Hadoop-3.0과 Erasure Coding 편집증


안녕하세요. 오늘은 하둡3.0과 Erasure Coding에 대하여 얘기를 하고자 합니다.
저희 회사에서도 시스템 로그 및 유저 액티비티 로그들을 적재 할 공용 저장소 시스템을 구축 할 필요가 있게 되어서, 하둡을 사용하게 되었습니다. 아직 하둡 알파버전이지만, 3.0 버전에 대한 내용을 접한 곳은 홍태희님의 "업그레이드를 부르는 Hadoop 3.0 신규 기능 살펴보기" 이라는 글을 통해서 입니다.
하둡 3.0에서의 신규로 추가 된 주요 기능은 제목과 같이 Erasure Coding(이하 EC) 입니다. 하둡은 기본적으로 데이터 유실에 대비하여(Fault Tolerance) 원본 데이터외 복재본을 2개 더 갖도록 저장합니다. 그런데, 그렇게 원본을 그대로 복재하지 않고 오류 정정 코드만 저장한 후, 저장 된 데이터가 유실 됐을 때 복원이 가능하도록 할수 도 있습니다.
Erasure Coding은 에러 정정 코드만 저장한 후, 복원 하는 기법입니다.
저희가 이 기능을 처음부터 적용한 이유는,
- 기존 방식 대비 저장소 Capacity 2배 증가
스토리지를 사용하게되면 용량이 줄어들기보다는 계속 증가할 뿐인데, 이때 이 기능으로 기존버전보다 저장소를 2배(RS-Default-6-3-64K) 더 효율적으로 사용할 수 있게 되었습니다. (기존방식 HDFS Replication factor 3정책일 경우)
- 인프라 증설 비용 및 업그레이드/마이그레이션 비용 절감 (No 삽질)
처음부터 저장할 때 Erasure Coding 알고리즘이 적용 된 상태로 적재하면 향후에 적재공간 부족의 압박으로 인한 Erasure Coding 방식으로 변환 저장하는 마이그레이션을 피할 수 있다고 판단하였습니다.
기존 방식대로 적재를 시작하게 되면, 나중에 업그레이드를 하게 될 때, Erasure Coding을 적용하기가 불가능한 상황이 올 수도 있고, 혹여나 적용을 하더라도 엄청난 고통의 나날이 예상되었기 때문입니다.
이제, Hadoop 3.0 에서 제공하는 Erasure Coding 알고지즘 중 Reed Solomon Code 방식을 알아보고자 합니다. (XOR 방식도 있습니다.) EC Reed Solomon은 이미 생활의 많은 부분에서 사용중인 에러보정 방식인데요, CD와 DVD, 위성통신, Barcode, QRcode, Raid 저장소 등에서 사용합니다.
|
Policy |
Description |
|---|---|
| RS-DEFAULT-3-2-64k | Data Block 3개, Parity Block 2개, 블럭사이즈 64KB (최소 구성노드 5개) |
| RS-DEFAULT-6-3-64k | Data Block 6개, Parity Block 3개, 블럭사이즈 64KB (최소 구성노드 9개) |
| RS-DEFAULT-10-4-64K | Data Block 10개, Parity Block 4개, 블럭사이즈 64KB (최소 구성노드 14개) |
| RS-LEGACY-6-3-64K | description mia ! (최소 구성노드 9개) |
| XOR-2-1-64k | XOR 오류 정정 방식. 블럭사이즈 64KB (최소 구성노드 3개) |
실제 데이터 저장 효율과 손실 허용 블록 갯수는 다음과 같습니다.
|
Storing Method |
Storage Real Capacity |
Available Size / Total Size |
Loss Allowed Blocks |
|---|---|---|---|
| Replication-Factor 3 | 1/3 | 3TB / 9TB | 2 |
| Erasure Coding-RS-6-3 | 2/3 | 6TB / 9TB | 3 |
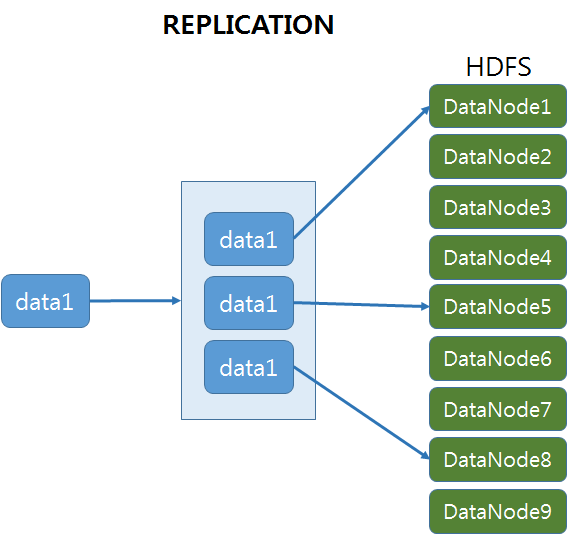
다음은 데이터가 저장되는 방식입니다.
아래 도식을 간단하게 설명 드리면,
- Replication 방식 : data1을 HDFS 데이터노드 9개 중 임의의 3개 노드에 저장하게 됩니다. Google File System(GFS) 으로 부터 상속 받은 정책입니다.
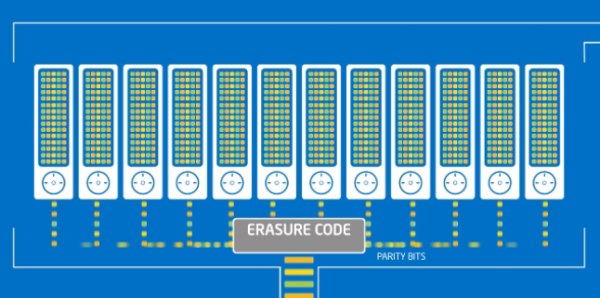
- Erasure Coding - RS-DEFAULT-6-3-64k 방식 : data1을 Erasure Client 가 6개의 데이터 블럭과 3개의 패리티 블럭으로 쪼개어서 각각 임의의 데이터 노드에 저장합니다.
블럭 하나당 64KB 크기의 2000 개의 조각(stripe)으로 쪼개어져 최대 128MB를 구성합니다.1개의 블럭 그룹은 6개의 블럭으로 구성되며, 128MB * 6 = 768MB 크기의 데이터를 저장할 수 있고,
이 보다 더 큰 경우는 연속하여 두번째 블럭 그룹을 생성하게 됩니다. 블럭그룹의 블럭들은 각 노드에 골고루 분산되어 지며, 이에 따라 I/O 처리량이 높아집니다.저장할 데이터가 작아도 "블럭그룹"은 6개의 "데이터 블럭"과 3개의 "패리티 블럭"으로 구성하되 각 조각은 0로 채워지며, 그에 맞게 "패리티 블럭"이 생성됩니다.

Performance Penalty → Intel Storage Acceleration 으로 극복!
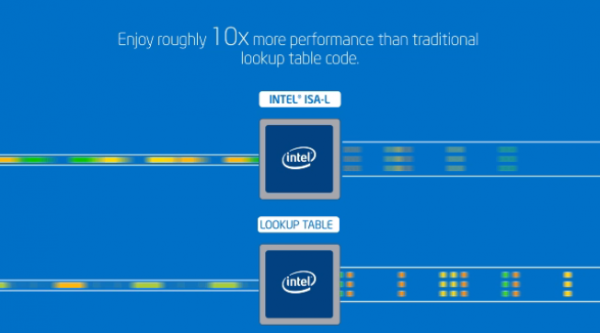
저장공간을 적게 차지한다는 것은 적은 쓰기를 수행한다는 것이고, 그렇다면 쓰기 작업이 빨리 끝난다는 것을 알 수 있습니다. 그러나, EC 로 분할하고 다시 합병하는 가운데, CPU의 연산이 필요하게 됩니다. 하지만, 이것은 Intel에서 ISA-L 이라는 가속 명령어를 제공해 주어 굉장히 빠른 속도로 Encoding/Decoding이 가능하게 도와줍니다.
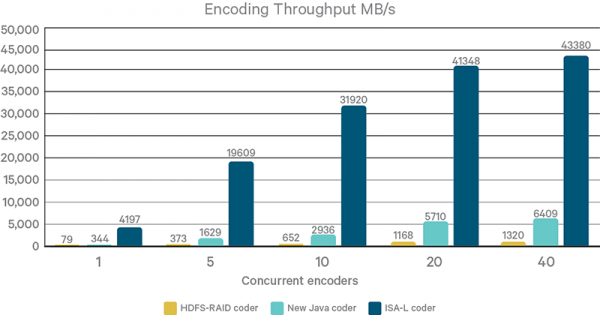
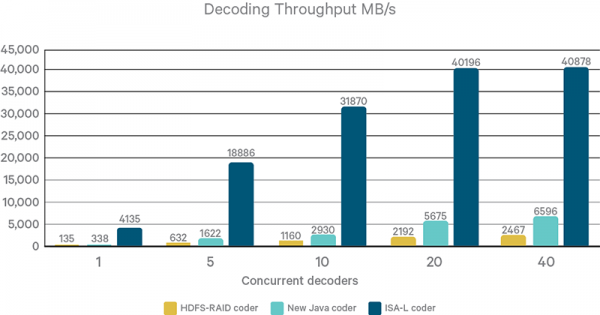
ISA-L 적용으로 10배 빠른 속도!
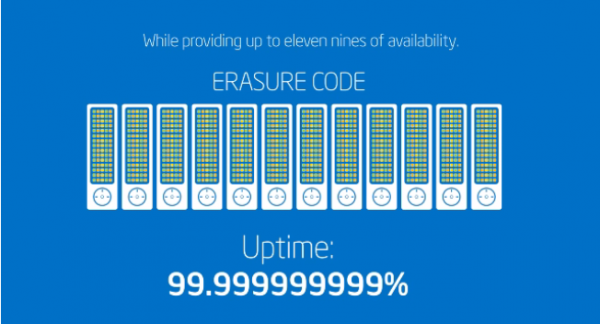
가용성 ㅎㄷㄷ!
"또 다른 단점은 없니?"
물론, 데이터를 동시에 여러군데 복제해두지 않기에 Locality 가 낮아지는 단점이 있습니다. M/R를 수행할 때 처럼 HDD에 중간 결과물들을 계속 쓰고/읽는 연산을 한다면, Locality 가 어느정도 중요한 포인트 일 수 있으나,
- 10Gbps 이상의 네트워크 환경이 좋은 곳에서는 큰 문제가 되지 않으며,
- 더불어 Memory기반에서 처리하는 Spark 를 사용하는 환경에서는 가중치는 낮다고 판단하며 비로서 명분을 찾아봅니다.

마무리
다음 편에서는 ISA-L 설치와 Hadoop 3.0 Erasure Code 적용 방법을 소개하겠습니다.
참조 링크
http://hadoop.apache.org/docs/r3.0.0-alpha3/
http://hadoop.apache.org/docs/r3.0.0-alpha3/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
https://github.com/01org/isa-l
https://www.intel.com/content/www/us/en/storage/erasure-code-isa-l-solution-video.html
http://blog.cloudera.com/blog/2016/02/progress-report-bringing-erasure-coding-to-apache-hadoop/
https://www.usenix.org/legacy/event/fast09/tech/full_papers/plank/plank_html/