TIMESERIES-OLAP

2016-09-20
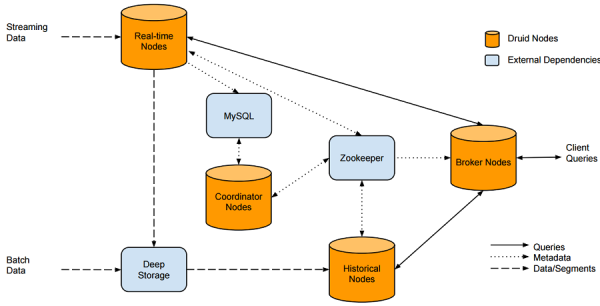
Druid - 어벤저스 계획을 세우지 못하는 것은 실패를 계획하는 것이다 - 에피존스 람다 아키텍처는 데이터 처리 아키텍처로 대용량 데이터에 대한 배치 처리와 스트림 처리 방법을 활용하여 처리하기 위해 설계된 데이터 프로세싱 아키텍처 이다. 아래의 아키텍처에서 수집된 레코드는...
2016-09-05
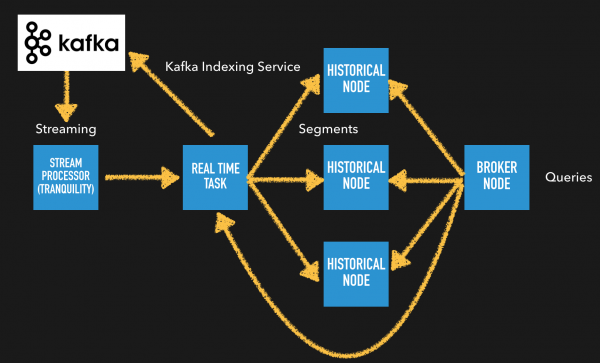
Druid의 저장 단위인 Segment와 Druid에서 지원하는 Query에 대해 다루려고 한다. Segment는 Druid의 time기준으로 저장되는 indexing 파일 단위를 의미하며 저장 단위는 사용자 쿼리에 따라 최적화가 가능하다....

2016-08-03
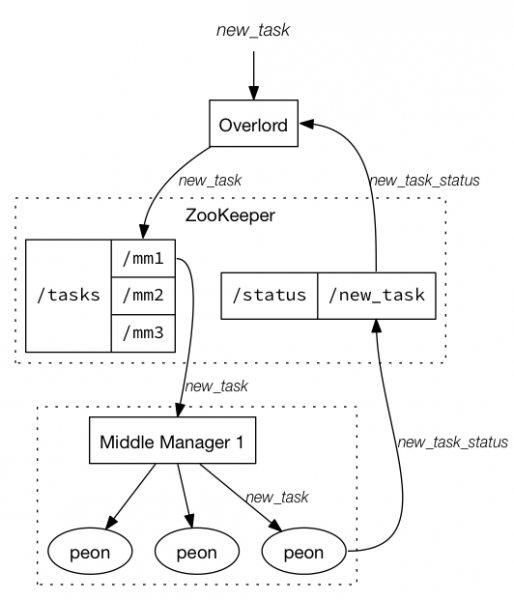
Druid 의 불꽃 전쟁의 서막을 못보셨다면 1편부터 시작 ^^ ::: Druid 입문 당신은 지체할 수도 있지만 시간은 그러지 않을 것이다. - 벤자민 프랭클린 Druid에서 실시간 처리 방식에는 Stream Push방식과 Stream Pull방식이 있다. [참고 : http://druid.io/docs/latest/ingestion/stream-ingestion.html ] 실시간 처리 소개 전에 Indexing service에 대해 잠깐 짚고 넘어가자면 다음과 같다. [참고 : http://druid.io/docs/latest/design/indexing-service.html ] Druid의 indexing service는 위의 도식과 같이 세가지 컴포넌트로 구성된다. 1. Peon : 단일 jvm에서 수행되는 하나의 태스크를 말하며 Middle Manager에 의해 생성된다. 2: Middle Manager : 요청된 작업 분배 등의 Peon을 관리하는 역할을 수행한다. 3: Overload는 task의 분산을 관리하며 local또는 remote의 다수의Middle Manager를 구성할 수 있다....
2016-08-01
Druid - 전쟁의 서막 때는 찬바람 불어 호빵을 호호 불며 우물거리던 작년 겨울 Business Problems 쉴틈도 없이 마구마구 뿜어내는 time series 데이터를 어떻게 효율적으로 처리할까라는 고민에서 시작되었다. 빅데이터에는 수많은 오픈소스 기술셋이 존재한다. 적합한 오픈소스는? [참고 : http://xyz.insightdataengineering.com/blog/pipeline_map.html ] Solution 비지니스 요건중에 time series 데이터에 대한 통계를 탄력적으로 처리(시간 단위 aggregation)할 수 있냐는 요건이 있었고...
더보기