SK텔레콤, Hadoop DW 와 데이터 분석환경 구축사례

최근 하둡(Hadoop)을 중심으로한 오픈소스 빅데이터 플랫폼들의 동향을 살펴보면, Lamda Architecture 로 대변되는 실시간 데이터수집, 처리, 저장, 저장된 데이터의 배치처리, 처리된 데이터의 조회(분산 데이터베이스)의 각 영역에 기술적으로 성숙했다고 볼 수 있는 굵직굵직한 플랫폼들이 이미 자리를 잡은 모습입니다.
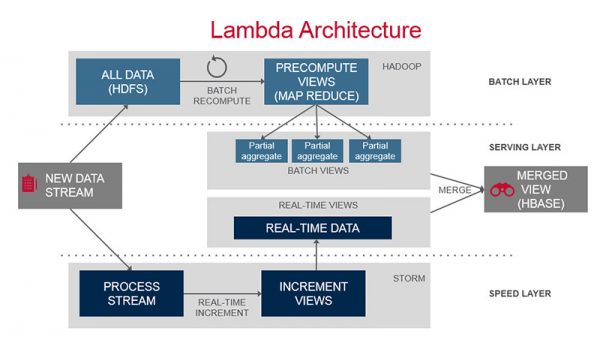
(이미지:http://www.mapr.com/sites/default/files/otherpageimages/lambda-architecture-2-800.jpg)
필자가 위 그림의 아키텍쳐와 거의 유사한 구성으로 사내 Network Management System 을 구현하던 시기(2012년)만해도 실시간 처리 플랫폼으로 마땅한 Reference 가 Storm 외에는 없었던 시기였지만, 지금은 Apache Spark 을 중심으로한 다양한 플랫폼들을 골라(?)쓸 수 있는 상황이 되었고, 기술적으로는 이미 포화상태가 아닌가 생각될 정도입니다. 물론 오픈소스를 가져다 사용하는 것도 기술력이 필요하고 쉬운일은 아니라고 생각하지만, 이미 많은 기업에서 다양한 분야에 적용 및 활용을 하고있는 상태이며 불가능한 일은 아닙니다.
이제 마지막 남은 영역은 데이터를 수집, 처리, 저장 하는 영역이 아닌 분석 영역의 플랫폼이라고 생각되는데, 이는 "빅데이터" 라는 단어의 의미가 시장 초기 하둡을 중심으로 한 기술용어에서, 보다 데이터의 분석 쪽에 초점이 맞춰지고 있는 시장의 흐름과 일맥상통 합니다.
데이터 분석 영역에서 활용되고 있는 기존의 툴들을 살펴보면 MicroStrategy, Tableau, Spotfire 등 BI Solution 으로 불리는 시각화 툴(대부분 상용)들이 있고, Jupyter, Zeppelin 등 보다 자유도가 높은 Interactive 분석 도구들이 최근에 각광을 받고 있습니다. 이미 데이터 분석 영역에 있어 R 이라는 통계분석 툴이 넘버원 자리를 차지한지는 꽤 오래된 이야기이고, 우리나라에서는 Excel 도 분석을 하는데 있어 빠질수없는 도구라고 생각합니다.
최근 김형준님께서 Presto, Zeppelin을 활용한 초간단 BI 시스템 구축사례 를 공유해 주셨는데, 저희도 비슷한 기술요소들로 약간 다른 환경 구축을 진행했던 사례가 있어 공유드릴려고 합니다.
왜 Hadoop DW 를 구축해야하며, 누가? 무엇을 위해 쓸 것인가?
많은 기업들이 빅데이터가 유행이고 무언가라도 하지 않으면 뒤쳐질 것 같은 불안감에 목적도 없이 막연히 DW를 구축하고 외부 전문가 컨설팅을 받으며, 프로젝트를 시작하는 경우가 많습니다. 그냥 높으신 임원의 몇마디 말 때문에...
이 주제는 할말이 매우 많은 영역이긴 하지만, 결론만 말씀드리면 위와같은 이유로의 시작이라면 실패하기 딱 좋은 시작입니다. 대형 솔루션 벤더들의 IT 전문가들이 우리회사의 비즈니스와 Data 를 이해하고 컨설팅을 하려면 매우 많은 시간이 필요할 뿐더러, 시간이 흘러도 좋은 결과를 도출하기는 어렵습니다.
이 주제는 별도의 포스팅을 통해 정리를 해보기로하고, 그렇다면 왜? 언제? Hadoop DW 를 구축해야 할까요?
저희의 경우에는 Hadoop 이 아니면 저장하기 힘들 정도의 많은 데이터 양이 가장 중요한 이유였습니다. 약 100여종의 Legacy 시스템 데이터를 통합을 해야하는 상황이었는데, 그 중 가장 많은 rawdata 를 가진 시스템은 하루에 수천억건의 로그를 쌓으며, 양으로는 수십 TB 가 됩니다.
물론 가장 많은 데이터를 가진 시스템이 나머지 시스템들 보다 압도적으로 데이터가 많긴 하지만, 전체 데이터를 통합해서 저장 분석하려면 비용적인 측면, 시스템의 운영/유지보수를 감안했을 때 Hadoop 외에 대안은 없었습니다.
"DW 를 구축하면 누가 쓸것인가?" 에 대한 답변은 먼저 사내 구성원들의 인력구성과 그분들이 데이터를 분석할때 사용하는 Legacy 시스템에 대한 분석이 필요한데, 아래 그림을 기준으로 인력 구성부터 살펴보도록 하겠습니다.

(이미지:http://www.marketingdistillery.com/)
그림에 표현된 전문 영역을 저희회사 구성원 기준으로 구분하면 아래와 같이 나눌 수 있는데,
- MATH & STATISTICS 이 영역에 해당하는 전문가는 대부분 경력직으로 외부에서 입사하신 분이 많습니다. 머신러닝, 딥러닝 등 알고리즘을 기반으로한 데이터 모델링, 데이터마이닝 등에 전문지식을 가지고 계시며, R 등의 통계 툴들을 잘 다루시지만 N/W 도메인에 대한 전문지식은 부족하시고 전체 구성원 중의 비율로 따지면 매우 극소수에 해당되는 분들입니다.
- PROGRAMING & DATABASE 프로그래밍과 데이터베이스라고 되어 있지만, 주로 오픈소스 하둡의 에코시스템 관련 기반지식을 바탕으로 MapReduce, Hive, Tez, Storm, Spark, NoSQL 등 분산처리 기술들에 능숙하신 분들입니다. 물론 Computer Science, S/W 기본지식과 SQL, Java, Python 등 프로그래밍 언어도 잘 다루시는 분들인데, 이런 분들 또한 구성원 전체 중 비율로 따지면 매우 극소수에 해당됩니다.
- DOMAIN KNOWLEDGE & SOFT SKILLS 대부분의 구성원이 이 영역에 해당되시고, 저희 회사는 통신회사이다보니 대부분 N/W 도메인의 전문가들 이십니다. 주로 데이터 분석업무를 하실 때 Excel 을 많이 사용하시고 그중에서 소수는 SQL 을 사용할 수 있습니다.
- COMMUNICATION & VISUALIZATION 이 부분은 별도의 전문가 집단이 있다기 보다는, 위의 3가지 영역에 해당하는 모든 분들이 공통적으로 해야하는 부분입니다. 사실 한가지 분야의 전문가가 되기에도 매우 많은 노력과 시간이 필요하며, 모든 분야를 다 잘하는 사람을 필자는 아직까지 본적이 없습니다. 따라서 어느 한가지 분야를 바탕으로 다른 분야의 전문가와 소통하는 부분이 매우 중요하며, 데이터를 분석하는 과정에서 시각화를 하는 부분도 모두가 해야하는 공통 영역입니다.
지금까지 왜 Hadoop으로 DW를 구축해야 하는지와 누가 쓸것인가에 대한 대상을 정리했는데, 그렇다면 "기존 환경보다 어떤 점이 좋아지는가?" 에 대한 답변이 필요합니다.
저희의 경우에는, 평소 통신 서비스의 품질을 높이거나 장애상황의 원인을 분석 후 개선을 위한 Action Item을 도출하기까지, 무선환경의 데이터부터 N/W 장비들의 성능통계, 고장/알람 메세지, 시스템작업내용, 호처리 단계의 프로토콜 데이터 등, 서로 다른 다양한 시스템의 데이터를 연계분석 해야하는 Needs 가 있었습니다.
물론 많은 부분이 실시간 감시가 가능하도록 NMS 구현이 되어 있긴 하지만, 그럼에도 불구하고 Legacy 시스템에서 필요한 데이터를 엑셀로 다운로드 받고, VLOOKUP, PIVOT 등을 돌려가며 어렵게 분석을 해야하는 경우는 늘 발생하게되며, 이 또한 데이터의 양이 많아지면 쉽지 않은 문제로 다가오게 됩니다.
따라서 DW 구축을 통해 데이터를 분석하는 사람에게 보다 분석과정에 집중할 수 있는 환경을 제공할 수 있고 필요한 데이터를 만들거나 확보하는데 들어가는 전처리 단계의 시간을 비약적으로 개선할 수 있으며, 이 부분이 저희가 DW 구축을 시작한 가장 큰 이유이기도 합니다.
분석에 필요한 데이터를 빠르게 확보하고 내가 보고싶은 관점에서 보는 것이 어려운 상황인데, "빅데이터"라는 미명하에 인사이트를 찾는데만 혈안이 되어 많은 노력을 해봤자 좋은 결과를 기대하기란 매우 어렵습니다.
Data Warehouse Architecture
2016년 현재 N/W 데이터(사내 전체 시스템은 아님)를 분석하기 위한 인프라의 아키텍처는 아래와 같습니다.
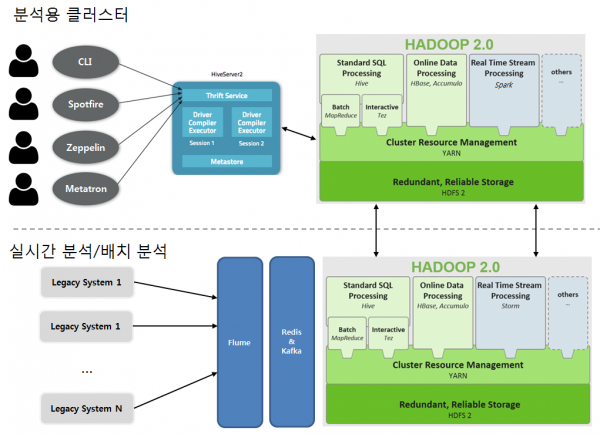
먼저 클러스터를 두개로 나누어서 사용하고 있는데, 재해복구(DR)를 위한 분리는 아니고 서로 용도가 다릅니다. 아래쪽 클러스터에서는 여러가지 측면의 장애상황 대응을 위한 실시간 감시(Storm)가 주요 목적입니다(운영중에 감시 대상 추가가 되기도 합니다). 또한 하둡 클러스터에 저장된 rawdata로 부터 분석에 필요한 여러가지 통계들을 생성해 냅니다. 이러한 통계 생성 Job 들은 항상 주기적으로 실행되기 때문에 Ad-hoc 한 분석 Job 에 의한 영향을 받아서는 안되고 YARN 혹은 Mesos 로도 통제될 수 없는 네트워크 자체를 분리한 분석용 클러스터(위쪽)가 별도로 존재하게 됩니다.
다음은 주요 플랫폼 구성요소와 선정사유, 사용중 장단점위주로 정리해 보았습니다.
- Data Storage 두개의 클러스터 모두 기본 데이터 저장소는 HDFS(Hadoop Distributed File System) 입니다. 매우 큰 양의 파일들을 저장해야 하기 때문에 별다른 대안이 없으며 아래쪽 클러스터는 CDH 기반, 위쪽 클러스터는 Apache Hadoop 으로 구성되어 있습니다. 서로 다른 Hadoop 버전을 쓰는 것은 구축시기의 차이 때문이고 큰 이유는 없습니다. HDFS 의 가장 큰 장점은 저가의 비용으로 큰 Capacity 의 저장소를 확보할 수 있으며 데이터의 백업 등 안정성을 확보하고 유지하는 데 있어 큰 비용이 들지 않는다는 점과, MapReduce를 비롯한 다양한 쿼리 엔진들을 바탕으로 큰 데이터를 빠르게 분산처리 할 수 있다는 점 입니다. 단점으로는 작은 파일을 많이 저장하기에 적합하지 않은 부분과, NameNode(HDFS 의 Master 데몬) 이중화 구성을 한다고 해도 전체 파일 갯수와 Block 갯수(HDFS 는 하나의 파일을 여러개의 Block 으로 관리)가 많아지는 경우 Fail over 에 꽤 오랜시간이 걸리는 부분인데, 저희의 경우에는 수억개의 파일과 Block 을 저장하고 있어 Active NameNode 장애 시 Standby NameNode 로 Fail Over 되는데 10분 이상의 시간이 걸리고 있습니다. 하지만, HDFS 를 사용하며 얻을 수 있는 많은 장점을 생각하면 이정도의 단점은 충분히 감내할 수 있는 수준입니다.
- OLTP 저장소 OLTP 저장소는 데이터의 양을 포함한 여러가지 요소를 감안하여, RDB(Oracle, MariaDB), HBase, Druid 를 혼용해서 사용하고 있습니다. 많은 분들이 하둡을 RDB 와 비교를 하시는데, 하둡은 RDBMS 의 대체 솔루션이 아닌 상호 보완적인 관계로 인프라 구성을 하는게 맞습니다. 하둡을 쓰더라도 RDB 의 역할은 여전히 필요하고, 앞으로도 없어지지 않을 DB라고 생각합니다. 저희의 경우는 Oracle 을 주로 실시간 감시를 위한 NMS의 데이터 조회용 저장소로 사용하고 있으며, MariaDB 는 오픈소스 플랫폼들의 Meta Store(Hive 등)로, HBase 는 양이 매우 큰 rawdata 의 조회용도로 사용 중 입니다. 마지막으로 Druid 는 자체 개발중인 BI 솔루션인 Metatron 에서 사용하는데 Metatron 에 대해서는 이 글의 뒷부분에서 소개하겠습니다.
- Streaming Platform 실시간 처리를 위한 플랫폼으로, 아래쪽 클러스터에서는 Storm을 위쪽 클러스터에서는 Spark 을 사용하고 있습니다. Storm 으로 클러스터를 구축하던 2012년에는 지금 처럼 Spark 이 대세인 시절이 아니다보니 선택의 여지가 없었지만, 초당 수십만건 이상씩의 Streaming 처리를 4년째 훌륭히(?) 해내고 있습니다. Stream 처리를 위한 Storm 클러스터의 앞뒤로 각각 Redis와 Kafka가 큐의 역할을 담당하고 있어, 특정 이벤트가 발생하여 데이터가 갑자기 증가할 수 있는 부분에 대비하고 있습니다. 위쪽에 있는 Spark 은 현재 Stream 데이터 처리용으로는 사용하지 않고 있으며, 분석용 도구인 Spotfire(BI Solution) 의 쿼리 엔진(SparkSQL)이자 Machine Learning 을 분산처리 하기 위한 분석용 플랫폼으로 사용중인데 앞으로 이 부분의 활용도를 좀 더 높이기 위한 준비를 하고 있습니다.
- SQL on Hadoop 데이터의 분산처리도 여러가지 방법들을 혼용해서 사용하고 있는데, 복잡한 Batch Job 들은 MapReduce 를 통해 구현이 되어있고, 아래쪽 하둡 클러스터에서는 Hive 를 기본 쿼리 엔진으로 사용하고 있으며, 위쪽 클러스터에서는 Hive on Tez 와 Spark 을 혼용하여 사용하고 있습니다. SQL on Hadoop 을 사용할 때는 데이터를 어떤 파일 포맷으로 저장할 것인지도 중요한데, DW 구축 초기에는 ORCFile 형태로 저장을 했었으나 Measure 컬럼의 갯수가 많아지는 경우 과도한 메모리 사용량을 보이는 문제(운영중에 Out Of Memory Exception 자주 발생)가 있어 현재는 사용하지 않고 있으며, 파일 포맷에 대해서는 데이터 타입, 실제 데이터의 Cardinality, 읽기 패턴 등 고려할 요소가 많아서 지금도 계속 고민 중에 있습니다.
DW 의 아키텍처는 발전하는 오픈소스 기술과 내부환경 요소들을 감안하여 지속적으로 변경 중에 있으며, 그 방향성은 보다 많은 사람들이 보다 쉽게 데이터에 접근하여 원하는 분석(단순 데이터 조회에서부터, 머신러닝 알고리즘의 분산처리까지)을 할 수 있게 만드는 것 입니다.
데이터 분석 도구
처음 DW 를 구축하던 시점부터 데이터를 분석하고자 하는 사람들에게 특정 툴을 강요하지 않으려고 노력했습니다. 다양한 도구를 통해 원하는 분석을 할 수 있는 환경 구성을 하는게 작은 목표였으며 이로 인해 현재는 많은 사람들이 서로 다른 방법으로 DW의 데이터를 분석하고 있습니다.
- TIBCO Spotfire(BI Solution) 개인적인 생각으로 Bisiness Intelligence 라는 말은 너무 거창한 표현이라고 생각하는데, 더 정확하게는 시각화 (Visualization) 툴이 적합한 표현이 아닐까 합니다. 하지만, 데이터를 분석하는 과정에 있어 시각화는 매우 중요한 부분이라고 생각하며, Spotfire 와 같은 BI Solution 들은 데이터를 시각화 하는데에 매우 특화된 기능을 가지고 있는 강력한 분석 도구입니다. 특히나 Spotfire 의 Drill Down 기능은 데이터를 분석하는 과정에 있어 여러가지 형태의 Chart 를 그리는 시각화 과정을 매우 편하고 쉽게 할 수 있는 유용한 기능입니다. 저희는 Spotfire 를 JDBC 접속을 통해 DW 데이터를 바로 조회할 수 있도록 환경을 구성했는데, 이 환경은 SQL 을 직접 사용하거나 개발을 직접하지 못하는 대부분의 구성원을 위한 분석환경입니다. 이 툴을 통해 주로 엑셀에서 데이터를 분석하는 구성원 대부분의 요구사항을 만족시킬 수 있었으며(Excel Export 기능지원), Spotfire 자체로도 엑셀에서 할 수 있는 대부분의 분석과정을 수행할 수 있어서 사용자가 점점 늘어나는 추세입니다. 하지만 많은 양의 데이터(Local PC 의 메모리를 넘어서는 양)를 분석하기 어려운 점 등의 단점들이 존재하는데, 이러한 부분들을 Metatron 을 통해 극복하기 위해 개발을 진행하고 있습니다.
- SQL on Hadoop 기본적으로 SQL 을 사용할 수 있는 구성원들에게 DW 환경에 쿼리를 실행할 수 있는 Linux 서버의 계정을 할당해 주고 있습니다. 이를 통해 필요한 쿼리 작성과 데이터 추출을 할 수 있는데, 너무 Heavy 한 쿼리가 들어온다던지 작성된 쿼리의 공유가 어려운 점 등의 많은 단점들이 있어 향후 이 분석 환경은 Fade-out 시키려고 하며, Zeppelin, Metatron 등을 활용하는 방향으로 고도화를 진행하고 있습니다.
- R 데이터 마이닝을 전공하신 몇몇 분석가 분들이 계신데, 주로 R을 많이 사용합니다. 이 분들을 위해 메모리가 큰 서버를 RStudio(Web) 를 통해 접속할 수 있도록 환경 구성이 되어 있습니다.
- Zeppelin 다양한 Interpreter 를 제공하는 웹 기반의 오픈소스 분석 툴 입니다. Interactive Analysis 가 가능하고, Scala, Python, SQL 등 사용자가 원하는 언어를 선택하여 분석할 수 있도록 환경제공을 하고 있으며, 스케쥴러는 YARN 을 사용하고 있습니다(yarn-client 모드로 제플린 실행). Zeppelin 은 초기 개발이 되던 시점부터 Spark 과 매우 긴밀한 관계를 갖고 있는데, 저희도 Spark MLlib 을 사용하여 사람이 눈과 머리로 하고있는 분석 과정을 자동화 할 수 있는 영역을 찾아 Machine Learning 시키고 Data Model 을 만드는 것에 많은 노력을 기울이고 있습니다.
- Metatron
위에서 언급했던 많은 분석툴들이 가지고 있는 장점을 극대화하고 단점을 보완하는 분석 도구를 만들기 위해 시작된 프로젝트 입니다. SK텔레콤 Big Data Tech Lab.에서 개발을 하고계시며, Web Based BI Solution 형태를 지향합니다.
 다른 BI Solution 들과는 다르게 Data Source 에 해당하는 분산데이터베이스(Druid)를 전체 솔루션의 구성요소로 포함시켜 많은 양의 데이터를 시각화 하는 부분에 있어 최적화된 솔루션을 개발하고 있으며 여러가지 차트나 편의성을 지원하기 위한 부분도 보완중에 있습니다.
Metatron에 대한 간단한 소개만 해드렸는데, 자세한 내용은 별도의 포스팅을 통해 설명드리도록 하겠습니다.
다른 BI Solution 들과는 다르게 Data Source 에 해당하는 분산데이터베이스(Druid)를 전체 솔루션의 구성요소로 포함시켜 많은 양의 데이터를 시각화 하는 부분에 있어 최적화된 솔루션을 개발하고 있으며 여러가지 차트나 편의성을 지원하기 위한 부분도 보완중에 있습니다.
Metatron에 대한 간단한 소개만 해드렸는데, 자세한 내용은 별도의 포스팅을 통해 설명드리도록 하겠습니다.
성공적인 DW 구축을 위한 고려사항
지금부터는 짧은 경험을 바탕으로 매우 주관적인 이야기를 하려고 합니다. 성공적인 DW 구축이란, 그 성공의 기준을 어디에 두냐에 따라 달라질 수 있으나 필자는 그 기준을 구축된 DW 데이터의 활용성에 두고 있습니다. 꼭 미래를 예측하거나, 새로운 비즈니스 모델을 만들어 내야만 성공하는 것이 아닙니다.
많은 기업들이 외부 분석 전문가들을 채용해서 그들에게 새로운 인사이트 발굴을 기대하지만, 사실 더 효율적인 데이터 분석은 외부에서 영입된 소수의 분석가 보다 사내에 계신 많은 도메인 전문가로부터 나오는 경우가 많습니다. 단지 그분들에게 필요한 데이터가 투명하게 오픈되고 있는가를 살펴봐야하고 이를 잘 하기위한 시스템을 만들어 나가야 합니다.
이러한 관점에서 성공적인 DW 구축을 위한 고려사항을 정리해 봤습니다.
- 양질의 데이터를 확보하라
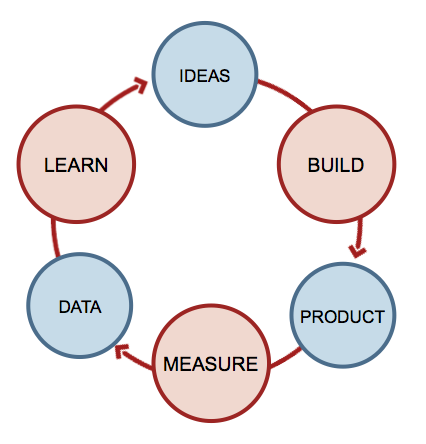 위 그림은 이미 많이 알려져 있는 린 스타트업 프로세스의 Cycle 입니다. 위 과정에서 무엇보다 중요한 부분은 MEASURE 부분이고, 분석의 목적을 잘 설명할 수 있는 Feature 를 가지고 있는 양질의 데이터는 그 이후의 분석 과정을 매우 수월하게 해줍니다. 따라서 무엇보다 고민해야 할 부분은 "분석의 목적에 맞는 양질의 데이터를 가지고 있는가?" 에 대한 고민이며, 없다면 가능한 모든 수단과 방법을 동원하여 양질의 데이터를 생성하는데 노력을 해야합니다. 필자의 경우에도 DW 구축 이전에, 많은 사내 전문가와 함께 현재의 품질 상태를 잘 표현할 수 있는 양질의 데이터를 만드는 것에 많은 노력을 기울였고, 현재 그 데이터를 바탕으로 많은 품질 개선사례들이 나오고 있습니다.
위 그림은 이미 많이 알려져 있는 린 스타트업 프로세스의 Cycle 입니다. 위 과정에서 무엇보다 중요한 부분은 MEASURE 부분이고, 분석의 목적을 잘 설명할 수 있는 Feature 를 가지고 있는 양질의 데이터는 그 이후의 분석 과정을 매우 수월하게 해줍니다. 따라서 무엇보다 고민해야 할 부분은 "분석의 목적에 맞는 양질의 데이터를 가지고 있는가?" 에 대한 고민이며, 없다면 가능한 모든 수단과 방법을 동원하여 양질의 데이터를 생성하는데 노력을 해야합니다. 필자의 경우에도 DW 구축 이전에, 많은 사내 전문가와 함께 현재의 품질 상태를 잘 표현할 수 있는 양질의 데이터를 만드는 것에 많은 노력을 기울였고, 현재 그 데이터를 바탕으로 많은 품질 개선사례들이 나오고 있습니다. - 차별적인 Data Mart 생성하라 서로 다른 시스템의 데이터를 DW에 통합 한다는 것은 다른 의미로 해석하면 이미 다른 곳에 있는 데이터라는 말입니다. 데이터를 모아 노았다고 해서 Join 이 되는 것이 아니며 연계 분석이 필요한 것은 아닙니다. "기존 시스템에 존재하지 않는 어떤 Data 를 새롭게 생성해 낼 것인가?" 에 대한 끊임없는 고민이 필요하고, 이 고민은 DW 를 만드는 사람의 입장이 아닌 데이터를 사용하는 사람 입장에서 진행되어야 합니다. 무엇보다 가장 바람직한 방법은 데이터를 분석할 사람이 DW를 만드는 것인데, 이 부분은 기업의 환경에 따라 쉽지 않은 일이 될 수 있겠습니다.
- 표준을 만드는데 많은 시간을 허비하지마라 여러 종류의 시스템을 통합할 경우 표준화 작업은 매우 중요하며 어려운 작업입니다. 하지만 표준을 만드는 것 자체가 DW 통합의 목적이 아니므로, 가능하면 빠르게 Naming Convention 정도만 정하고 사용자가 실 데이터를 쓸 수 있는 환경을 만들어 제공해야 합니다. 왜냐하면, 성능을 포함한 여러가지 이슈들로 인해 RDB 기반의 데이터 모델링을 통해 설계된 Mart 들은 나중에 결국 못쓰게 되는 경우가 많습니다. 따라서 실제 사용자가 필요로 하는 Mart 를 빠르게 만들어 제공하고 Feedback 을 받아 수정하는 작업의 Cycle 이 빨리 돌아갈 수 있도록 DW 운용을 해야 하는데, 전체 시스템의 표준화 작업부터 하면서 ERD 정의 등의 작업을 수행하면, 도메인 규모에 따라 표준화 작업만 1년이상 걸릴 수 있는 대규모 작업이 될 수 있기 때문입니다.
- 만드는 사람이 헤비유저가 되라 좋은 DW를 만들기 위한 가장 중요한 덕목 중 하나는 만드는 사람이 직접 헤비유저가 되는 것입니다. 쓰지도 않는 사람이 만드는 시스템은 실 사용자의 Needs 가 반영되기 어려우며, DW 구축 작업에 있어서는 통합을 위한 통합으로 끝나게 되는 경우가 많습니다.
글을 마치며...
많은 양의 데이터를 통합하고 연계분석을 해야하는 요구사항이 있다면, Hadoop 기반의 DW 를 구축하는 것이 좋습니다. DW 구축에 필요한 요소기술들이 오픈소스를 중심으로 빠르게 발전하고 있으며, 이를 활용한 환경 구성을 통해 비용절감 및 성능, 유지보수에 있어 많은 이득을 얻을 수 있습니다.
구축된 DW 를 더욱 잘 활용하기 위한 끊임없는 고민과 분석환경 구성을 통해, 보다 많은 구성원들이 데이터를 원하는 관점에서 분석할 수 있다면, 회사내에 데이터 기반의 일하는 문화를 만들어 갈 수 있으며, 이를 통해 많은 성과가 창출될 수 있습니다. 저희의 경우에도 DW 의 활용을 통해 많은 품질개선 사례들이 도출되었고, 이 부분은 지금도 현재 진행형 입니다.
여러가지 생각을 말씀드렸지만 사실 제일 중요한 것은 일을 하는 사람이 아닐까 생각합니다. 저는 운이 좋게도 매우 많은 사내외의 능력자(?) 분들께서 엄청난 도움을 주고계시며, 이 글을 통해 도움을 주신 모든 분들께 다시한번 진심으로 감사 인사를 전하고 싶습니다.
꽤 긴 글이 되었는데, "빅데이터"를 시작하기 위해 DW 구축을 검토하시는 많은 분들께 저희의 구축사례 공유가 조금이나마 도움이 되셨기를 바라는 바입니다.