[삽질기] JDBC를 통한 하둡 적재, 알면 도움되는 삽질 이야기 1편

Pain past is pleasure!
이번 글에서는 JDBC를 통해 하둡에 데이터를 적재할때 한번 쯤 고민해 볼만한 주제로 삽질기를 공유하려고 한다. 먼저 필자가 경험한 내용은 아주 특이한 케이스로 일반적인 경우에 해당되지 않는다. 주위에 이런 삽질을 하는 사람도 있구나 라고 참고만 하시길...
기존 레거시에 있는 데이터 베이스로부터 하둡에 데이터를 적재할 때, 가장 많이 쓰는 방식은 JDBC를 통해 데이터를 로딩하여 하둡 에코 시스템에 적재하는 방식일 것이다. 가장 잘 알려진 오픈소스 기술로는 sqoop이 있다.
Sqoop을 고민하다
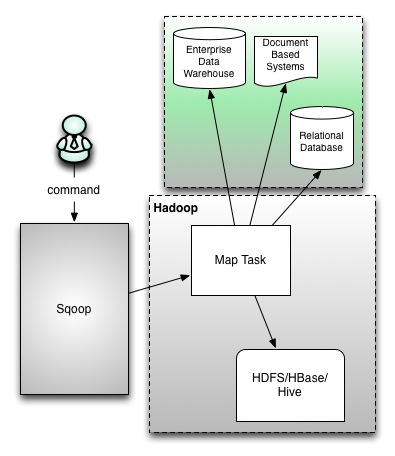
sqoop1 architecture (https://blogs.apache.org/sqoop/entry/apache_sqoop_highlights_of_sqoop)
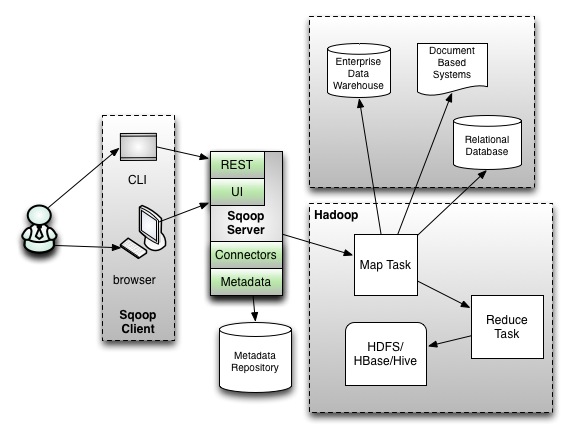
sqoop2 architecture (https://blogs.apache.org/sqoop/entry/apache_sqoop_highlights_of_sqoop)
JDBC를 통해 데이터를 적재해야 하는 케이스에 대해 주저없이 선택한 기술은 sqoop이다. 이미 몇몇 과제에서 sqoop을 통해 hadoop에 데이터를 적재하고 있었고, 해당 기술을 써본 분들께서는 훌륭하기 그지 없다는 칭찬일색이였다. (간단한 사용법과 기존 환경에서 손쉬운 설치 및 구성 그리고 분산하여 벌크 데이터를 로딩할 수 있는 점 등)
sqoop은 위와 같이 sqoop1과 sqoop2로 나뉘는데 각각 아키텍처를 설명하면 다음과 같다. sqoop1과 sqoop2의 공통적인 부분은 기존 레거시에 존재하는 데이터 베이스에 대해 JDBC방식의 질의를 통해 대량으로 데이터를 hadoop으로 업로드(HDFS/HBase/Hive)하는 data import 기술이다.
sqoop은 workflow툴인 oozie 등과 연동되어 주기적으로 기존 레거시에 있는 데이터를 하둡에 적재하는데 활용되고 있다. sqoop1에서는 cli기반으로 수집에 관한 명령어를 수행 할 수 있는 반면 sqoop2에서는 중간에 서버를 두어 처리하고 별도의 UI를 제공한다. sqoop1방식에서는 필요로 하는 JDBC connector를 그때그때 설치해주어야 하는 번거로움과 CLI라는 제약이 있었다면 sqoop2에서는 REST방식도 지원하며 서버에 필요로 하는 connector를 설치하여 사용할 수 있고 Security측면에서 강화된 부분이 있다. 자세한 내용은 apache sqoop 를 참고하기 바란다.
문제의 시작
데이터 수집 대상 시스템이 DB 인 경우라면 이렇게 고통스럽진 않았을텐데, 문제의 발단은 다음과 같다.
최종 데이터가 저장되는 곳은 실시간 OLAP저장소인 Druid 엔진이다. Druid에 인덱싱 하기 위한 방식은 실시간 방식 과 배치 방식이 있다.
Druid는 데이터가 적재된 이후부터는 데이터 소스간 JOIN 질의를 지원하지 않는다. (Druid에 색인된 데이터와 다른 데이터와 조인할 수 있는 방식은 lookup 방식만 가능하다. 예를 들어 코드 테이블이 별도로 존재하고 Druid검색 결과에서 코드에 매핑되는 코드명을 리턴해야 하는 경우 등에 사용할 수 있다.) JOIN 이 필요한 경우라면 Ingestion시점에 JOIN을 수행하여 결과 셋을 Druid에 적재하는 방식이여야 한다.
Druid에 적재해야 하는 데이터는 기존 하둡 기반에 데이터 웨어 하우스에 존재한다. 시간당 2~300M(ORC) 정도의 컬럼은 대략 200내외의 데이터이며 필요시 JOIN 또는 SQL인터페이스(UDF, 포맷변경 등) 통해 데이터를 추출해야 한다. 별도로 Hive Thrift (Hive on Tez)를 구동하여(기존 메타스토어는 공유) 빨대를 꽂기로 결정하고 데이터 수집용 Hive Thrift를 띄웠다.
Sqoop은 기본적으로 hive connector를 지원하지 않는다. 그러나 hive thrift 도 JDBC연결을 지원하기 때문에 hive-jdbc 라이브러리를 추가하고 sqoop 소스에서 HiveConnection관련 약간의 리터칭(?)을 통해 연결은 가능하다.
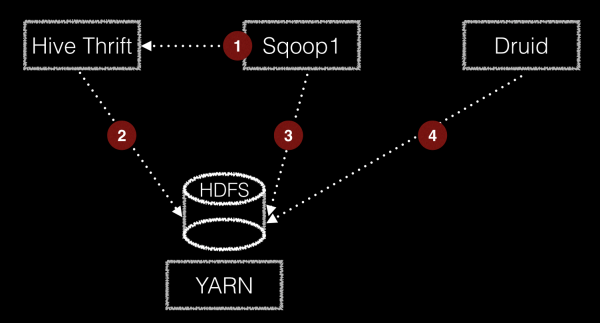
jdbc ingestion architecture
수집 방식은 위의 그림과 같다.
sqoop1이 hive thrift를 통해 수집 명령을 SQL 질의하고 결과 output은 HDFS에 write한다. Druid는 해당 path에 HDFS의 데이터를 읽어 배치로 ingestion하여 Druid segment로 적재한다. 덧붙여 이 모든 작업은 YARN 을 통해 수행한다. 좀 복잡해 보이는 컴포넌트간 통신은 내부에서 agent와 server api형태로 구현하여 연동하였다. :cry:
도식에서 보듯이 sqoop을 통해 데이터가 질의되며 이때 분산해서 질의를 처리 할 수 있는데 split-by, num-mappers를 줄 수있다. split-by는 데이터를 import하기 위한 질의를 분산할 수 있는 단위 키를 지정하면 된다. num-mappers는 sqoop에서 HDFS로 데이터를 적재할 수 있도록 병렬적으로 수행할 수 있는 map task 개수이다. sqoop에서는 기본적으로 split-by 필드 기준으로 select min(<split-by>), max(<split-by>) from <table name> 전체 데이터에 대한 split기준을 계산하게 된다. 균등하게 분산하려면 적절한 키 값을 주어야 한다.
무엇이 문제인가?
원하는 것은 질의를 통한 데이터 수집인데, 해야 할 일이 너무나 많다. sqoop에서 thrift로 부터 질의를 통해 데이터를 가져오려고 하면 thrift의 질의는 YARN으로 구동되어 결과를 처리하고 sqoop은 YARN으로 구동되어 데이터를 HDFS에 적재한다. 적재된 데이터에 대해 Druid는 배치 Ingestion을 수행하고 이것 또한 MR방식이다. Druid에 데이터 적재를 위해 YARN에 또 어플리케이션이 구동되는 것이다. 데이터 적재를 위해 YARN 에 구동되는 어플리케이션은Hive,Sqoop,Druid 이렇게 3가지 타입인 것이다.
왜 이리 빈번한 작업을 하는것인가? 앞서 이야기한것처럼 JDBC로 데이터를 질의하는 양이 적지 않다. 시간당 2~300M이고 원본 데이터만 가져와서 색인하는 경우라면 HDFS를 바로 읽겠지만 필요시 다른 데이터와의 조인 및 데이터 변환 작업이 필요하다. JDBC 타입의 범용적인 데이터 색인을 위해 만든 기능인데, 결과적으로는 참으로 비효율 적인 방식이 되어버렸다.
처음에는 빠른 처리를 위해 split-by를 여러개로 주고 num-mappers 의 개수도 크게 했을때, 수많은 질의들이 Thrift에서 발사(?)되었고 Thrift서버는 부담감을 느꼈는지 다양한 메모리 이슈와 hang이 발생되었다. 결국엔 단일 테이블의 데이터를 그대로 적재하는 경우 Druid에서 HDFS에서 데이터(ORC format)를 바로 읽어 적재할 수 있도록 HDFS Ingestion 방식으로 구현 하였다. 또한, JDBC로 하루치 데이터를 한번에 ingestion하기에는 데이터가 너무 커서 시간별로 질의를 수행하여 수집하도록 하였다.
좋은 방법이 있다면?
좋은 방법은 가능하다면 Hive를 통해 ETL을 수행하고 결과 데이터를 Druid에 적재하는 방식일 것이다. Hive를 통해 Druid를 질의하는 방식은 일부 제공하고 있지만 적재에 관한 부분은 아직 진행되고 있지 않다. (https://cwiki.apache.org/confluence/display/Hive/Druid+Integration)
좋은 아이디어가 있거나 좋은 기술이 있다면 주저말고 필자에게 알려주시길....