HIVE


2018-02-20
Hive의 CLI 명령을 Crontab에 등록하여 주기적으로 작업하는 경우가 가끔있습니다. 예를 들면 로그를 매일 새로운 파티션에 저장하는 경우 강제적으로 Hive에 파티션을 추가해야 하는 작업 등이 있습니다. 보통 Crontab의 shell 환경은 터미널로 접속했을 때와의 shell 환경과는 조금 차이가 있는데, 이번 글은 이런 차이로 인해 발생한 문제 및 삽질기에 대한 내용입니다. 문제 상황 Crontab에서 다음과 같은 Hive 파티션 생성 스크립트를 매일 새벽 00:05 분에 실행하도록 설정...


2017-11-13
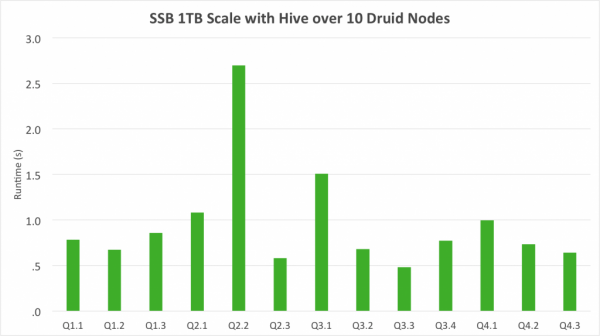
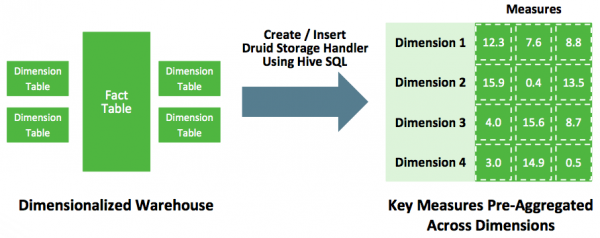
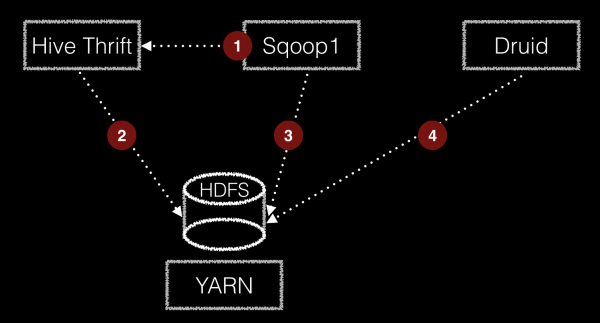
Hive에 있는 데이터 Druid에 적재하려면? 다음과 같은 다양한 삽질 방법이 존재한다. Hive에 metastore로부터 hdfs location을 파악한 후 orc format이나 parquet format이냐에 따라 그에 맞는 hadoop ingestion spec을 작성해야함. orc인 경우 struct type정보를 잘 파악해야하며, parquet인 경우에는 avro schema를 읽기 때문에 orc에 비해 덜 번거롭다. 자세한 내용은 요기를 참고: ORC ingestion spec , Parquest ingestion spec -> 여기서 문제점 하나가 발생 partition column의 경우는 어떻게 ingestion하지? partition column이 dimension이나 metric 또는 timestamp로 들어가는 경우가 있어서 이를 위해서는 별도 패치가 필요하다. 다행히 내부 브랜치에서 이런 기능을 구현하여 사용중...

2016-11-14
Pain past is pleasure!
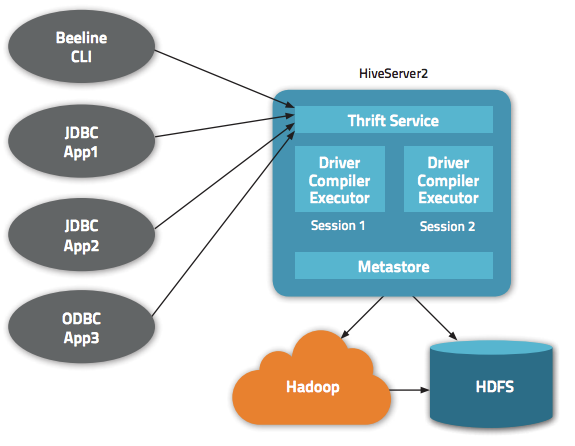
이번 글에서는 JDBC를 통해 하둡에 데이터를 적재할때 한번 쯤 고민해 볼만한 주제로 삽질기를 공유하려고 한다. 먼저 필자가 경험한 내용은 아주 특이한 케이스로 일반적인 경우에 해당되지 않는다. 주위에 이런 삽질을 하는 사람도 있구나 라고 참고만 하시길...
기존 레거시에 있는 데이터 베이스로부터 하둡에 데이터를 적재할 때, 가장 많이 쓰는 방식은 JDBC를 통해 데이터를 로딩하여 하둡 에코 시스템에 적재하는 방식일 것이다. 가장 잘 알려진 오픈소스 기술로는 sqoop이 있다....


2016-09-13
Hive Metastore contains multiple versions Exception 해결방법...


더보기