BIG-DATA

2018-05-15
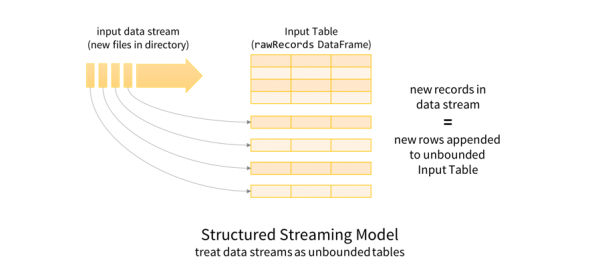
Structured Streaming Structured Streaming은 Spark2.X에서 새롭게 나온 Spark SQL엔진 위에 구축된 Stream Processing Framework이다. Structured Streaming은 기존에 Spark APIs(DataFrames, Datasets, SQL) 등의 Structured API를 이용하여 End-to-End Streaming Application을 손쉽게 만들 수 있다. 또한 input data에 대한 Streaming데이터 처리 후 checkpointing과 write-ahead logs를 통한 exactly-once하고 fault-tolerance한 프로세싱을 지원한다. 또한, 늦게 오는 데이터에 대해 처리가 가능하며 Continuous Processing Mode로 1ms미만의 latency를 제공한다. 각각에 대해서는 개별 글을 통해 공유해 보도록 하겠다. Structured Streaming의 주요한 아이디어 중 하나는 input으로 들어오는 stream데이터에 대해 table형식으로 append를 할 수 있다는 점이다. 즉, DataFrame을 통해 streaming으로 들어오는...

2016-08-03
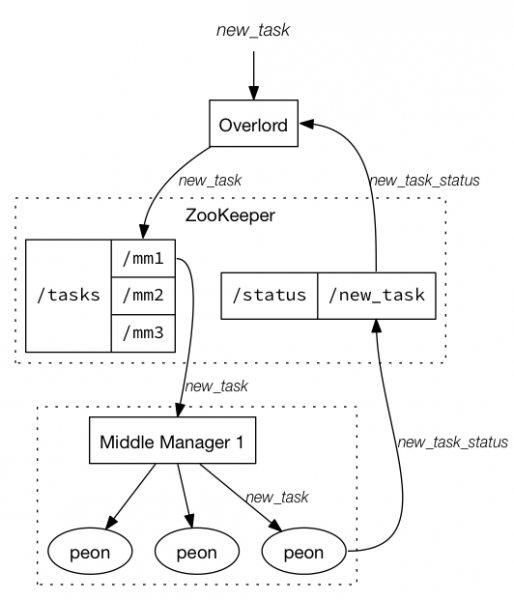
Druid 의 불꽃 전쟁의 서막을 못보셨다면 1편부터 시작 ^^ ::: Druid 입문 당신은 지체할 수도 있지만 시간은 그러지 않을 것이다. - 벤자민 프랭클린 Druid에서 실시간 처리 방식에는 Stream Push방식과 Stream Pull방식이 있다. [참고 : http://druid.io/docs/latest/ingestion/stream-ingestion.html ] 실시간 처리 소개 전에 Indexing service에 대해 잠깐 짚고 넘어가자면 다음과 같다. [참고 : http://druid.io/docs/latest/design/indexing-service.html ] Druid의 indexing service는 위의 도식과 같이 세가지 컴포넌트로 구성된다. 1. Peon : 단일 jvm에서 수행되는 하나의 태스크를 말하며 Middle Manager에 의해 생성된다. 2: Middle Manager : 요청된 작업 분배 등의 Peon을 관리하는 역할을 수행한다. 3: Overload는 task의 분산을 관리하며 local또는 remote의 다수의Middle Manager를 구성할 수 있다....
더보기