HADOOP

2020-11-11
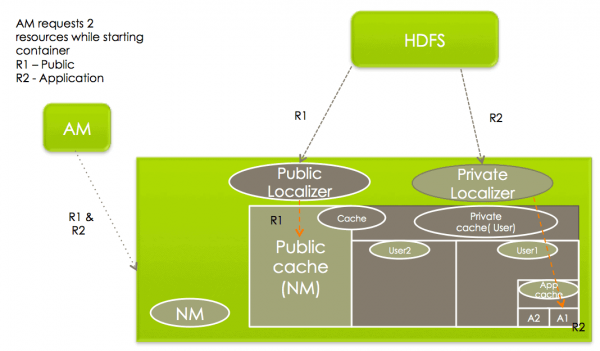
Hadoop ResourceLocalizationService 에 대한 설명과 트러블슈팅 내용...

2020-01-13
수많은 회사들이 인공지능 모형개발과 서비스를 만들기 위해 다양한 노력을 기울이고 있습니다. 바야흐로 데이터와 인공지능의 시대가 열렸는데요, 필자가 Popit 에 SK텔레콤, Hadoop DW 와 데이터 분석환경 구축사례 를 기고 했던 것도 벌써 수 년이 흘렀고, 현재는 하루 수백명의 사내 구성원이 사용하는 분석환경이 되었습니다. 이 분석환경을 구성하는 기술 플랫폼들은 그동안 여러가지 신규 기술이 도입되고 변화되어 왔지만, 에코시스템의 가장 근간이 되는 하둡 플랫폼의 버전은 2.7 버전(HDP)을 꽤 오랫동안 유지해 왔습니다. 얼마 전, 오랫동안 업그레이드 하지 못했던 하둡의 버전을 2.7 에서 3.1로 올리는 작업을 진행했는데, 이후 운영과정에서 발생했던 문제와 그 해결과정을 공유해 보고자 합니다....


2018-04-23
최근 아파치 하둡 3.1.0의 출시로 HDFS 의 Erasuere Coding 외에 분산 자원 관리자인 YARN에 특히 실용적인 기능들이 적용되었는데, 어떠한 기능들인지 차근차근 소개하겠습니다. ...

2018-04-19
스파크 스트리밍이 시작 되었을 때, 데이터를 처리하는 내부 동작을 설명합니다....


2017-11-13
Hive에 있는 데이터 Druid에 적재하려면? 다음과 같은 다양한 삽질 방법이 존재한다. Hive에 metastore로부터 hdfs location을 파악한 후 orc format이나 parquet format이냐에 따라 그에 맞는 hadoop ingestion spec을 작성해야함. orc인 경우 struct type정보를 잘 파악해야하며, parquet인 경우에는 avro schema를 읽기 때문에 orc에 비해 덜 번거롭다. 자세한 내용은 요기를 참고: ORC ingestion spec , Parquest ingestion spec -> 여기서 문제점 하나가 발생 partition column의 경우는 어떻게 ingestion하지? partition column이 dimension이나 metric 또는 timestamp로 들어가는 경우가 있어서 이를 위해서는 별도 패치가 필요하다. 다행히 내부 브랜치에서 이런 기능을 구현하여 사용중...

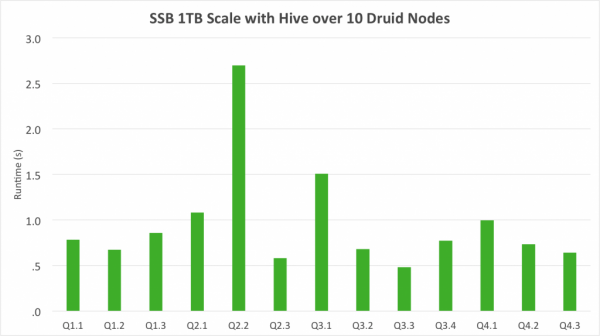
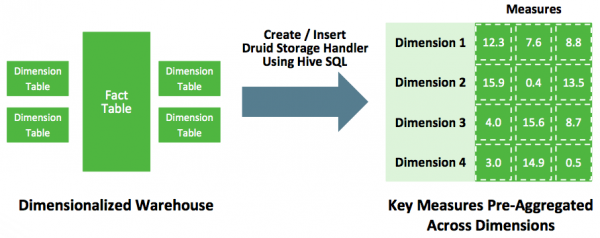


더보기