Kafka Python client 성능 테스트

Kafka는 최근 비동기 시스템 구축이나 대용량 데이터 수집을 위해 반드시 필요한 시스템이 되었다. Python은 빅데이터 처리를 위해 많이 사용되는 언어이기 때문에 Kafka의 데이터를 처리하기 위해 Kafka Python 클라이언트도 많이 사용한다. 다음 기사는 여러 종류의 Kafka Python client 성능 테스트에 대한 결과이다. Python 사용자라면 결과에 관심을 가져볼만 하다.
http://activisiongamescience.github.io/2016/06/15/Kafka-Client-Benchmarking/
요약하면 다음과 같다.
- 테스트 환경은 맥북 i7 프로세스, 로컬 환경에 1 broker, 100byte 메시지 백만개 producing
- 결론은 kafka native library를 사용하는 경우가 가장 빠른데 pypy 환경에서는 실행되지 않고 C extention을 설치하는 것이 고통스럽다고...
- 이번 테스트에서 python의 thread 처리에 대해서는 메인 주제가 아니기 때문에 이 부분을 다르게 구성할 경우 테스트 결과는 달라질수도 있지 않을까...
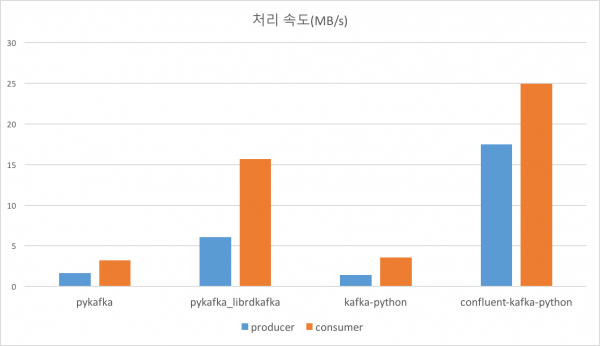
- pykafka
- produce
- 57.32초
- 1.66 MB/s
- 성능 테스트 시 produce() 메소드는 async 로 동작하기 때문에 반드시 producer.stop() 메소드가 완료되는 시점을 테스트 완료 시점으로 계산해야 됨
- consume
- 29.43초
- 3.24 MB/s
- produce
- pykafka + native kafka library(librdkafka)
- produce
- 15.72초
- 6.06 MB/s
- consume
- 6.09초
- 15.67 MB/s
- produce
- kafka-python
- Java client API와 동일한 인터페이스를 제공
- produce
- 67.85초
- 1.41 MB/s
- consume
- 26.55 초
- 3.59 MB/s
- confluent-kafka-python
- librdkafka 를 이용
- produce
- 5.45초
- 17.50 MB/s
- consume
- 3.83초
- 24.93 MB/s
- 처리 용량(MB/s, 수치가 높을 수록 성능이 좋음)
Popit은 페이스북 댓글만 사용하고 있습니다. 페이스북 로그인 후 글을 보시면 댓글이 나타납니다.