AWS EMR 을 Terraform 으로 관리 할 때 몇가지 팁들

(이미지 - https://aws.amazon.com/emr/features)
AWS EMR 은 정말 좋은 툴입니다. (가격만 안비싸고 좀만 더 빨리 뜨면)
- 버튼 눌러서 쉽게 만들 수 있고
- Spark, Presto, Flink 등 설치된 클러스터에 필요한 Job 만 던지면 되고
- Zeppelin, Jupyter 등 탐색을 위한 도구도 바로 사용할 수 있습니다.
늘 그렇듯이 해보니 된다 != Production Ready 가 아니므로 실제로 서비스에 활용 하려면 이것 저것 잡아줘야 합니다. 그럼에도 불구하고 이전에 Hadoop 설치하니 운영하니, Spark 세팅은 어떻게 잡을거고 클러스터는 어떻게 나눌것이며 하는 고민들을 우주 저 멀리 날려줬습니다. (예를 들어 EMR 은 머신의 메모리와 CPU 를 고려해 executors, driver memory 등이 기본으로 잡혀 있습니다. 물론 지갑을 위해 빡시게 아껴 쓰기 위해선 따로 잡아 주셔야 합니다만..)
가장 멋진 점은 컴퓨팅 자원이 부족하면 머신 숫자를 3에서 15로 바꾼뒤 버튼을 누르면 됩니다. 증가된 인스턴스는 클러스터에 아주 잘 붙으며, EMR 클러스터위에서 돌아가는 Job 들을 인식해 scale-in, scale-out 을 해냅니다.
기본적인 설명은 이정도 까지 하고 본론으로 들어가서 이번 글에서 다룰 내용은 다음과 같습니다.
- EMR 클러스터의 기본적인 구성 요소에 대해서 알아 봅니다.
- Terraform 으로 EMR 클러스터를 만들고 운영시 고려해야 할 사항에 대해 고민합니다. (Upgrade 등)
- EMR Master 에 고정 IP 를 할당해 UI (RM, Ganglia, Spark History 등) 접근이나 SSH 작업시 귀찮음을 예방해 봅니다.
- ENI 를 이용해 연속된 IP 를 다른 EC2 인스턴스가 선점하지 않도록 예약 합니다. 이 IP 들은 이후에 EMR Master 들에 연속된 IP 를 부여하기 위해 사용합니다.
- EMR Master, Core, Task 인스턴스의 쉬운 구분을 위해 Uptime 에 Tag 를 업데이트 합니다.
- EMR Spot 사용시 주의할 점과 Terraform 에서 Bid Price 를 계산해 봅니다.
1. EMR 구성 요소
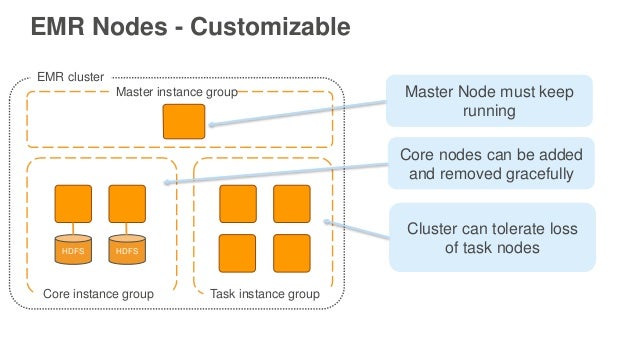
EMR 클러스터를 생성할 때 Master / Core / Task 인스턴스 그룹을 지정할 수 있습니다.
- MASTER
- CORE: HDFS 가 돌아가는 노드이자 Yarn Applicatoin Master 가 실행되는 곳입니다. 많은 회사들이 AWS 위에서 S3 를 EMR 스토리지로 사용하기 때문에 주로 사용되진 않는것 같습니다.
- TASK: 컴퓨팅 노드로서 비용 절감을 위해 Spot 인스턴스로 사용하기도 합니다.
몇 가지 주의해야 할 점이 있는데,
- yarn.app.mapreduce.am.labels 의 디폴트 값은 CORE 입니다. 다시 말해서 Spark Yarn Cluster Mode 의 경우 Application Master (= Driver) 가 Core 노드에서 동작합니다. 따라서 테스트 용도가 아니라면 Core 는 Spot 으로 사용하길 권장하지 않습니다.
- AWS EBS GP2 타입의 IO 성능은 Disk Size 에 따라서 다릅니다. 따라서 Disk 를 사용할 수도 있는 Application 의 경우 EBS Size 를 넉넉히 주시는 편이 낫습니다.
- dfs.replication 의 default 값이 (Core) 노드가 3개까지 1입니다. 다시 말해서 3개 데이터 노드가 있을 때, 하나라도 내려가면 데이터 유실입니다. 따라서 HDFS 를 사용할 경우 직접 세팅해 주는 편이 낫습니다.
EMR 클러스터 생성을 위해서는 IAM Role 과 Security Group 이 필요한데, Role 의 경우 다음 명령어로 기본 Role 들을 생성할 수 있습니다.
1$ aws emr create-default-roles
다음처럼 3 가지 Role 이 생성됩니다: EMR Cluster / EMR EC2 / EMR ASG 늘 그렇듯이 Default 로 생성된 것 보다는 해당 Role 의 퍼미션을 따서 Policy 로 만들고 Custom Role 붙여 사용하는것이 더 안전합니다. 예를 들어, Default EMR EC2 Role 의 경우 해당 계정 내의 모든 S3 에 접근이 가능합니다.
<br/>
Security Group (SG) 의 경우 다음처럼 5개가 필요합니다.
- master-managed
- slave-managed
- master-additional
- slave-additional
- service
managed SG 의 경우 EMR 클러스터 생성시 부족한 in / out bound rule 이 있다면 알아서 추가됩니다. 예를 들어 ICMP 만 열려있고 UDP, TCP 가 안열려 있으면 클려스터 생성시 해당 SG 에 룰이 자동으로 추가가 됩니다.
따라서 EMR 의 경우 사용자가 추가로 열어주고 싶은 것들은 additional SG 를 통해 관리합니다. 예를 들어, Spark History UI 를 열어주고 싶다면 master-additional 에 inbound 18080 rule 을 추가할 수 있습니다.
더 자세한 내용은 AWS EMR Security Groups 에서 확인하실 수 있습니다.
2. Terraform 으로 EMR 운영할 때 몇 가지 팁들
- managed SG 는 AWS EMR 이 채워 주는걸 사용하기 보다는 Terraform 으로 필요한 Rule 을 직접 세팅하는게 추후 관리시 용이합니다. (e.g 어디서 들어온 룰인지)
- EMR 이 기본적으로 동작하는 데 필요한 Rule 을 제외하고 추가로 필요한 Rule 이 있을경우 managed SG 에 넣지 말고 additional SG 에 세팅하면 추후 히스토리 파악 / 제거 등이 용이합니다.
- 다수의 EMR Cluster 가 필요하다고 해서 Terraform 에서 배열로 EMR Cluster 를 생성하지 않습니다. (아래에서 설명)
- Master Instance 에 고정 IP 할당을 하면 Yarn, Spark UI, SSH 등 접근이 편해집니다.
- AWS EBS gp2 타입의 경우 IOPS 가 Disk Size 에 따라 달라지므로 Disk 가 필요한 Application 을 사용한다면 넉넉히 Disk 를 줍니다
- Application Master 는 Core 노드에서 돌아가므로 테스트용도가 아니라면 Core 엔 Spot 을 사용하지 않습니다.
- HDFS 를 사용할 경우 dfs.replication 값을 직접 세팅해서 사용합니다. (default = 1, # of nodes < 4)
- Spot 인스턴스의 경우 resizing 할 경우 오래된 인스턴스 부터가 아니라 빠르게 내릴 수 있는 인스턴스 (실행중인 컨테이너가 없거나 등) 부터 내려갑니다. 따라서 Task 를 Spot 으로 운영할 경우 Instance Group 을 두 개 이상이어야 효율적인 운영이 가능합니다.
(3) 을 조금 더 부연 설명 하면, 회사 내에서 필요한 용도에 따라서 보통 EMR 클러스터를 나누게 됩니다. 예를 들어 spark-batch, spark-stream, service-presto 등.
이 경우 각 용도마다 N 개의 EMR 클러스터를 만들 수 있습니다. 한번 EMR Cluster 를 만들고 나면 이후의 변경은 운영 환경 상 Terraform 에서 일어나지 않을수도 있습니다. Core Instance 수 증가나 ASG Policy 변경 등은 UI 에서 하는게 간편하기도 하고요. 팀 내 모든 사람이 Terraform 을 쓰진 않으니.
따라서 이 경우 만들어진 클러스터는 (e.g spark-batch-01) Terraform 코드 내에서 추후의 변화를 무시하기 위해 ignore_changes 세팅하게 됩니다. 반대로 특정 클러스터 (e.g spark-batch-03) 은 Terraform 에서 수정해야 할 수도 있습니다. Disk 사이즈나 타입을 변경한다던가.
이런 상황이므로 배열로 관리할 경우 같은 용도의 (e.g spark-batch) 0번째 index 의 클러스터는 수정하지 않아야 하는데 2번은 수정해야 하는 등 배열로 만들어진 Terraform 리소스로서 처리하기 난해한 결과가 만들어집니다. 그러므로 spark-batch-production-01, spark-batch-operation-01 (운영성 작업 용, 30일치 데이터라거나) 등 번거럽더라도 배열 대신 aws_emr_cluster 리소스를 만드는 편이 낫습니다.
이렇게 되면 시간이 지남에 따라 Spark 최신 버전 사용등의 이유로 EMR Cluster 를 업그레이드 해야 할 경우에도 편리합니다. 배치 작업의 경우 1번 클러스터의 작업 스케쥴을 다른곳으로 옮기고, 1번 클러스터의 Terraform 리소스만 수정하고 반영하면 됩니다.
(8) 의 경우도 조금 더 설명하면, Task 를 Spot 으로 운영할 경우 Spot, 인스턴스가 강제로 떨어지는 걸 방지 하기 위해 배치 작업이 많은 시간을 피해 Resizing 할 수 있습니다. (Spot 은 오래될 수록 회수될 확률 높음) 그런데, Resizing 시 자동으로 오래된 인스턴스부터 종료되지 않는다면 Spot 인스턴스를 모두 새롭게 갱신하기가 불가능합니다. (EC2InstanceIdsToTerminate=i-f9XXXXf2 처럼 따로 파라미터를 주지 않는 한) 따라서 Task Instance Group 을 A, B 로 나누어 A 를 0 으로 리사이징 만들땐 B 를 원하는 숫자로 만들면, A 그룹의 인스턴스를 모두 종료하고 새 인스턴스들로 Task 를 채울 수 있습니다. (아니면 조금 번거롭지만, Instance Group 내의 모든 인스턴스를 describe 하면서 오래된 것 부터 종료하고, 숫자를 늘리는 방법도 있겠습니다)
제가 속한 팀의 경우에는 다음처럼 EMR 클러스터 1개에 대해서 인스턴스 그룹을 나누어 운영합니다.
- Master (On-demand)
- Core (On-demand)
- Task (Spot)
- Instance Group Static A: 고정 할당되는 Task 그룹 A (Spot 강제 회수를 피하기 위해 B 와 교대로 운영)
- Instance Group Static B: 고정 할당되는 Task 그룹 B (Spot 강제 회수를 피하기 위해 A 와 교대로 운영)
- Instance Group Dynamic: 운영성 작업 (N 일치) 등 동적으로 Task 수를 손으로 변경해야 할 경우 사용 (운영성 작업의 경우 주기적 배치와 별도의 클러스터를 생성해 사용을 권장)
Tip: AWS EMR 에 고정 Private IP 할당 하기
AWS EMR Private IP 할당하기 에 나온 Python 스크립트를 조금 고쳐 다음처럼 작성해 봤습니다. 아래 나와있는 Python 스크립트를 S3 에 넣고 다음처럼 bootstrap action 으로 넣어주시면 됩니다. args 에는 할당할 고정 IP 를 넘겨줍니다.
한 가지 덧 붙이면, 고정 IP 를 다른 인스턴스가 가져가지 못하도록 선점하기 위해 AWS ENI 를 이용할 수 있습니다. 추후 EMR 클러스터 생성시에는 ENI 에서 해당 Private IP 를 제거하고 EMR bootstrap action 의 인자로 넘겨주면 됩니다.
- EMR EC2 Role 에 ec2:AssignPrivateIpAddresses 퍼미션이 필요합니다.
1 2 3 4 5 6 7 8 9 10 11// https://gist.github.com/1ambda/7cf9c3e7f597d0aa3c1b321f26fc284d bootstrap_action = [ ... { path = "s3://${aws_s3_bucket_object.emr_bootstrap_assign_private_ip.bucket}/${aws_s3_bucket_object.emr_bootstrap_assign_private_ip.id}" name = "${aws_s3_bucket_object.emr_bootstrap_assign_private_ip.key}" args = [ "${lookup(local.spark_batch_cluster_01, "fixed_ip")}" ] }, ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31# https://gist.github.com/1ambda/8ff09fada737658089c200b1350e737c #!/usr/bin/python # #Copyright 2017-2018 Amazon.com, Inc. or its affiliates. All Rights Reserved. # #Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file #except in compliance with the License. A copy of the License is located at # # http://aws.amazon.com/apache2.0/ # #or in the "license" file accompanying this file. This file is distributed on an "AS IS" #BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the #License for the specific language governing permissions and limitations under the License. import sys, subprocess is_master = subprocess.check_output(['cat /emr/instance-controller/lib/info/instance.json | jq .isMaster'], shell=True).strip() if is_master == "true": private_ip = str(sys.argv[1]) instance_id = subprocess.check_output(['/usr/bin/curl -s http://169.254.169.254/latest/meta-data/instance-id'], shell=True) interface_id = subprocess.check_output(['aws ec2 --region ap-northeast-2 describe-instances --instance-ids %s | jq .Reservations[].Instances[].NetworkInterfaces[].NetworkInterfaceId' % instance_id], shell=True).strip().strip('"') #Assign private IP to the master instance: subprocess.check_call(['aws ec2 --region ap-northeast-2 assign-private-ip-addresses --network-interface-id %s --private-ip-addresses %s' % (interface_id, private_ip)], shell=True) subnet_id = subprocess.check_output(['aws ec2 --region ap-northeast-2 describe-instances --instance-ids %s | jq .Reservations[].Instances[].NetworkInterfaces[].SubnetId' % instance_id], shell=True).strip().strip('"').strip().strip('"') subnet_cidr = subprocess.check_output(['aws ec2 --region ap-northeast-2 describe-subnets --subnet-ids %s | jq .Subnets[].CidrBlock' % subnet_id], shell=True).strip().strip('"') cidr_prefix = subnet_cidr.split("/")[1] #Add the private IP address to the default network interface: subprocess.check_call(['sudo ip addr add dev eth0 %s/%s' % (private_ip, cidr_prefix)], shell=True) #Configure iptablles rules such that traffic is redirected from the secondary to the primary IP address: primary_ip = subprocess.check_output(['/sbin/ifconfig eth0 | grep \'inet addr:\' | cut -d: -f2 | awk \'{ print $1}\''], shell=True).strip() subprocess.check_call(['sudo iptables -t nat -A PREROUTING -d %s -j DNAT --to-destination %s' % (private_ip, primary_ip)], shell=True) else: print "Not the master node"
Tip: EC2 인스턴스에 MASTER, CORE, TASK 등 Tag Postfix 붙이기
매번 EC2 콘솔에서 이게 EMR Master 인가 아닌가 SG 로 보는게 귀찮아서 업타임에 자신의 Instance Group 을 찾아 AWS CLI 로 Tag 를 덧붙이는 스크립트입니다. EMR bootstrap_action 에 넣어주시면 아래 사진처럼 postfix 로 MASTER / CORE / TASK 와 같은 값들이 붙습니다.
EMR EC2 Role 에 다음의 퍼미션이 필요합니다.
- ec2:DescribeInstances
- ec2:CreateTags
- ec2:DeleteTags
1 2 3 4 5 6 7 8 9 10# https://gist.github.com/1ambda/ed42475177719a059706e74fe9ef4d9b #!/bin/bash export IS_MASTER=$(cat /mnt/var/lib/info/instance.json | jq -r ".isMaster") export INSTANCE_GROUP_ID=$(cat /mnt/var/lib/info/instance.json | jq -r ".instanceGroupId") export CLUSTER_ID=$(cat /mnt/var/lib/info/job-flow.json | jq -r ".jobFlowId") export INSTANCE_ID=$(wget -q -O - http://169.254.169.254/latest/meta-data/instance-id) export INSTANCE_GROUP_TYPE=$(cat /mnt/var/lib/info/job-flow.json | jq -r ".instanceGroups | .[] | select( .instanceGroupId == \"${INSTANCE_GROUP_ID}\") | .instanceRole" | tr a-z A-Z) export CURRENT_TAG_NAME=$(aws ec2 --region ap-northeast-2 describe-tags --filters Name=resource-id,Values=${INSTANCE_ID} | jq -r ".Tags | .[] | select( .Key == \"Name\") | .Value") export NEW_TAG_NAME="${CURRENT_TAG_NAME}-${INSTANCE_GROUP_TYPE}" aws ec2 create-tags --region ap-northeast-2 --resources ${INSTANCE_ID} --tags Key=Name,Value=${NEW_TAG_NAME}
Tip: Spot 인스턴스 Bid Price 를 On-demand 의 X % 로 계산해서 넘기기
Terraform 에서 문자열로 표현된 숫자들의 곱셈을 위해서는 별도의 함수를 사용해야 하고, aws_emr_cluster Terraform 리소스의 Bid Price 는 소수점 두째 자리까지만 유효한 파라미터로 받기 때문에 다음처럼 계산하실 수 있습니다.
1 2 3 4 5 6# https://gist.github.com/1ambda/e4338f272ab2114927884c1f815d72ee locals { spot_default_factor = 0.8 spot_on_demand_price_r5xlarge = 0.304 spot_bid_price_r5xlarge = "${format("%.2f", __builtin_StringToFloat(local.spot_on_demand_price_r5xlarge) * __builtin_StringToFloat(local.spot_default_factor))}" }
요약
ASG 관련해서도 배치와 스트림 용도의 클러스터의 Scaling-in / out 기준이 다르므로 조금 더 써보고 싶었는데, 실제로 EMR 에서 ASG 를 오래 써보지 않아서 다음번에 이야기를 나누어 볼 수 있을것 같습니다.
요약하면, EMR 은 정말 AWS 서비스 중 잘 나온 서비스중 하나이고 잘만 쓰면 아주 쉽고 (조금만) 싸게 대량의 컴퓨팅을 해낼 수 있는 툴입니다.
다만 운영시 귀찮은 점들이 몇 가지가 있으니 툴로서 해결하셔도 좋고 아니면 이 글에 나와있는 것 이외의 다른 문제를 풀고 계시다면 댓글로 공유해주시면 좋을것 같습니다. ^^
References
- AWS EMR ASG: https://aws.amazon.com/blogs/big-data/best-practices-for-resizing-and-automatic-scaling-in-amazon-emr/
- AWS EBS gp2 IO Performance: https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/EBSVolumeTypes.html
- AWS EMR Default Roles: https://docs.aws.amazon.com/ko_kr/emr/latest/ManagementGuide/emr-iam-roles-defaultroles.html
- AWS EMR Fixed Private IP: https://aws.amazon.com/premiumsupport/knowledge-center/static-private-ip-master-node-emr/
- AWS EMR dfs.replication: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hdfs-config.html