React, Go로 만든 WordPress 읽기 서비스 구축 사례: 2편 Go API 서버

이번 글은 Popit 서비스 개편을 어떻게 했는지에 대한 시리즈 글로 두번째 글입니다.
Popit 서비스 개편 작업을 하면서 개발한 내용 중 WordPress 데이터를 제공해주는 API 서버 개발 관련 글입니다. Popit API 서버는 Go 언어로 개발되어 있습니다. 이번 글에서는 Go와 Go의 웹 프레임워크 중의 하나인 echo, 그리고 ORM 라이브러리 xorm을 어떻게 사용했는지에 대해 살펴보겠습니다.
이글에서 설명하는 모든 코드는 다음 gitlab 레포지토리에 있으며 실제 Popit 서비스에 운영되고 있는 코드입니다.
https://github.com/PopitKr/popit_api- https://gitlab.com/popitkr/popit_api
제공하는 API
소스 코드를 살펴보면 알겠지만 WordPress가 저장하는 데이터에 대해 다음 API를 제공하고 있습니다.
- /api/Search: 사용자가 입력한 키워드에 매칭되는 글 목록을 제공한다.
- /api/RecentPosts: 최근 Post 목록을 제공한다. 실제로는 최근 글이 아닌 모든 글에 대해 최신 순으로 paging 처리된 결과를 제공합니다.
- /api/TagPosts: Popit 메인 페이지에 있는 Tag 글을 위한 API로 Tag 중 랜덤하게 몇개를 선택하고 그 Tag의 글 목록을 제공합니다.
- /api/RandomAuthorPosts: Popit 메인 페이지에 있는 저자글 목옥을 위한 API로 랜덤하게 저자를 선택하고, 선택된 저자 중에서도 랜덤하게 글을 선택하여 제공합니다.
- /api/PostsByTagId: 특정 TagID의 글 목록을 제공합니다.
- /api/PostsByTag: 특정 Tag의 글 목록을 제공합니다.
- /api/PostsByCategory: 특정 Category의 글 목록을 제공합니다.
- /api/PostsByAuthor: 특정 저자의 글 목록을 제공합니다.
- /api/PostsByAuthorId: 특정 저자 ID의 글 목록을 제공합니다.
- /api/PostByPermalink: Permalink의 에 해당하는 글에 대한 상세 정보를 제공합니다(상세조회 페이지용도)
- /api/PostById: 특정 ID에 대한 글의 상세 정보를 제공합니다.
대부분의 API는 글을 특정 조건으로 검색하고 글의 목록을 반환해주는 API 입니다. 특이한 API는 첫페이지에 나타나는 랜덤하게 저자나 Tag를 선택해서 해당 글의 목록을 제공하는 API인데 이것은 지난 글도 첫페이지에 노출 시켜 더 많은 글을 독자에게 노출시키려고 만든 장치입니다.
왜 Go 언어를 선택했나?
필자는 개발 시에 자바를 주 언어로 사용하고 있습니다. 거의 자바 초창기부터 사용해왔으니 자바가 가장 사용하기 편한 언어중의 하나 입니다. 하지만 스프링이 많이 사용하는 시기쯤에 개인적으로 조금 다른 길을 걷게 되었는데 그 시기에 Hadoop 및 그와 관련된 오픈소스에 집중하게 되었습니다. 그 이후로 스프링은 거의 사용하지 않게 되다 보니 자연스럽게 자바 기반으로 웹 개발하는데에는 약간은 거부감이 있었습니다. 그리고 이것은 필자의 성향이기는 한데 스프링을 별로 좋아 하지 않습니다. 물론 좋아하지 않는다고 해서 사용하지 않는다는 것은 아닙니다. 지금은 중지한 기능이지만 popit 서비스의 news 기능은 스프링 부트로 만들어져 있고 이와 관련된 글[1]도 있습니다. 이런 중에 실제로 서비스에서의 경험은 네이버 메일에서는 C + php 조합을, 잡플래닛에서는 Rails를, 그리고 현재 중국에서는 Go 언어를 사용하고 있습니다. 자연스럽게 자바(즉, 스프링) 기반으로 만들기 보다는 Go 언어를 선택하게 되었습니다.
여기까지는 개인적인 이유이고 시스템 측면에서 Go 언어를 선택한 이유는 대략 다음과 같다.
- 작은 규모의 프로젝트에서는 쉽게 시작할 수 있고, 환경 설정도 거의 없다.
- 서버의 메모리를 많이 요구하지 않는다.
- 현재 운영중인 popit 서버의 메모리 사용 상황이다. 이 시점에 GA에서 동시 사용자는 40 정도 유지를 하고 있었다.
1 2 3 4 5 6 7RSS SZ VSZ %MEM %CPU TIME CMD 316004 3062836 3105300 16.4 0.1 05:19:48 /usr/sbin/mysqld 170900 4539616 4696688 8.8 0.1 00:18:59 java -classpath ./popit_searcher Launcher spring-boot:run 140492 1286868 1332820 7.3 0.1 00:00:56 node 53864 50432 361076 2.8 0.1 00:00:03 php-fpm: pool www 24472 23360 320640 1.2 0.0 00:00:00 php-fpm: pool www 14484 842360 856576 0.7 0.0 00:00:42 ./popit_api - mysql이 가장 많이 사용하고 있고, 그 다음이 Spring boot + Lucene로 만든 검색 서버가 차지하고 있다. 검색 서버라고 하지만 실제로는 문서 400개 정도만 유지하면 되기 때문에 실제 메모리 사용은 많지 않은데에도 약 9% 정도를 차지하고 있다. 물론 메모리 설정 옵션을 이용하여 줄일 수도 있겠지만 그래도 Go 언어로 만든 프로그램 보다는 많이 사용할 것이다.
- popit_api 프로세스가 API 서버인데 메모리를 거의 사용하지 않는 것을 알 수 있다.
- Popit 서버는 아주 저렴한 서버이기 때문에 2GB의 메모리만 가지고 있다. 이 서버에 mysql, nginx, php, node 등 많은 서버를 운영해야 하는데 메모리를 많이 사용하면 서버 용량 증설을 해야 하기 때문에 기본 메모리 사용이 가능 작은 Go 언어가 좋은 선택이라고 할 수 있다.
- 현재 운영중인 popit 서버의 메모리 사용 상황이다. 이 시점에 GA에서 동시 사용자는 40 정도 유지를 하고 있었다.
- ORM 사용 등이 심플하다.
- Spring에서 제공하는 Data 처리 기능은 막강하다. 반면 이 막강한 기능을 처리하기 위해서는 만들어야 할 클래스도 제법 있고 코드 구성도 복잡하다.
- 하지만 지난 글에서도 봤듯이 사용하는 테이블은 기껏해야 10개 미만이고, 트렌젝션 자체도 복잡하지 않다.
- 유지보수하기 좋다.
- 심플하다는 것은 수정 사항이 발생했을 때 자주 사용하지 않는 스프링에 대한 기억이나 문서 속에서 방황할 필요가 없다는 것을 말한다. 심플한 시스템 구성에 심플한 문법이다 보니 가끔 사용해도 쉽게 수정이 가능하다.
이렇게 좋은 점도 있지만 단점도 많은 언어입니다. 가장 대표적인 것이 부족한 관련 솔루션들입니다. 많이 개발되고 있지만 아직 자바에 비하면 많이 떨어집니다. Go 언어로 만들수 있는 검색 라이브러리도 있기는 하지만 Lucene 만큼은 좋다고 할 수 없기 때문에 검색을 위해 어쩔수 없이 다시 자바로 만들었습니다. 이런 저런 단점을 따지기 보다 위의 장점만으로도 사용 이유가 충분했기 때문에 망설임없이 Go 언어로 선택하였습니다.
프레임워크의 선택
언어는 선택했으니 이제 관련 도구를 선택해야 합니다. API 서버 구성 시 핵심 도구는 HTTP 요청에 대한 처리를 지원하는 웹 프레임워크와 데이터베이스 질의 처리를 위한 도구입니다. 자바에서는 스프링과 하이버네이트로 많이 표준화 되었지만 Go 언어에서는 다양한 프레임워크가 나오고 있습니다. 웹 프레임워크만 해도 echo, beego, gin 등 다양하게 많습니다. Go 언어의 웹 프레임워크 관련 글은 다음 글을 참고해보세요.
- Top 6 web frameworks for Go as of 2017
- 이 글에서도 echo 와 같은 프레임워크의 경우 진정한 웹 프레임워크라고 할 수 없다고 하지만 Go 커뮤니티에서는 웹 프레임워크라고 받아 들이고 있다고 합니다. Go는 많은 경우 간단하면서 심플한 기능을 추구하는데 이런 측면이 웹 프레임워크에도 그대로 나온게 아닐까 생각합니다.
필자의 경우 beego도 사용해 보았는데 "Beego (Go application framework) 초간단 사용 소감" 글에서도 밝혔듯이 기능은 많지만 아직까지 그 기능이 Rails 등과 같은 수준으로 올라오지 못한것 같았습니다. 어차피 기능이 부족하다면 복잡한 것을 사용하기 보다는 심플한 것을 사용하자는 생각으로 echo 프레임워크를 선택하였습니다. 다른 프레임워크는 고려하지 않았는데 이유는 이미 echo는 중국 업무에 많이 사용하고 있어서 입니다[2].
데이터베이스 처리 관련 프레임워크 선택을 위해서는 요구사항에 따라 아주 다양한 선택이 있을 수 있습니다. Go 언어에서는 gorm, xorm 등 다양한 데이터베이스 관련 프레임워크가 있는데 필자가 확인해보면 다양한 연관관계까지 처리해주는 프레임워크는 gorm 입니다. 그외에는 대부분은 자바의 MyBatis와 같은 테이블 또는 질의에 대해 객체를 매핑해주는 수준입니다. xorm의 경우 연관 관계 로딩 처리를 위한 이슈가 2013년에 생성되었지만 아직도 오픈 상태입니다.
- https://github.com/go-xorm/xorm/issues/41
Go 언어에서 데이터베이스 처리 프레임워크 선택을 고민하는 독자라면 장재휴님의 블로그 글을 추천해드립니다.
필자의 경우 딱히 연관관계 자동 로딩 등의 기능은 필요 없고(프로그램으로 직접 했습니다.) 동료가 추천해준 xorm을 선택하였습니다.
모두 합치기
main 함수
Go 언어는 C 언어와 스타일이 비슷합니다. 처음 시작도 main() 함수로 시작하고 빌드 과정을 거쳐 바이너리 파일을 생성합니다. Go 언어에도 패키지 개념이 있어 여러 패키지로 나누기도 하는데 Popit API 서버는 심플한 구성이어서 별도 패키지로 구분하지 않았습니다. 참고로 업무에서 사용하는 서비스의 경우 controller, model 정도로 패키지를 나누어서 사용합니다.
패키지를 나누지 않더라도 별도의 파일로 controller를 정의할 수 있지만 여기서는 main.go 파일이 전체 프로그램의 entry 역할과 controller의 역할을 같이 수행하고 있습니다. 다음은 main.go의 주요 로직입니다.
main.go (main 함수)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20func main() { // main이 종료되면 DB 접속을 닫는 로직 defer xormDb.Close() // echo 프레임워크 객체 생성 e := echo.New() // request path에서 마지막에 '/' 있는 경우 제거 e.Pre(middleware.RemoveTrailingSlash()) // 처리 도중 문제 발생 시 서버를 죽이지 않고 계속 수행하도록 설정 e.Use(middleware.Recover()) // 멀티 도메인 대응이 가능하도록 CORS 설정 e.Use(middleware.CORS()) // 하나의 요청에 대해 데이터베이스 연결을 가져와 context에 추가 e.Use(setDbConnContext(xormDb)) e.GET("/api/Search", SearchPosts) e.GET("/api/RecentPosts", GetRecentPosts) //추가 URL, Action Mapping e.GET("/api/GetGoogleAd", GetGoogleAd) // 8000 포트로 http listener 시작 log.Fatal(e.Start(":8000")) }
main() 함수의 구성을 보면 처음에 defer 가 나오는데 이것은 함수가 종료될 때 호출해달라는 Go의 키워드로 데이터베이스 연결 객체인(xormDb)를 닫는 로직을 실행하도록 하였습니다. xormDb 연결을 가져오는 부분은 뒤에서 설명하겠습니다.
그 다음은 웹 프레임워크인 echo 객체를 생성하고 필요한 미들웨어를 설정합니다. 스프링의 경우 Request가 실제 Action 까지 전달되기 전에 공통적으로 처리해야 하는 기능이 있을때 Filter를 만들어서 Chain을 구성해주면 Filter에 정의된 로직을 처리한 다음 Action으로 오게 됩니다. 이과 동일하게 echo 에서는 middleware 를 제공합니다. 위 코드에서는 기본적으로 제공하는 미들웨어인 Recover, CORS를 사용하고 있고, 사용자가 정의한 setDbConnContext를 사용하도록 설정하였습니다.
DB 연결
데이터베이스 연결은 xorm의 객체를 생성하는 과정인데 이 과정은 main에서 하지 않고 init() 함수에서 처리하고 있습니다. Go 에서 init() 함수는 main() 함수 처럼 특별한 용도로 사용됩니다. init 함수는 main 함수가 호출되기 전에 자동으로 실행되는 함수입니다. 내부에는 각종 초기화 기능들을 넣습니다. 앞에서 설명한 xorm URL 매핑 등도 init() 내에서 할 수도 있습니다. init() 함수는 패키지가 로딩될 때 실행되는데 import 문에서 지정하고 있는 패키지의 init() 함수를 찾아 실행합니다. 그리고 마지막으로 디폴트 패키지의 init() 함수를 실행합니다.
실제 코드는 다음과 같이 되어 있습니다.
main.go (init 함수)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22import ( "github.com/go-xorm/xorm" _ "github.com/go-sql-driver/mysql" ) var ( xormDb *xorm.Engine ) func init() { dbConn := os.Getenv("DB_CONN") if len(dbConn) == 0 { dbConn = "root:@tcp(127.0.0.1:3306)/wordpress?charset=utf8&parseTime=True" } db, err := xorm.NewEngine("mysql", dbConn) if err != nil { panic(fmt.Errorf("Database open error: %s \n", err)) } db.ShowSQL(false) db.SetMaxOpenConns(100) db.SetMaxIdleConns(20) db.SetConnMaxLifetime(60 * time.Second) xormDb = db }
DB 연결 정보를 저장하고 있는 xormDb 변수는 전역으로 선언하였습니다. 그리고 init에서 시스템 환경 변수인 DB_CONN 값을 읽어와 xorm의 Engine 객체를 생성하고, Connection pool 옵션 등을 지정합니다. Go 언어에서 제공하는 Connection Pool 은 정말 마음에 들지 않는데 몇가지 이슈들이 있습니다. 예를 들면 mysql 의 경우 서버에서 일정 시간동안 사용하지 않은 연결을 자동으로 닫는데 이에 대한 처리 등이 깔끔하지 않습니다.
필자가 본 여러 프로젝트에서는 소스 코드에 DB 연결 정보, 심지어는 패스워드까지 저장되어 있는 경우를 많이 봤는데 시스템 환경 변수를 이용하거나, 서버 실행 시 인자로 받도록 해야 합니다.
그리고 놓치기 쉬운 것이 있는데 import 문에서 사용하는 데이터베이스의 Go 언어 드라이버를 import 해야 합니다. import 할때에도 위의 예제 코드와 같이 "_"를 추가해야 하는데 이것은 Go 언어의 경우 import나 변수 선언을 하고 사용하지 않으면 컴파일 에러가 발생합니다. 데이터베이스 드라이버의 경우 프로그램에서 직접 concrete하게 호출하지 않고 실행 시에 결정되게 프로그램 됩니다. 따라서 프로그램 내에서는 명시적으로 mysql 패키지를 사용하지 않습니다. "_"를 주지 않으면 컴파일 에러가 발생하게 됩니다.
_ "github.com/go-sql-driver/mysql"
사용자 정의 미들웨어 사용: 하나의 Request에 하나의 DB Connection 할당
Popit API 서버의 경우 읽기 전용이기 때문에 트렌젝션 처리는 없습니다. 하지만 일반적인 상황을 고려해보면[3] 트렌젝션을 고려해야 합니다. 스프링을 사용하면 이런 부분에 대해서는 별 고민없이 해결되지만 Go의 경우 직접 핸들링 해야 하는 경우가 많습니다. 대부분의 ORM 엔진에서는 트렌젝션 제어 기능은 들어가 있지만 트렌젝션 시작, 종료, 에러 등에 대한 함수만 제공하는 수준입니다.
웹 애플리케이션의 경우 대부분은 하나의 Action(사용자 요청)에 대해 하나의 트렌젝션으로 관리되는 것이 일반적입니다[4]. 처음부터 복잡한 서비스가 아니었기 때문에 이 전제로 트렌젝션 구성을 위해 Middleware에서 처리하도록 하였습니다.
데이터베이스의 트렌젝션 처리를 위해서는 트렌젝션에 참여하는 모든 SQL은 물리적으로 동일한 DB 연결을 사용해야 합니다. SQL 실행 시 마다 매번 Connection 을 연결하거나 Connection Pool에서 가져오는 방식으로 사용하면 트렌젝션을 처리할 수 없습니다. 이를 위해서 하나의 Action이 처리되는 동안에는 하나의 DB Connection을 사용하도록 하는 것이 중요합니다. 이런 내용을 매번 로직에 넣기 보다 미들웨어에서 사용하도록 구현하였습니다.
main.go (setDBConnContext 함수[5])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25func setDbConnContext(xormDb *xorm.Engine) echo.MiddlewareFunc { return func(next echo.HandlerFunc) echo.HandlerFunc { return func(ctx echo.Context) error { session := xormDb.NewSession() defer session.Close() req := ctx.Request() ctx.SetRequest(req.WithContext(context.WithValue(req.Context(), "DB", session))) if err := session.Begin(); err != nil { log.Println(err) } if err := next(ctx); err != nil { session.Rollback() return err } if ctx.Response().Status >= 500 { session.Rollback() return nil } if err := session.Commit(); err != nil { return echo.NewHTTPError(http.StatusInternalServerError, err.Error()) } return nil } } }
사용하는 DB Connection 에서 하나의 session(실제 DB와의 연결 하나)을 가져와서 Context에 설정합니다. Context에 설정된 이 연결을 이용하여 각 Action 에서는 DB 처리를 하게 구성하면 하나의 Action에 하나의 DB 연결을 사용할 수 있게 됩니다. 실제 사용하는 코드는 다음과 같습니다.
main.go
1 2 3 4 5 6 7 8 9 10 11// context에서 DB 연결 객체를 가져오는 공통 함수 func GetDBConn(ctx context.Context) *xorm.Session { v := ctx.Value("DB") if v == nil { panic("DB is not exist") } if db, ok := v.(*xorm.Session); ok { return db } panic("DB is not exist") }
post.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17func (Post)GetPostById(ctx context.Context, postId int64) (*Post, error) { post := &Post{} has, err := GetDBConn(ctx). Select("ID, post_author, post_content, post_title"). Where("post_status = 'draft'"). And("post_type = 'post'"). And("ID = ?", postId). OrderBy("post_date desc"). Get(post) if !has { return nil, nil } if err != nil { return nil, err } return post, nil }
Action 구현
main() 함수에서 URL과 Action의 매핑은 다음과 같이 했습니다.
e.GET("/api/RecentPosts", GetRecentPosts)
이때 두번째 파라미터인 "GetRecentPosts"는 함수입니다. 특정 type에 바인딩된 함수일 수도 있고 패키지 내의 함수일 수도 있습니다. 여기서는 default 패키지이기 때문에 함수 앞에 아무런 제한자 없이 사용되었습니다. 이 함수는 굳이 main.go 파일 내에 있을 필요는 없습니다. 동일 패키지 내에만 있으면 됩니다.
main.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27type ApiResult struct { Data interface{} `json:"data"` Success bool `json:"success"` Message string `json:"message"` } func GetRecentPosts(c echo.Context) error { page, err := strconv.Atoi(c.QueryParam("page")) if err != nil { page = 1 } size, err := strconv.Atoi(c.QueryParam("size")) if err != nil { size = 4 } posts, err := Post{}.GetRecent(c.Request().Context(), page, size) if err != nil { return c.JSON(http.StatusInternalServerError, ApiResult{ Success: false, Message: err.Error(), }) } return c.JSON(http.StatusOK, ApiResult{ Success: true, Data: posts, Message: "", }) }
Action 내에서 DB에 접근하여 데이터를 가져올 수도 있지만 이런 로직들은 별도의 Post 타입을 생성하여 Post 타입에 바인딩 되어 있는 함수에서 실행하도록 하였습니다. Action 에서는 Post의 GetRecent 함수의 결과를 받아서 에러인 경우 에러 코드를 반환하고 정상이면 JSON 결과에 반환하도록 했습니다. ApiResult 타입은 별로도 지정된 타입으로 json으로 변환 시 어떻게 변환할 것인가에 대한 정보도 같이 제공하고 있습니다.
Popit API 서버는 아주 간단하기 때문에 별도 패키지 구성을 하지 않았는데 패키지로 구분하는 경우에는 다음과 같이 매핑할 수도 있습니다.
main.go
1api.ApiController{}.Init(e.Group("/api"))
api/api_controller.go
1 2 3 4 5 6 7 8 9package api type ApiController struct { } func (c ApiController) Init(g *echo.Group) { g.GET("/RecentPosts", c.Get) } func (ApiController) RecentPosts(c echo.Context) error { // 실제 로직 }
Model 구현
데이터 로딩, 연관관계 설정 등대부분의 연산은 모델에서 처리하도록 하였습니다. Post 타입에 대부분의 기능이 들어 있습니다. Post 타입 구현 시 많이 고민한 것이 API 서버에서 글 본문의 HTML 내용을 파싱해서 주는 것이 좋을지, 아니면 화면측에서 처리하는 것이 좋을지 였는데 결과적으로는 다른 데이터가 필요한 부분에서만 서버에서 처리하고 대부분은 화면에서 처리하도록 하였습니다. 이 부분은 React를 이용한 화면 구현 글에서 자세하게 다룰 예정입니다.
Post 타입은 다음과 같은 관계를 가지고 있기 때문에 이들 관계를 모두 로딩을 해야 합니다.
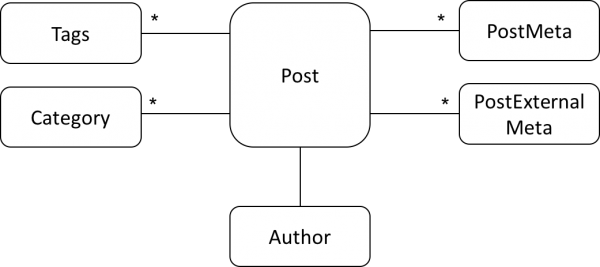
Post 목록을 로딩하는 구현은 다음과 같이 되어 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15func (Post)GetRecent(ctx context.Context, page int, pageSize int) ([]Post, error) { var posts []Post offset := (page - 1) * pageSize err := GetDBConn(ctx). Select("ID, post_author, post_content, post_title, post_date, post_name"). Where("post_status = 'publish'"). And("post_type = 'post'"). OrderBy("post_date desc"). Limit(pageSize, offset). Find(&posts) if err != nil { return nil, err } return loadPostAssoications(ctx, posts) }
WordPress의 wp_posts 테이블에는 공개된 post 이외에 post의 리비전 정보, page 데이터 등도 같이 포함되어 있기 때문에 코드에서와 같이 post_status, post_type 조건을 주어 데이터를 로딩합니다. xorm은 SQL 그 자체를 실행해도 되지만 이 경우 result set에서 컬럼 값을 직접 가져와야 하고, 다시 타입 캐스팅을 해야 하는 번거로움과 버그의 가능성이 있습니다. 따라서 가능하면 위와 같이 query builder 형태를 사용하는 것을 권장합니다. 마지막의 Find()가 실행되면 파라미터로 전달안 posts []Post에 결과 데이터가 반환됩니다. "&" 기호를 주어 주소값을 넘기는 것을 보면 C 언어의 포인터와 같은 개념이라고 생각할 수 있습니다.
loadPostAccocations 함수에서는 Post와 관련 연관 정보를 조회하기 위해서입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17func (p *Post) loadAssociations(ctx context.Context) error { if err := p.loadAuthor(ctx); err != nil { return err } if err := p.loadMeta(ctx); err != nil { return err } if err := p.loadCategoriesAndTerms(ctx); err != nil { return err; } if extraMetas, err := (PostExternalMeta{}).GetByPost(ctx, p.ID); err != nil { return err } else { p.Metas = extraMetas } return nil }
여기서 약간의 WordPress 데이터 모델을 알아야 하는데 loadMeta에서는 WordPress의 각 Post에 관련된 메타 정보를 가져옵니다. 실제로는 og:title, og:image 등과 같은 소셜 관련 정보를 가져와서 Post의 필드에 설정하고 있습니다. 이것은 사용하는 WordPress Plugin 하고도 관련이 있어 실제 데이터를 확인하면서 질의를 만들어야 합니다. Popit에서 구현된 내용은 대략 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19func (p *Post)loadMeta(ctx context.Context) error { var postMetas []PostMeta err := GetDBConn(ctx).Table("wp_postmeta"). Where("post_id = ?", p.ID). In("meta_key", "post_image", "_aioseop_description", "_aioseop_title"). Find(&postMetas) if err != nil { return err } for _, eachMeta := range postMetas { if eachMeta.Key == "post_image" { p.Image = eachMeta.Value } else if eachMeta.Key == "_aioseop_description" { p.SocialDesc = eachMeta.Value } else if eachMeta.Key == "_aioseop_title" { p.SocialTitle = eachMeta.Value } } }
빌드 및 실행
빌드 및 실행이 Go 관련해서 가장 마음에 드는 부분 중에 하나입니다. 물론 의존 관계에 있는 라이브러리은 모두 로컬에 가지고 있어야 하는데 이것도 가장 심플하게는 go get이나 다른 의존성 관리 도구를 이용하면 쉽게(?) 가져올 수 있습니다. 빌드는 해당 소스 디렉토리에서 "go build . " 명령을 실행하면 디렉토리 이름으로 생성됩니다. Popit의 경우 "popit_api" 바이너리로 생성됩니다. 실행은 "./popit_api" 라고 하면 바로 실행이 됩니다. 물론 백그라운드로 실행하기 위한 쉘 명령 옵션은 추가해야 하지만 아주 심플하게 실행할 수 있습니다.
마치며
WordPress 자체에도 API를 제공하지만 여러가지 자유로운 기능을 구현하기 위해 별도로 Go를 이용하여 API 서버를 구현하였습니다. 그리고 이렇게 글로 소개하는 이유는 저와 비슷한 요구사항을 가진 회사나 블로그 운영자가 있을 것 같아 이분들에게 조금이나마 도움이 될 수 있을 것 같아 소스코드와 글을 공유하였습니다. 가능한 기교를 사용하지 않고, 기본 기능만 이용하여 만들려고 하였습니다. 사용하면서 궁금한 사항이나 이슈가 있으면 github 이슈로 남겨 주세요.
다음 글에서는 React로 화면을 구성한 내용에 대한 글입니다. 이 글에서는 워드프레스의 본문을 파싱한 방법과 Server Side Rendering 등에 대해 알아보도록 하겠습니다.
각주
[1]: Spring Boot와 AngualrJS를 조합한 코드 자동 생성 도구(scaffolding)
[2]: 중국에서의 echo 프레임워크 사용에 대한 결정은 "Go 언어 웹 프로그래밍 철저 입문" 책의 저자인 장재휴 님이 추천하였습니다.
[3]: 추가 기능을 만들때에는 트렌젝션도 들어갈 예정입니다.
[4]: 물론 복잡한 비즈니스 로직이 추가되거나 하면 내부 로직에서 제어 하는 경우도 있습니다.
[5]: 실제 구현된 코드에는 DB session을 가져와서 context에 추가하는 코드만 있고 트렌젝션 제어하는 코드는 아직 적용하지 않았습니다.