentRequest paymentRequest = PaymentRequest.deserializeJSON(message); paymentService.payOrder(paymentRequest.getOrderId(), paymentRequest.getPaymentAmt()); // Kafka Offset Manual Commit ack.acknowledge(); } catch (Exception e) { e.printStackTrace(); } } }
마치며
분산 시스템에서는 여러 가지 이유(예. 네트워크 접속 오류, 일시적인 서비스 중지 등등)로 시스템 간 요청이 실패할 수 있다. 그리고 카프카 수동 커밋을 사용하는 경우 메시지가 중복 처리될 수 있다. 다음 글은 이런 문제를 보완하는 방법에 대해 알아본다.
GitHub
전체 코드는 필자의 GitHub 저장소에서 확인할 수 있다.
주석
[1] 마이크로서비스 아키텍처 구축 5.12.1 나중에 재시도하기
주문을 받고 처리했다는 사실은 우리가 나중에 창고의 수집 테이블에 삽입을 재시도하기에 충분하다. 우리는 이 연산의 일부를 큐나 로그 파일에 큐잉하여 나중에 재시도할 수 있다. 이런 재시도 방법이 의미가 있는 몇 가지 연산에 대해서는 재시도로 해결될 것이라고 추정해야 한다. 이것은 여러모로 최종적 일관성eventual consistency의 또 다른 형태이다. 트랜잭션이 완료되었을 때 시스템이 일관성을 유지하는 상태임을 보장하기 위해 트랜잭션 경계를 사용하는 대신 향후 특정 시점에 시스템이 스스로 일관성을 유지하는 상태가 될 수 있음을 허용한다.
[2] 기업 통합 패턴(Enterprise Integration Patterns) 36쪽 메시징이란?
메시지 자체는 일종의 데이터 구조에 불과하다. 즉, 문자열이나 바이트 배열, 레코드, 객체 같은 같은 것이다. 메시지란 수신자에게서 실행될 명령에 관한 설명이나, 발신자에게서 발생한 이벤트에 관한 설명과 같은, 일종의 데이터라고 해석하면 된다.
[3] 상세한 사용법은 https://docs.spring.io/spring-kafka/docs/2.1.6.RELEASE/reference/html/_reference.html 에서 확인할 수 있다.
[4] ChannelAdapter라는 이름은 Enterprise Integration Patterns에서 차용했다.
채널 어댑터는 메시징 시스템의 메시징 클라이언트로서 애플리케이션 기능을 호출하고 애플리케이션으로부터 이벤트를 수신해 메시징 시스템을 호출한다.- https://www.enterpriseintegrationpatterns.com/patterns/messaging/ChannelAdapter.html
참고 자료
- https://dzone.com/articles/transactions-for-the-rest-of-us
- http://www.inf.usi.ch/faculty/pautasso/talks/2012/soa-cloud-rest-tcc/rest-tcc.html#/title
- 마이크로서비스 아키텍처 구축(Building Microservices: Designing Fine-Grained Systems) - 샘 뉴먼 저
- 기업 통합 패턴(Enterprise Integration Patterns) - 그레거 호프, 바비 울프 공저
- 카프카, 데이터 플랫폼의 최강자 - 고승범 저/공용준 공저