Time series OLAP – Druid 실시간 수집(2)

Druid 의 불꽃
전쟁의 서막을 못보셨다면 1편부터 시작 ^^ ::: Druid 입문
당신은 지체할 수도 있지만 시간은 그러지 않을 것이다.
- 벤자민 프랭클린
Druid에서 실시간 처리 방식에는 Stream Push방식과 Stream Pull방식이 있다.
[참고 : http://druid.io/docs/latest/ingestion/stream-ingestion.html]
실시간 처리 소개 전에 Indexing service에 대해 잠깐 짚고 넘어가자면 다음과 같다.
[참고 : http://druid.io/docs/latest/design/indexing-service.html ]

Druid의 indexing service는 위의 도식과 같이 세가지 컴포넌트로 구성된다.
1. Peon : 단일 jvm에서 수행되는 하나의 태스크를 말하며 Middle Manager에 의해 생성된다.
2: Middle Manager : 요청된 작업 분배 등의 Peon을 관리하는 역할을 수행한다.
3: Overload는 task의 분산을 관리하며 local또는 remote의 다수의Middle Manager를 구성할 수 있다.
indexing을 위해서는 Overlord node 를 통해 다음과 같은 URI에 수집 spec json을 포함하여 인덱싱 요청을 보낸다. 이때는 수집 대상 정보와 인덱싱을 위한 스키마 정보 등이 포함되며 수집 task가 생성된다.
http://<OVERLORD_IP>:<port>/druid/indexer/v1/task
Stream Push방식 (Tranquility)
- Tranquility(Druid-aware client)를 통해 데이터를 druid에 직접 적재 하는 방식을 말한다.
- Tranquility는 Druid의 실시간 인덱싱 task를 생성하고 partitioning 복제등을 다룰수 있다. 지정된 segment당 하나의 task를 수행하게 된다.
- Tranquility는 라이브러리 형태로 DruidBeams builder API를 이용하여 Spark/Storm/Samza/Flink 등에서 사용가능하다. 아래 도식은 kafka와 연동하여 실시간 데이터 처리를 모형화 한것이다.
- 필자의 경우 실시간 ingestion요건이 있었는데 이때 멀티 데이터 소스(hadoop, mysql)로부터 데이터를 추출하여 시간별 summary를 Druid에 적재를 해야 했다. (ex) O2O 시간대별 신규 사용자 유입 정보 및 캠페인 정보) 사용자 로그는 hadoop에 json형태의 format으로 적재되어 있으며 앞단에 log shipping (log 파일을 watch하고 offset을 관리하며 변경이 있을때마다 output으로 전달) 기술인 logstash(또는 fluentd)를 이용하여 kafka로 메시지를 전송한다. Spark Streaming은 다음과 같은 전처리를 위해 사용하였다. log 데이터에서 필요한 데이터를 추출할때 dataframe으로 nested json log data를 질의를 통해 추출하고 사용자 정보등이 포함된 mysql datasource를 join하여 연산하였다.
- 수집 단계에서 log파일과 db정보를 조인하여 처리할 수도 있겠지만 그렇게 되면 앞단 처리가 너무 무거워 진다. 수집기술(logstash, fluentd)은 간단한 log shipping만 하고 kafka 이후에 데이터를 필요로 하는 형태로 구현하였다.
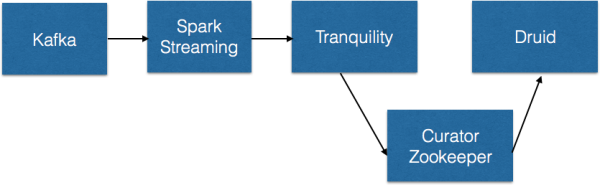
[참고 : https://github.com/druid-io/tranquility/blob/master/docs/spark.md ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37class SimpleEventBeamFactory extends BeamFactory[SimpleEvent] { // Return a singleton, so the same connection is shared across all tasks in the same JVM. def makeBeam: Beam[SimpleEvent] = SimpleEventBeamFactory.BeamInstance } object SimpleEventBeamFactory { val BeamInstance: Beam[SimpleEvent] = { // Tranquility uses ZooKeeper (through Curator framework) for coordination. val curator = CuratorFrameworkFactory.newClient( "localhost:2181", new BoundedExponentialBackoffRetry(100, 3000, 5) ) curator.start() val indexService = "druid/overlord" // Your overlord's druid.service, with slashes replaced by colons. val discoveryPath = "/druid/discovery" // Your overlord's druid.discovery.curator.path val dataSource = "foo" val dimensions = IndexedSeq("bar") val aggregators = Seq(new LongSumAggregatorFactory("baz", "baz")) // Expects simpleEvent.timestamp to return a Joda DateTime object. DruidBeams .builder((simpleEvent: SimpleEvent) => simpleEvent.timestamp) .curator(curator) .discoveryPath(discoveryPath) .location(DruidLocation(indexService, dataSource)) .rollup(DruidRollup(SpecificDruidDimensions(dimensions), aggregators, QueryGranularities.MINUTE)) .tuning( ClusteredBeamTuning( segmentGranularity = Granularity.HOUR, windowPeriod = new Period("PT10M"), partitions = 1, replicants = 1 ) ) .buildBeam() } }
Tranquility는 indexing service(Rest방식)과 다르게 zookeeper(여기서는 zookeeper client인 curator)를 통해 모든 task를 생성하고 관리한다. segmentGranularity는 각 task에 의해 생성되는 segment단위이며 위의 예에서는 HOUR기준으로 segment가 생성된다.
windowPeriod는 event에 허용된 여유시간이다. 여기서 10분은 10분동안 event를 listening하는 것이다.
새로운 task에 새로운 설정이 적용되더라도 schema evolution을 지원한다. 즉,segmentGranularity간격에서 시작될때 스키마 변경이 가능한것이다.
Stream Pull방식

무더위는 잠시 잊고 시원하게 firehose (출처 : http://steveholt.com/home/wp-content/uploads/2014/03/drink-out-of-a-hose.jpg)
- RealTime Node Ingestion방식으로 Firehose를 통해 연결하여 메시지를 가져오는 방식 (Kafka, RabbitMQ etc)이다.
- Pull방식으로 가져오기 위해서는 specFile을 생성해야 한다. 포맷은 다음과 같다. [참고 : http://druid.io/docs/latest/ingestion/stream-pull.html]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73[ { "dataSchema" : { "dataSource" : "wikipedia", "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "timestampSpec" : { "column" : "timestamp", "format" : "auto" }, "dimensionsSpec" : { "dimensions": ["page","language","user","unpatrolled","newPage","robot","anonymous","namespace","continent","country","region","city"], "dimensionExclusions" : [], "spatialDimensions" : [] } } }, "metricsSpec" : [{ "type" : "count", "name" : "count" }, { "type" : "doubleSum", "name" : "added", "fieldName" : "added" }, { "type" : "doubleSum", "name" : "deleted", "fieldName" : "deleted" }, { "type" : "doubleSum", "name" : "delta", "fieldName" : "delta" }], "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "DAY", "queryGranularity" : "NONE" } }, "ioConfig" : { "type" : "realtime", "firehose": { "type": "kafka-0.8", "consumerProps": { "zookeeper.connect": "localhost:2181", "zookeeper.connection.timeout.ms" : "15000", "zookeeper.session.timeout.ms" : "15000", "zookeeper.sync.time.ms" : "5000", "group.id": "druid-example", "fetch.message.max.bytes" : "1048586", "auto.offset.reset": "largest", "auto.commit.enable": "false" }, "feed": "wikipedia" }, "plumber": { "type": "realtime" } }, "tuningConfig": { "type" : "realtime", "maxRowsInMemory": 75000, "intermediatePersistPeriod": "PT10m", "windowPeriod": "PT10m", "basePersistDirectory": "\/tmp\/realtime\/basePersist", "rejectionPolicy": { "type": "serverTime" } } } ]
json으로 전달받은 데이터에 대한 추출 필드는 dimension에 기입한다. metric연산은 count등을 사용한다. Query granularity는 time dimension에 대한 aggregation 기준 단위이다. 위에는 none으로 작성되어 있으며 이 경우 millisecond를 의마한다.위의 설정은 kafka로 부터 데이터를 가져오는 spec이다. ioConfig에 kafka 연결정보를 작성하고 dimension metric을 정의한다. json format인 경우 현재 druid는 nested json을 지원하지 않는다. wikipedia의 경우 필요로 하는 정보로 가공하는 역할을 Decorder 에서 담당한다. 코드는 WikipediaIrcDecoder를 참고하면 된다.
다음은 위의 Kafka Ingestion을 도식화 한것이다.
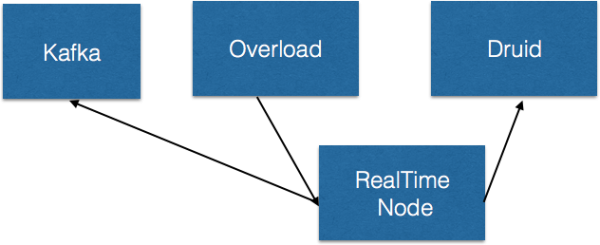
- Kafka에 정제된 message전송
- Overload에는 해당 Kafka의 Topic을 consume하는 Task생성
- RealTime Node에 ingestion 하여 적재
- segment 주기 단위로 segment를 Druid deep storage로 내림
이 경우 realtime node는 높은 수준의 Kafka consumer이다. 단일 task로 수행되며 kafka의 partition별 offset등을 지원하지 않아 간단한 수집의 경우가 아니라면 Tranquility를 사용하는것을 권장한다.
다음글에서는 배치 ingestion 에 대해 알아보자.
연재 순서는 : Druid 입문(1) -> 실시간 Ingestion(2) -> Batch Ingestion(3) -> Segment deep dive(4) -> Glue Architecture(5) -> Trouble Shooting(6)
TO BE CONTINUED