라라벨 프레임워크 - 엘라스틱서치 사용 경험기 : 초기 작업 수행

요즘에는 검색엔진으로 엘라스틱서치를 워낙 많이 사용하다 보니까 여차여차 나도 스프링, 레일즈에서 엘라스틱서치를 구축했던 경험이 있다. 이번에는 라라벨 프레임워크에서 엘라스틱서치를 사용할 기회가 생겨 그 경험을 정리하기 위해서 포스팅한다. 목차는 다음과 같이 구성되어있다.
목차
엘라스틱서치를 라라벨 프레임워크에서 사용하기 전에 엘라스틱서치를 구축하는 방법을 알아보면 보통 아래의 3가지 방법이 있다.
2. AWS Elasticsearch Service를 이용해서 구축하는 방법
3. EC2 인스턴스에 오픈소스 엘라스틱서치를 직접 설치해서 구축하는 방법
엘라스틱서치 도입을 앞둔 개발자는 위의 3가지 방법을 두고 고민하고 있을 것이다. 위의 방법 중 2, 3번으로 구축해본 경험밖에 없지만 3가지 방법을 두고 고민해본 입장에서 장단점을 간단하게 정리해보면 다음과 같다.
1번은 엘라스틱에서 지원을 하므로 관리 및 교육, 컨설팅 측면에서 뛰어난 장점이 있다. 일단 엘라스틱에서 지원을 해주는 거 자체가 엄청나게 큰 장점이 아닐까 생각한다. 그리고 한글 형태소 분석기 은전한닢을 지원한다. 최신 버전의 엘라스틱 스택을 바로 사용할 수 있으며 모니터링 기능도 지원한다. 하지만 최소 스토리지 용량이 정해져 있어 최소 용량을 채울 만큼의 데이터가 없다면 고민이 되는 부분이다. 또한 적은 비용이 아니기 때문에 여러 가지 요소를 잘 생각해서 도입하면 좋을 거 같다. 사용해보지 않았기 때문에 더 많은 장단점이 있을 것으로 생각되며 그 외의 라이센스 별 지원은 링크를 통해서 확인할 수 있다.
2번은 AWS에서 제공하는 Elasticsearch Service이며, 관리형 서비스이다. 같은 VPC에 묶여있는 인스턴스를 통해서만 접근할 수 있게 되어있으며 외부에서는 접근할 수 없다.(퍼블릭 액세스도 있으나 추천하지 않는다.) 키바나 같은 플러그인을 사용하기 위해서는 같은 VPC의 인스턴스 웹 서버 프록시나 AWS 코그니토로 접근해야 한다. 그 외에도 지원하지 않는 플러그인이나 용어 사전을 파일로 관리할 수 없는 점이 조금 불편하게 느껴졌다. AWS Elasticsearch Service에서 지원하는 플러그인 리스트는 여기를 참고하면 된다. 요금은 여기에서. 하지만 별도의 과정 없이 키바나를 사용할 수 있다는 장점이 있으며, 엘라스틱서치 5.1부터는 한글 형태소 분석기 은전한닢을 지원하고 있다. 또한 많은 기능은 아니지만, 웹 콘솔을 통해서 엘라스틱서치를 제어할 수 있으며 모니터링이 가능하다.
2017년 엘라스틱에서 올라온 Elastic Cloud vs AWS Elasticsearch Service를 참고한다면 조금 더 도움이 될 거 같다.
3번은 EC2 인스턴스에 오픈소스 엘라스틱서치를 설치해서 사용하는 방법이다. 엘라스틱 스택 중 엘라스틱서치만 사용하고 관리에도 능숙하게 된다면 3번의 방법도 괜찮은 방법이 될 거 같다. 직접 서버를 구축하는 방법이기 때문에 사용자가 어떻게 사용하느냐에 따라 달라진다. 나중에 x-pack, 엘라스틱 클라우드의 확장을 고려한다면 3번의 방법 전에 1번의 방법도 고려해야 한다.
엘라스틱서치를 도입할 방법의 장단점을 간단하게 비교해봤으며, 여러 가지 요소를 잘 고려해서 도입을 결정했다면 엘라스틱서치를 설치한다. 이 포스팅에서는 엘라스틱서치 설치법은 생략한다. 간단하게 엘라스틱서치를 설치하고 싶은 사람은 아래의 방법으로 엘라스틱서치를 설치해도 좋다.
도커를 설치한 다음 엘라스틱서치와 은전한닢을 올려둔 컨테이너를 사용하는 방법이다. 도커는 링크를 통해서 받을 수 있으며 컨테이너는 여기서 클론할 수 있다. 현재에는 엘라스틱서치 6.1.1과 은전한닢 플러그인만을 지원하고 있으며 서버 개발에 필요한 스택으로 확장할 예정이다.
엘라스틱서치의 설치가 끝났다면 Elasticsearch-head를 설치해보자. Elasticsearch-head는 엘라스틱서치의 클러스터를 확인할 수 있는 플러그인이다. 간단하게 크롬 확장 프로그램으로 설치할 수 있으며 여기를 눌러서 설치하면 된다.
라라벨 프레임워크에서 엘라스틱서치를 사용하기 전 사전 작업은 끝났고 본격적으로 사용하는 법을 알아본다. 아래에서 진행되는 과정은 composer를 통해 프로젝트 생성하고 도커에 엘라스틱서치를 올려서 진행했다.
서비스에 엘라스틱서치를 도입하게 되면 아래와 같은 과정을 거친다.
초기
문서 관리
초기 작업 먼저 알아보자.
인덱스 생성
초기 인덱스 생성을 하기에 앞서 인덱스에서 사용할 analyzer, tokenizer, filter를 정의한다. filter의 synonym(동의어사전), stop words(불용어사전), user words(사용자 정의사전)을 파일로 관리한다면 엘라스틱서치가 설치된 config 경로 아래에 위치되어야한다. 나는 다음과 같이 analyzer, tokenizer, filter를 정의했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82//your_project/config/elasticsearch/analyzer/cherrypick_analyzer.json { "index": { "analysis": { "filter": { "replace_slash_pattern_filter": { "type": "pattern_replace", "pattern": "/.*", "replacement": "" }, "synonym": { "type": "synonym", "synonyms_path": "/usr/share/elasticsearch/config/analysis/synonyms.txt" } }, "analyzer": { "custom_search_analyzer": { "type": "custom", "filter": [ "lowercase", "trim", "replace_slash_pattern_filter", "synonym" ], "tokenizer": "seunjeon_default_tokenizer" }, "ngram_analyzer": { "type": "custom", "tokenizer": "ngram_tokenizer", "filter": [ "lowercase", "trim" ] }, "custom_index_analyzer": { "type": "custom", "filter": [ "lowercase", "trim", "replace_slash_pattern_filter", "synonym" ], "tokenizer": "seunjeon_default_tokenizer" }, "korean": { "type": "custom", "filter": [ "lowercase", "trim", "replace_slash_pattern_filter", "synonym" ], "tokenizer": "seunjeon_default_tokenizer" } }, "tokenizer": { "ngram_tokenizer": { "type": "nGram", "min_gram": "1", "max_gram": "8", "token_chars": [ "letter", "digit", "punctuation", "symbol" ] }, "seunjeon_default_tokenizer": { "type": "seunjeon_tokenizer", "index_eojeol": false, "user_words": [ "낄끼+빠빠,-100", "c\\+\\+", "어그로", "버카충", "abc마트" ] } } } } }
analyzer, tokenizer는 은전한닢, ngram을 사용하고 있으며 문자 필터는 replace slash pattern filter, 토큰 필터에는 synonym(동의어사전)만 따로 추가했다. 이처럼 인덱스에서 사용할 analyzer, tokenizer, filter를 정의했다면 인덱스를 생성한다. config/elasticsearch 경로에서 curl로 cherrypick_analyzer.json을 이용해 board 인덱스를 생성한다.
1 2# Create board index $ curl -XPUT -H 'content-type: application/json' 'http://localhost:9200/board?pretty' -d '@analyzer/cherrypick_analyzer.json'
인덱스를 생성하고 Elasticsearch-head를 통해서 인덱스의 [Info] - [Index Metadata]를 확인해보면 아래와 같이 제대로 생성된 것을 확인할 수 있다.
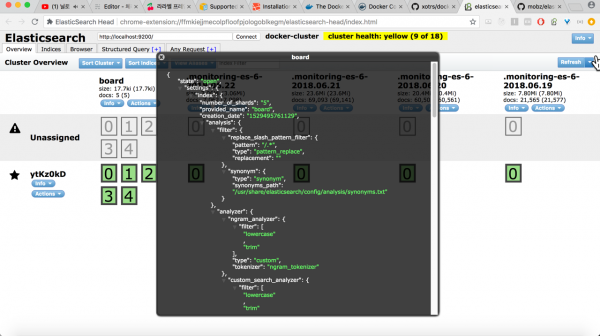
매핑 생성
다음은 인덱스 안에 들어가는 데이터 타입을 정의하는 매핑 생성 작업을 진행한다. 검색을 잘하기 위한 필수 과정이다. 나는 이미 존재하는 데이터를 검색하기 위해서 기존의 RDB의 컬럼에 맞춰서 매핑 생성 과정을 진행했다.
기존 RDB의 board 테이블은 다음과 같다.
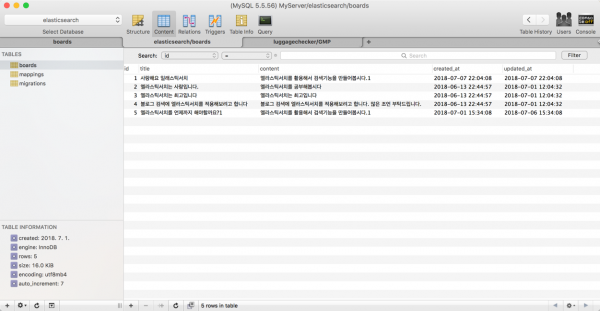
id(INT), title(VARCHAR), content(VARCHAR), created at(DATETIME), updated at(DATETIME)으로 구성된 간단한 테이블이다. 이를 기반으로 필드 타입을 지정하고 아래와 같이 매핑 파일을 생성했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28//your_project/config/elasticsearch/mappings/board_mapping.json { "v1": { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "korean", "search_analyzer": "korean" }, "content": { "type": "text", "analyzer": "korean", "search_analyzer": "korean" }, "created_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "updated_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" } } } }
v1 타입의 properties로 id(long), title(text), content(text), created at(date), updated at(date)으로 필드를 정의했다. 그리고 title, content 필드에 analyzer와 search analyzer를 은전한닢으로 지정했다. 이 외에도 많은 옵션이 있으나 여기서는 analyzer, search analyzer만을 사용한다. analyzer, search analyzer를 지정한 필드의 해당 데이터를 대상으로 분석이 진행되며 그 과정은 아래와 같다.
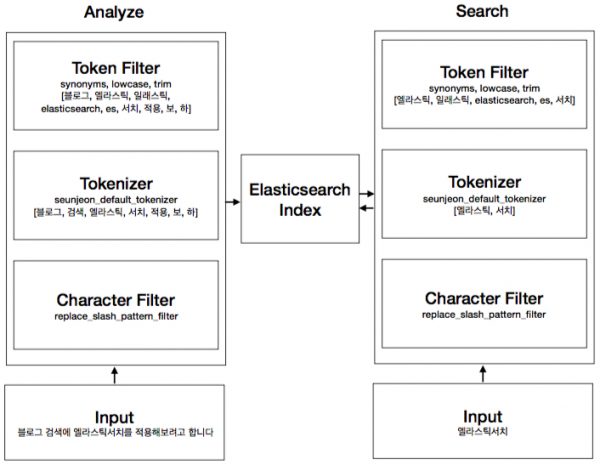
필드의 title에 블로그 검색에 엘라스틱서치를 적용해보려고 합니다 라는 문장이 있다면 지정한 analyzer를 통해서 분석을 진행한다. 먼저 문자 필터를 거치고 은전 한닢으로 한글 형태소 분석을 수행한다. 형태소 분석이 완료되면 [블로그, 검색, 엘라스틱, 서치, 적용, 보, 하] 나누어진다. 그리고 토큰 필터를 통해 [블로그, 검색, 엘라스틱, 일래스틱, elasticsearch, es, 서치, 적용, 보, 하]로 term이 만들어진다. 이 term은 Elasticsearch index에 문서 id와 함께 저장된다.
search의 분석 방식도 비슷하다. 위의 과정을 똑같이 거친 다음 분석한 term이 Elasticsearch index에 존재한다면 score 순으로 문서를 반환한다.
간단하게 분석 과정을 알아봤고 아래의 명령어를 통해 config/elasticsearch 경로에서 curl로 board의 매핑을 생성한다.
1 2# Create board mapping $ curl -XPUT -H 'content-type: application/json' 'http://localhost:9200/board/_mapping/v1?pretty' -d '@mappings/board_mapping.json'
이렇게 매핑 생성 과정을 거치고 나면 Elasticsearch-head의 [Index Metadata]를 통해서 매핑이 제대로 생성된 것을 확인할 수 있다.
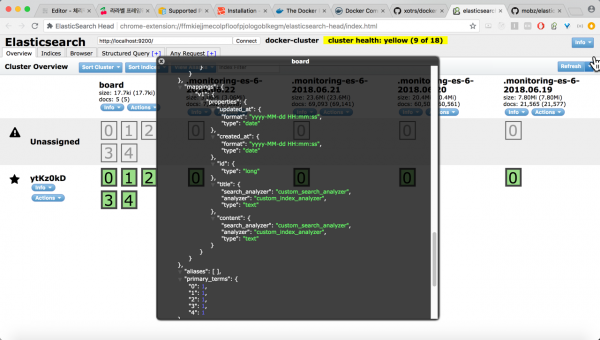
문서 색인 작업
매핑 생성 과정을 마치고 나면 기존의 데이터를 엘라스틱서치 문서로 색인하는 작업이 남았다. 위에서 보여준 board 테이블의 데이터를 문서로 색인할 것이다. 문서 색인은 라라벨 프레임워크에서 Elasticsearch client 라이브러리를 활용해 진행했다.
엘라스틱에서 라라벨 프레임워크에서 사용할 수 있는 엘라스틱서치 관련 라이브러리를 정리해둔 링크를 참고하면 3개의 라이브러리를 확인할 수 있다. 3개의 라이브러리 중 스타가 제일 많은 Plastic 라이브러리를 사용해서 구축을 시도한 적이 있었는데 몇 가지 장점이 있었지만 엘라스틱서치 5까지만 지원을 하므로 field type에 text, keyword가 존재하지 않아 매핑하는데 문제가 있었다. 그리고 아직 지원하지 않는 쿼리도 존재하기 때문에 결국에는 PHP 공식 엘라스틱서치 클라이언트 라이브러리인 Elasticsearch-PHP를 사용해야되는 상황도 발생했다. 라라벨 프레임워크에 엘라스틱서치를 도입하려는 개발자는 이를 참고해서 라이브러리 선택을 하면 좋을 거 같다.
나는 위에서 말한 점 때문에 Plastic 라이브러리를 걷어내고 Elasticsearch-PHP만 이용해서 개발을 진행했다. 엘라스틱에서 제공하는 Elasticsearch-PHP 가이드도 잘 정리 되어있다. 우선 Elasticsearch-PHP를 설치한다.
Elasticsearh-PHP 설치
composer.json 파일에 Elasticsearch-PHP를 작성하고 composer install을 진행한다.
1 2 3 4 5 6//composer.json { "require": { "elasticsearch/elasticsearch": "~6.0" } }
Client 생성
설치가 완료 되었다면 엘라스틱서치와 통신할 수 있는 클라이언트 생성 코드를 작성한다. env의 설정에 따라 통신할 수 있는 엘라스틱서치의 주소를 세팅했다. 현재에는 로컬에서만 동작하도록 작성했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16//your_project/config/elasticsearch/ElasticsearchConfig.php <?php use Elasticsearch\ClientBuilder; class ElasticsearchConfig { public function getHost() { if (env('APP_ENV') == 'local') return 'http://localhost:9200'; } public function getClient() { $hosts = [$this->getHost() ]; $client = ClientBuilder::create()->setHosts($hosts)->build(); return $client; } }
이로써 라라벨 프레임워크와 엘라스틱서치가 통신할 수 있는 환경은 갖추어졌다. 다시 문서 색인 작업으로 돌아가서 Elasticsearch-PHP의 가이드를 살펴본다. 가이드를 보면 Bulk indexing을 이용해서 대량의 데이터를 한꺼번에 색인하는 방법을 제공하고 있다. 나도 Bulk api를 활용해서 문서를 색인했다.
초기에 한 번만 수행하면 되는 동작이기 때문에 Artisan console의 Command를 활용해서 진행한다. Command를 만드는 방법은 다음과 같다.
1$ php artisan make:command IndexElasticsearch
명령어를 수행하고 나면 app\console\Commands 아래에 IndexElasticsearch.php 파일이 생성된다. IndexElasticsearch.php 파일에 Bulk api 코드를 작성한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84<?php namespace App\Console\Commands; use App\Repositories\BoardRepository; use ElasticsearchConfig; use Illuminate\Console\Command; class IndexElasticsearch extends Command { /** * The name and signature of the console command. * * @var string */ protected $signature = 'cherrypick:IndexElasticsearch'; /** * The console command description. * * @var string */ protected $description = '엘라스틱서치 초기 색인 작업'; private $elasticsearchConfig; private $boardRepository; /** * Create a new command instance. * * @param BoardRepository $boardRepository * @param ElasticsearchConfig $elasticsearchConfig */ public function __construct(BoardRepository $boardRepository, ElasticsearchConfig $elasticsearchConfig) { $this->boardRepository = $boardRepository; $this->elasticsearchConfig = $elasticsearchConfig; parent::__construct(); } /** * Execute the console command. * * @return mixed */ public function handle() { $this->indexElasticsearch(); return; } public function indexElasticsearch() { $start = microtime(true); $this ->output ->writeln("start : " . $start); $boards = $this ->boardRepository ->all(); $params = ['body' => []]; foreach ($boards as $index => $board) { $params['body'][] = ['index' => ['_index' => 'board', '_type' => 'v1', '_id' => $board->id]]; array_push($params['body'], $board); if ($index % 10 == 0) { $responses = $this ->elasticsearchConfig ->getClient() ->bulk($params); $params = ['body' => []]; unset($responses); } } if (!empty($params['body'])) { $responses = $this ->elasticsearchConfig ->getClient() ->bulk($params); } $end = microtime(true); $time = $end - $start; $this ->output ->writeln("end : " . $end); $this ->output ->writeln("running time : " . $time); } }
BoardRepository, ElasticsearchConfig를 주입하고 board 테이블 전체의 데이터를 가져온 다음 10개씩 bulk api를 통해서 엘라스틱서치 문서를 색인하는 코드이다. 코드를 작성하고 아래와 같이 App\Console\Kernel.php 파일에 Command를 추가한다. 완성된 코드는 여기에서 확인할 수 있다.
1 2 3 4 5 6 7 8 9 10 11//your_project/app/Console/Kernel.php <?php . . . protected $commands = [ 'App\Console\Commands\IndexElasticsearch' ]; . . .
Command를 추가하면 아래의 명령어를 통해서 Bulk indexing을 수행할 수 있다.
1$ php artisan cherrypick:IndexElasticsearch
명령어를 실행하면 board 테이블의 데이터가 엘라스틱서치에 문서로 색인 작업이 진행된다. 진행이 끝나고 나면 Elasticsearch-head를 통해서 board 인덱스의 색인 된 문서를 다음과 같이 확인할 수 있다.
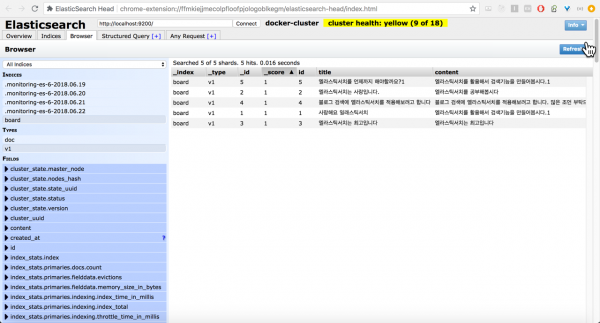
이렇게 문서 색인 작업이 끝나면 엘라스틱서치를 이용한 검색 기능을 위한 초기 작업은 끝이 난다.
2편에서 다루는 내용
- 엘라스틱서치 문서 색인
- 엘라스틱서치 문서 수정
- 엘라스틱서치 문서 삭제
완성된 코드는 아래에서 확인할 수 있다.