개발자가 배우는 R : 3강, 데이터프레임과 파일 입출력

개요
이번 포스팅에는 R의 객체중 factor와 데이터 프레임을 배우고 파일 import, export를 배워본다. 객체 자체는 지난 시간에 다뤘지만 리스트와 데이터 프레임은 파일 import/export와 연관이 많아 이번 시간에 설명한다. 코드중심의 설명이기 때문에 본문 보다는 코드의 주석이 집중적으로 추가되어 있으니 참고 바란다.
R 자료구조(factor, 데이터프레임)
factor
설문조사의 객관식 처럼 순서와 카테고리가 정해져 있는 자료구조를 factor라고 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20> x <- c(5, 12, 13, 12) # 벡터를 factor로 변환하면 고유값만 가지게 정리된다. > xf <- factor(x) > xf [1] 5 12 13 12 Levels: 5 12 13 > xff <- factor(x, levels=c(5,12,13,88)) # levels를 명시적 옵션으로 줄 수 있다. > xff [1] 5 12 13 12 Levels: 5 12 13 88 > xff[2] <- 88 # xff의 2번째 값을 88로 할당을 바꿈, 레벨 안에서 값의 위치만 바뀜 > xff [1] 5 88 13 12 Levels: 5 12 13 88 > xff[2] <- 28 # 왼쪽과 같이 level값에 없는 것을 지정하면 warning이 발생한다. Warning message: In `[<-.factor`(`*tmp*`, 2, value = 28) : invalid factor level, NA generated > xff [1] 5 <NA> 13 12 Levels: 5 12 13 88
리스트
하나의 객체 안에 벡터, 행렬, factor, list등 여러가지 데이터 구조를 담을수 있는 컬렉션 데이터 구조
리스트 생성
1 2 3 4 5 6 7 8> j <- list(name="Joe", salary=55000, union=TRUE) # 문자열, 정수, boolean값이 섞여서 들어간다. > j $name [1] "Joe" $salary [1] 55000 $union [1] TRUE
리스트 원소 접근
원소의 접근은 아래와 같은 방식으로 접근 가능하다.
1 2 3 4 5 6> j$salary [1] 55000 > j[["salary"]] # 리스트는 반드시 중괄호를 2개 써야함 [1] 55000 > j[[2]] [1] 55000
주의 할 점은 리스트의 원소값에 접근할때는 []이 아니라 [[]]를 사용해야 한다는 점이다. [] 기호를 하나만 쓰면 부분 리스트(sub list)로 인식된다.
1 2 3 4 5 6 7> j["salary"] # j[2]는 key, value인 Salary, 55000이 담겨있는 것을 확인 할 수 있다. $salary [1] 55000 > class(j[2]) [1] "list" > class(j[[2]]) [1] "numeric"
리스트에 원소 추가
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19> j$age <- 28 # same as j[["age"]] <- 28 > j $name [1] "Joe" $salary [1] 55000 $union [1] TRUE $age [1] 28 아래와 같이 NULL값으로 원소를 초기화 할 수 있다. > j$age <- NULL > j $name [1] "Joe" $salary [1] 55000 $union [1] TRUE
리스트 크기 알아내기
1 2> length(j) [1] 3
Apply
리스트도 apply 함수 적용이 가능하다. 코드예제를 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13> x <- list(1:3, 25:29) # 아래와 같이 값이 들어가 있는 리스트를 생성함 > x [[1]] [1] 1 2 3 [[2]] [1] 25 26 27 28 29 > lapply(x, median) # 리스트용 apply 함수, 각각의 index별로 평균을 구함 [[1]] [1] 2 [[2]] [1] 27 > sapply(x, median) # simplified된 lapply 함수 [1] 2 27
Data Frame
데이터 프레임은 행렬과 같은 2차원은 행과 열을 가지는 자료구조이다. 그러나 행렬과 다른점은 각각은 칼럼들은 다른 데이터 타입을 가질 수 있다. 데이터 프레임은 R에서 가장 자주쓰는 자료구조로써 외부 파일을 불러와서 등에서 많이 사용한다.
데이터 프레임 생성
1 2 3 4 5 6 7> kids <- c("Jack", "Jill") > ages <- c(12, 10) > d <- data.frame(kids, ages) > d kids ages 1 Jack 12 2 Jill 10
데이터 프레임을 만들때 문자열을 factor로 보지 않게 만드려면 아래와 같이 옵션을 지정해 주면 된다.
1> d <- data.frame(kids, ages, stringsAsFactors=FALSE)
데이터 프레임 원소 접근
데이터 프레임의 원소 접근은 리스트의 원소 접근과 동일하다.
1 2 3 4> d[[2]] [1] 12 10 > d$ages [1] 12 10
또한 행렬과 같이 행/렬 개념으로 원소 접근을 할수도 있다.
1 2> d[,2] [1] 12 10
일부 데이터 원소 접근은 행렬 원소 접근 방식만 알고 있으면 새로울 것이 없다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32> exam1 <- c(2.0, 3.3, 4.0, 2.3, 2.3, 3.3) > exam2 <- c(3.3, 2.0, 4.0, 0.0, 1.0, 3.7) > exams <- data.frame(exam1, exam2) > exams exam1 exam2 1 2.0 3.3 2 3.3 2.0 3 4.0 4.0 4 2.3 0.0 5 2.3 1.0 6 3.3 3.7 > exams[2:5,] exam1 exam2 2 3.3 2 3 4.0 4 4 2.3 0 5 2.3 1 > exams[exams$exam1 >= 3.0,] # exam1이 3.0보다 큰 행, 모든 열을 가져온다. exam1 exam2 2 3.3 2.0 3 4.0 4.0 6 3.3 3.7 > subset(exams, exams$exam1 >= 3.0) # exam1이 3.0 이상인 데이터 셋으로 서브셋을 만들어 냄 exam1 exam2 2 3.3 2.0 3 4.0 4.0 6 3.3 3.7 > subset(exams, exam1 >= 3.0) # 바로 위 수식을 더 간단하게 왼쪽과 같이 더 많이 사용한다. exam1 exam2 2 3.3 2.0 3 4.0 4.0 6 3.3 3.7
데이터 프레임에 원소 추가
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15> rbind(d, data.frame(kids="Laura", ages=19)) kids ages 1 Jack 12 2 Jill 10 3 Laura 19 > diff <- exams$exam2-exams$exam1 # exam2와 exam1의 차이를 diff 벡터로 만듦 > eq <- cbind(exams, diff) # exams에 diff로 열을 붙임 > eq exam1 exam2 diff 1 2.0 3.3 1.3 2 3.3 2.0 -1.3 3 4.0 4.0 0.0 4 2.3 0.0 -2.3 5 2.3 1.0 -1.3 6 3.3 3.7 0.4
데이터 프레임에 Apply 함수 적용하기
행렬때와 동일하다.
1 2 3 4 5> apply(exams, 1, mean) # 행별 적용 [1] 2.65 2.65 4.00 1.15 1.65 3.50 > apply(exams, 2, mean) # 열별 적용 exam1 exam2 2.866667 2.333333
데이터 프레임 Merge
kids 값을 기준으로 매칭하여 merge 한다. DB의 inner join으로 이해하면 된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18> kids <- c("Jack", "Jill", "Jillian", "John") > states <- c("CA", "MA", "MA", "HI") > d1 <- data.frame(kids, states) > d1 kids states 1 Jack CA 2 Jill MA 3 Jillian MA 4 John HI > ages <- c(10, 7, 12) > kids <- c("Jill", "Jillian", "Jack") > d2 <- data.frame(ages, kids) > d <- merge(d1, d2) > d kids states ages 1 Jack CA 12 2 Jill MA 10 3 Jillian MA 7
merge시에 서로 일치하는 key값으로 쓰일 칼럼명을 찾지 못할 경우 명시적으로 각 데이터 프레임에서 어떤것을 key으로 쓸지 명시 할 수 있다.
1 2 3 4 5 6 7> ages <- c(12, 10, 7) > pals <- c("Jack", "Jill", "Lillian") > d3 <- data.frame(ages, pals) > merge(d1, d3, by.x="kids", by.y="pals") kids states ages 1 Jack CA 12 2 Jill MA 10
R에서 파일 다루기
외부 데이터 파일 import
외부 데이터 불러오기를 실습하기 위한 샘플 파일은 github에 올려두었다. 아래의 필자의 경로는 무시하고 파일명은 동일하니 활용하면 되겠다.
TXT 파일 import
외부 데이터 파일을 불러오는 문법은 아래와 같다. 하지만 많이 쓰는 방식은 아니다.
1 2 3 4 5 6 7 8 9 10> records <- read.fwf("filename", widths=c(w1, w2, ..., wn)) 고정너비는 아래와 같이 사용하면 되는데 자주 사용하는 방법은 아니다. > records <- read.fwf("file:///home/lks21c/Downloads/ch2_1/fixed-width.txt", widths=c(10, 10, 4, -1, 4)) > records V1 V2 V3 V4 1 Fisher R.A. 1890 1962 2 Pearson Karl 1857 1936 3 Cox Gertrude 1900 1978 4 Yates Frank 1902 1994 5 Smith Kirstine 1878 193
칼럼 이름까지 지정하는 것은 아래와 같다.
1 2 3 4 5 6 7 8> records <- read.fwf("file:///home/lks21c/Downloads/ch2_1/fixed-width.txt", widths=c(10, 10, 4, -1, 4),col.names=c("Last", "First", "Born", "Died") ) > records Last First Born Died 1 Fisher R.A. 1890 1962 2 Pearson Karl 1857 1936 3 Cox Gertrude 1900 1978 4 Yates Frank 1902 1994 5 Smith Kirstine 1878 193
데이터프레임으로 파일 import
데이터 프레임으로 불러오는 문법이다.
1> dfrm <- read.table("filename", sep="") # sep는 구분자로 쓸 문자열을 의미한다.
데이터 프레임으로 직접 불러오는 코드를 실행해 보자.
1 2 3 4 5 6 7 8> dfrm <- read.table("file:///home/lks21c/Downloads/ch2_1/statisticians.txt", sep="") > dfrm V1 V2 V3 V4 1 Fisher R.A. 1890 1962 2 Pearson Karl 1857 1936 3 Cox Gertrude 1900 1978 4 Yates Frank 1902 1994 5 Smith Kirstine 1878 1939
칼럼명을 포함하여 불러오는 방법은 아래와 같다.
1 2 3 4 5 6 7> dfrm <- read.table("file:///home/lks21c/Downloads/ch2_1/statisticians.txt", header=TRUE, sep="") > dfrm Fisher R.A. X1890 X1962 1 Pearson Karl 1857 1936 2 Cox Gertrude 1900 1978 3 Yates Frank 1902 1994 4 Smith Kirstine 1878 1939
CSV 파일 import
R에서 가장 많이 사용하는 방식이다. CSV를 불러오는 방법은 아래와 같다. 일반적으로 엑셀파일을 CSV로 변환하여 R에서 불러서 많이 쓴다.
1 2> tbl <- read.csv("filename") > tbl <- read.csv("filename", header=FALSE)
위의 문법대로 실제로 CSV를 한번 불러보자.
1 2 3 4 5 6 7 8 9 10 11 12 13> tbl <- read.csv("file:///home/lks21c/Downloads/ch2_1/table-data_h.csv") > tbl label lbound ubound 1 low 0.000 0.674 2 mid 0.674 1.640 3 high 1.640 2.330 > tbl <- read.csv("file:///home/lks21c/Downloads/ch2_1/table-data_h.csv", header=FALSE) > tbl V1 V2 V3 1 label lbound ubound 2 low 0 0.674 3 mid 0.674 1.64 4 high 1.64 2.33
CSV 파일로 export
문법은 아래와 같다.
1> write.csv(x, file="filename")
위의 문법대로 csv로 저장해보자.
1> write.csv(tbl, file="/home/lks21c/Downloads/ch2_1/write.csv", row.names=FALSE)
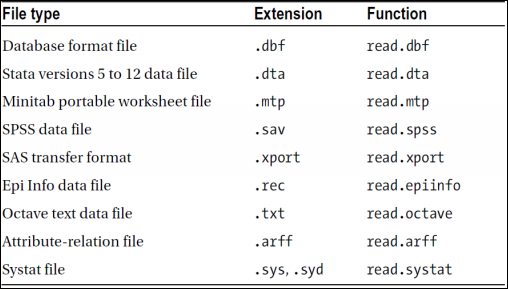
Foreign 패키지
위에서 언급하지 않은 특수한 파일형식을 불러와야 한다면 R에서 제공하는 foreign 패키지를 참조하면 된다.