grok 필터 성능 테스트

로그 분석을 데이터 분석 수준으로 끌어올리려면 원시로그 덩어리를 필드별 고유성이 확보된 테이블 구조로 바꿔야 하는데, 이때 grok 필터의 역할은 독보적이다. 한가지 단점이라면 정규표현식을 이용하기 때문에 성능이 저하될 수 있다는 것. grok 필터는 로그스태시 필터링 성능에 얼마나 영향을 끼칠까?
윈도우8, i5(CPU), 8GB(Memory), SSD(mSATA) 사용 환경에서 아파치 웹로그 백만 개 입력 테스트를 해봤다. 아파치 웹로그용으로 제공되는 grok 패턴(COMMONAPACHELOG)을 사용한 결과 입력 완료까지 4분 소요.배꼽시계로 측정
1 2 3 4 5filter { grok { match => { "message" => "%{COMMONAPACHELOG}" } } }
다음은 COMMONAPACHELOG 패턴에 사용되는 정규표현식을 실제 나열한 결과. 1줄의 로그를 검사하는데 172 단계를 거친다.
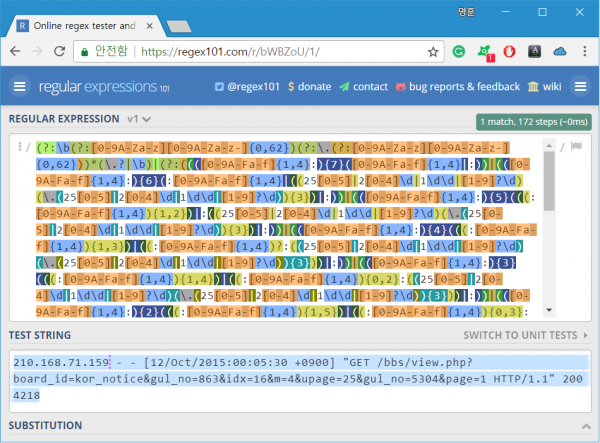
이번엔 정규표현식을 직접 작성해봤다.
1 2 3 4 5filter { grok { match => { "message" => '(?<client>^.{14}) - - \[(?<timestamp>[^\]]+)\] "(?<method>\S+) (?<request>\S+) HTTP\/(?<http_version>[^"]+)" (?<status>\S+) (?<bytes>\S+)' } } }
미리 정의된 grok 패턴 정규표현식은 다양한 상황에서도 사용할 수 있는 범용성을 갖추고 있다. 한마디로 복잡하다는 얘기. 하지만 대상 로그의 특징을 이용하면 정규표현식에 대한 간단한 이해만으로도 훨씬 단순한 정규표현식 작성이 가능하다. 다음은 28단계로 검사를 끝내는 사용자 grok 패턴 정규표현식.
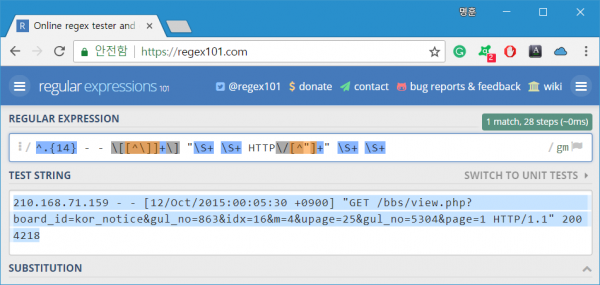
검사 과정이 6/1로 줄었으니 성능은 6배 빨라지겠지? 부푼 가슴을 안고 실행한 결과는 3분 50초 소요. 에게? 겨우 10초 빨라졌다고 해야 하나? 아님 무려 10초나 빨라졌다고 해야 하나? 컴퓨터가 일을 잘하는 건가? 정규표현식이 일을 잘하는 건가? 성에 차진 않지만 문자열 길이가 늘어나면 성능 차이가 더 벌어질 거라 생각하며 애써 위안.
내친 김에 정규표현식이 필요없는 dissect 필터도 테스트해봤다.
1 2 3 4 5filter { dissect { mapping => { "message" => '%{client} %{} %{} [%{timestamp} %{+timestamp}] "%{method} %{request} %{}" %{status} %{bytes}' } } }
실행 결과 3분 40초 소요. 성능 차이가 생각보다 크진 않지만 그래도 복잡한 정규표현식, 간단한 정규표현식, 정규표현식 사용 안함 순서대로 아주 정직한 결과가 나왔다. 대상 로그에서 필드 분류를 원하는 영역에 일괄적으로 적용되는 구분자만 있다면, dissect 필터는 만족스러운 결과를 보여준다. 문제는 그런 경우를 본 적이 없다(..)
정리하면, 정규표현식의 복잡도나 사용 유무는 로그스태시 필터링 성능에 큰 영향을 주지는 않는 것 같다. 물론 로그양 등에 따라 결과는 달라질 수 있지만, 하드웨어가 빵빵하다면 쓰고싶은 거 쓰면 될 듯. 하지만 눈곱만큼이라도 성능 개선이 필요하다면 dissect 필터로 뭉텅 뭉텅 자른 후, grok 필터로 다듬는 식의 해법이 최선이 되지 않을까 싶다.