PRESTO

2020-08-18
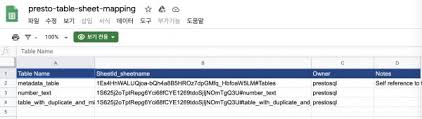
데이터를 보는 많은 분들이 특징이 내가 만든 또는 내 PC의 엑셀에 있는 데이터하고 DB와 같이 서버에 있는 데이터하고 같이 볼 수 있는 방법이 없나? 라는 요구사항입니다. 이번 글에서 비슷하게 나마 요구사항을 만족시킬 수 있는 방법을 소개해 드리겠습니다. 최근 지인의 요청으로 AWS 환경을 좀 볼 수 있는 시간을 가졌습니다. 지인의 서비스는 작년 하반기 부터 갑작스럽게 성장하면서 데이터가 많아지고 분석의 요구도 많아지는데 전문적으로 이를 처리할 수 있는 개발 인력이나 조직은 거의 없는 상태였습니다. 물론 AWS의 좋은 서비스 덕분에 그럭저럭 운영은 하고 있었지만 한계에 부딪히고 있었는데 이런 저런 니즈가 서로 부합되어 잠시 도움을 주게 되었습니다. 대략 데이터 발생원으로 부터 정제된 형태의 데이터로 저장하는 데이터 파이프라인을 구성하고 이를 기반으로 SQL 등으로 쉽게 분석할 수 있는 체계를 만드는 작업이었습니다. 이번 글에서는 Google Sheet의 각 파일과 MySQL 또는 HDFS, S3 등에 저장된 데이터와 JOIN을 할 수 있는 방법에 대해 간단하게 소개해 드리겠습니다....
2016-12-27
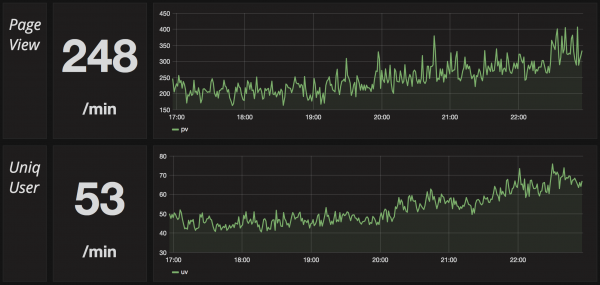
서비스를 운영하는 조직에서는 PV, UV 등과 같은 지표를 꾸준하게 관리하고 있습니다. 각종 지표를 꾸준하게 관리하는 이유는 서비스가 기획 의도했던 방향대로 사용자가 사용하고 있는지, 서비스의 문제는 없는지 등을 파악하기 위함입니다. 간단하게 이런 지표는 엑셀 등으로 관리할 수 있지만 많은 사람들이 공유하기 어렵고, 실시간 데이터를 바로 반영하기 어렵습니다. 또한, 새로운 기능을 출시하고 이 기능에 사용자가 어떻게 반응하는지 확인하기 위해서는 개발팀이 데이터를 지속적으로 뽑아 줘야 하는 경우가 많습니다.
이번 글에서는 Kafka에 저장된 로그 데이터나 MySQL에 저장된 실제 트렌젝션 데이터를 이용하여 코드 작성 없이 SQL(또는 유사한 질의) 만으로 Dashboard를 구성하는 방법에 대해 살펴 보려고 합니다....


2016-09-14
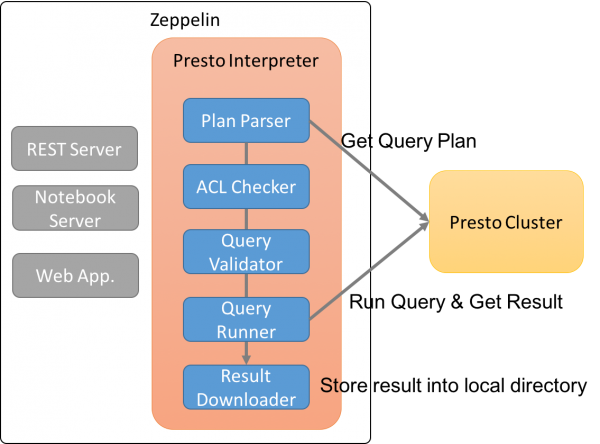
Presto의 Connector 기능을 이용하여 사용자 정의 함수를 만드는 방법을 소개합니다....

2016-08-26
Presto에서 제공하는 기본 Kafka Connector에서 Kafak의 Parrtition 정보를 이용하여 더 빠르게 질의를 수행할 수 있도록 어떻게 개선했는지 과정을 설명한다....

더보기